 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransferable Ensemble Black-box Jailbreak Attacks on Large Language Models
Oct 31, 2024


In this report, we propose a novel black-box jailbreak attacking framework that incorporates various LLM-as-Attacker methods to deliver transferable and powerful jailbreak attacks. Our method is designed based on three key observations from existing jailbreaking studies and practices. First, we consider an ensemble approach should be more effective in exposing the vulnerabilities of an aligned LLM compared to individual attacks. Second, different malicious instructions inherently vary in their jailbreaking difficulty, necessitating differentiated treatment to ensure more efficient attacks. Finally, the semantic coherence of a malicious instruction is crucial for triggering the defenses of an aligned LLM; therefore, it must be carefully disrupted to manipulate its embedding representation, thereby increasing the jailbreak success rate. We validated our approach by participating in the Competition for LLM and Agent Safety 2024, where our team achieved top performance in the Jailbreaking Attack Track.
MMCert: Provable Defense against Adversarial Attacks to Multi-modal Models
Apr 02, 2024


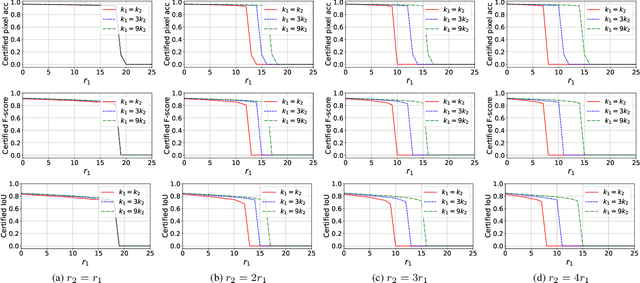
Different from a unimodal model whose input is from a single modality, the input (called multi-modal input) of a multi-modal model is from multiple modalities such as image, 3D points, audio, text, etc. Similar to unimodal models, many existing studies show that a multi-modal model is also vulnerable to adversarial perturbation, where an attacker could add small perturbation to all modalities of a multi-modal input such that the multi-modal model makes incorrect predictions for it. Existing certified defenses are mostly designed for unimodal models, which achieve sub-optimal certified robustness guarantees when extended to multi-modal models as shown in our experimental results. In our work, we propose MMCert, the first certified defense against adversarial attacks to a multi-modal model. We derive a lower bound on the performance of our MMCert under arbitrary adversarial attacks with bounded perturbations to both modalities (e.g., in the context of auto-driving, we bound the number of changed pixels in both RGB image and depth image). We evaluate our MMCert using two benchmark datasets: one for the multi-modal road segmentation task and the other for the multi-modal emotion recognition task. Moreover, we compare our MMCert with a state-of-the-art certified defense extended from unimodal models. Our experimental results show that our MMCert outperforms the baseline.