 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Critical Evaluation of Defenses against Prompt Injection Attacks
May 23, 2025Large Language Models (LLMs) are vulnerable to prompt injection attacks, and several defenses have recently been proposed, often claiming to mitigate these attacks successfully. However, we argue that existing studies lack a principled approach to evaluating these defenses. In this paper, we argue the need to assess defenses across two critical dimensions: (1) effectiveness, measured against both existing and adaptive prompt injection attacks involving diverse target and injected prompts, and (2) general-purpose utility, ensuring that the defense does not compromise the foundational capabilities of the LLM. Our critical evaluation reveals that prior studies have not followed such a comprehensive evaluation methodology. When assessed using this principled approach, we show that existing defenses are not as successful as previously reported. This work provides a foundation for evaluating future defenses and guiding their development. Our code and data are available at: https://github.com/PIEval123/PIEval.
DataSentinel: A Game-Theoretic Detection of Prompt Injection Attacks
Apr 15, 2025LLM-integrated applications and agents are vulnerable to prompt injection attacks, where an attacker injects prompts into their inputs to induce attacker-desired outputs. A detection method aims to determine whether a given input is contaminated by an injected prompt. However, existing detection methods have limited effectiveness against state-of-the-art attacks, let alone adaptive ones. In this work, we propose DataSentinel, a game-theoretic method to detect prompt injection attacks. Specifically, DataSentinel fine-tunes an LLM to detect inputs contaminated with injected prompts that are strategically adapted to evade detection. We formulate this as a minimax optimization problem, with the objective of fine-tuning the LLM to detect strong adaptive attacks. Furthermore, we propose a gradient-based method to solve the minimax optimization problem by alternating between the inner max and outer min problems. Our evaluation results on multiple benchmark datasets and LLMs show that DataSentinel effectively detects both existing and adaptive prompt injection attacks.
SecureGaze: Defending Gaze Estimation Against Backdoor Attacks
Feb 27, 2025



Gaze estimation models are widely used in applications such as driver attention monitoring and human-computer interaction. While many methods for gaze estimation exist, they rely heavily on data-hungry deep learning to achieve high performance. This reliance often forces practitioners to harvest training data from unverified public datasets, outsource model training, or rely on pre-trained models. However, such practices expose gaze estimation models to backdoor attacks. In such attacks, adversaries inject backdoor triggers by poisoning the training data, creating a backdoor vulnerability: the model performs normally with benign inputs, but produces manipulated gaze directions when a specific trigger is present. This compromises the security of many gaze-based applications, such as causing the model to fail in tracking the driver's attention. To date, there is no defense that addresses backdoor attacks on gaze estimation models. In response, we introduce SecureGaze, the first solution designed to protect gaze estimation models from such attacks. Unlike classification models, defending gaze estimation poses unique challenges due to its continuous output space and globally activated backdoor behavior. By identifying distinctive characteristics of backdoored gaze estimation models, we develop a novel and effective approach to reverse-engineer the trigger function for reliable backdoor detection. Extensive evaluations in both digital and physical worlds demonstrate that SecureGaze effectively counters a range of backdoor attacks and outperforms seven state-of-the-art defenses adapted from classification models.
TrojanDec: Data-free Detection of Trojan Inputs in Self-supervised Learning
Jan 07, 2025An image encoder pre-trained by self-supervised learning can be used as a general-purpose feature extractor to build downstream classifiers for various downstream tasks. However, many studies showed that an attacker can embed a trojan into an encoder such that multiple downstream classifiers built based on the trojaned encoder simultaneously inherit the trojan behavior. In this work, we propose TrojanDec, the first data-free method to identify and recover a test input embedded with a trigger. Given a (trojaned or clean) encoder and a test input, TrojanDec first predicts whether the test input is trojaned. If not, the test input is processed in a normal way to maintain the utility. Otherwise, the test input will be further restored to remove the trigger. Our extensive evaluation shows that TrojanDec can effectively identify the trojan (if any) from a given test input and recover it under state-of-the-art trojan attacks. We further demonstrate by experiments that our TrojanDec outperforms the state-of-the-art defenses.
Defending Deep Regression Models against Backdoor Attacks
Nov 07, 2024Deep regression models are used in a wide variety of safety-critical applications, but are vulnerable to backdoor attacks. Although many defenses have been proposed for classification models, they are ineffective as they do not consider the uniqueness of regression models. First, the outputs of regression models are continuous values instead of discretized labels. Thus, the potential infected target of a backdoored regression model has infinite possibilities, which makes it impossible to be determined by existing defenses. Second, the backdoor behavior of backdoored deep regression models is triggered by the activation values of all the neurons in the feature space, which makes it difficult to be detected and mitigated using existing defenses. To resolve these problems, we propose DRMGuard, the first defense to identify if a deep regression model in the image domain is backdoored or not. DRMGuard formulates the optimization problem for reverse engineering based on the unique output-space and feature-space characteristics of backdoored deep regression models. We conduct extensive evaluations on two regression tasks and four datasets. The results show that DRMGuard can consistently defend against various backdoor attacks. We also generalize four state-of-the-art defenses designed for classifiers to regression models, and compare DRMGuard with them. The results show that DRMGuard significantly outperforms all those defenses.
Prompt Injection Attacks and Defenses in LLM-Integrated Applications
Oct 19, 2023



Large Language Models (LLMs) are increasingly deployed as the backend for a variety of real-world applications called LLM-Integrated Applications. Multiple recent works showed that LLM-Integrated Applications are vulnerable to prompt injection attacks, in which an attacker injects malicious instruction/data into the input of those applications such that they produce results as the attacker desires. However, existing works are limited to case studies. As a result, the literature lacks a systematic understanding of prompt injection attacks and their defenses. We aim to bridge the gap in this work. In particular, we propose a general framework to formalize prompt injection attacks. Existing attacks, which are discussed in research papers and blog posts, are special cases in our framework. Our framework enables us to design a new attack by combining existing attacks. Moreover, we also propose a framework to systematize defenses against prompt injection attacks. Using our frameworks, we conduct a systematic evaluation on prompt injection attacks and their defenses with 10 LLMs and 7 tasks. We hope our frameworks can inspire future research in this field. Our code is available at https://github.com/liu00222/Open-Prompt-Injection.
PORE: Provably Robust Recommender Systems against Data Poisoning Attacks
Mar 26, 2023Data poisoning attacks spoof a recommender system to make arbitrary, attacker-desired recommendations via injecting fake users with carefully crafted rating scores into the recommender system. We envision a cat-and-mouse game for such data poisoning attacks and their defenses, i.e., new defenses are designed to defend against existing attacks and new attacks are designed to break them. To prevent such a cat-and-mouse game, we propose PORE, the first framework to build provably robust recommender systems in this work. PORE can transform any existing recommender system to be provably robust against any untargeted data poisoning attacks, which aim to reduce the overall performance of a recommender system. Suppose PORE recommends top-$N$ items to a user when there is no attack. We prove that PORE still recommends at least $r$ of the $N$ items to the user under any data poisoning attack, where $r$ is a function of the number of fake users in the attack. Moreover, we design an efficient algorithm to compute $r$ for each user. We empirically evaluate PORE on popular benchmark datasets.
StolenEncoder: Stealing Pre-trained Encoders
Jan 15, 2022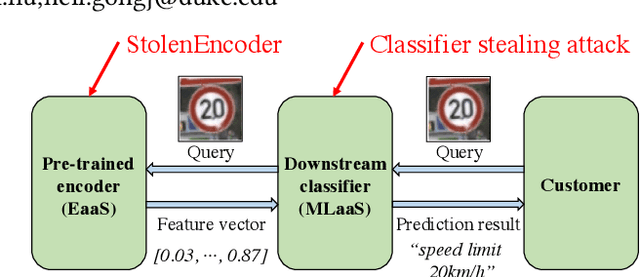



Pre-trained encoders are general-purpose feature extractors that can be used for many downstream tasks. Recent progress in self-supervised learning can pre-train highly effective encoders using a large volume of unlabeled data, leading to the emerging encoder as a service (EaaS). A pre-trained encoder may be deemed confidential because its training often requires lots of data and computation resources as well as its public release may facilitate misuse of AI, e.g., for deepfakes generation. In this paper, we propose the first attack called StolenEncoder to steal pre-trained image encoders. We evaluate StolenEncoder on multiple target encoders pre-trained by ourselves and three real-world target encoders including the ImageNet encoder pre-trained by Google, CLIP encoder pre-trained by OpenAI, and Clarifai's General Embedding encoder deployed as a paid EaaS. Our results show that the encoders stolen by StolenEncoder have similar functionality with the target encoders. In particular, the downstream classifiers built upon a target encoder and a stolen encoder have similar accuracy. Moreover, stealing a target encoder using StolenEncoder requires much less data and computation resources than pre-training it from scratch. We also explore three defenses that perturb feature vectors produced by a target encoder. Our evaluation shows that these defenses are not enough to mitigate StolenEncoder.
BadEncoder: Backdoor Attacks to Pre-trained Encoders in Self-Supervised Learning
Aug 01, 2021



Self-supervised learning in computer vision aims to pre-train an image encoder using a large amount of unlabeled images or (image, text) pairs. The pre-trained image encoder can then be used as a feature extractor to build downstream classifiers for many downstream tasks with a small amount of or no labeled training data. In this work, we propose BadEncoder, the first backdoor attack to self-supervised learning. In particular, our BadEncoder injects backdoors into a pre-trained image encoder such that the downstream classifiers built based on the backdoored image encoder for different downstream tasks simultaneously inherit the backdoor behavior. We formulate our BadEncoder as an optimization problem and we propose a gradient descent based method to solve it, which produces a backdoored image encoder from a clean one. Our extensive empirical evaluation results on multiple datasets show that our BadEncoder achieves high attack success rates while preserving the accuracy of the downstream classifiers. We also show the effectiveness of BadEncoder using two publicly available, real-world image encoders, i.e., Google's image encoder pre-trained on ImageNet and OpenAI's Contrastive Language-Image Pre-training (CLIP) image encoder pre-trained on 400 million (image, text) pairs collected from the Internet. Moreover, we consider defenses including Neural Cleanse and MNTD (empirical defenses) as well as PatchGuard (a provable defense). Our results show that these defenses are insufficient to defend against BadEncoder, highlighting the needs for new defenses against our BadEncoder. Our code is publicly available at: https://github.com/jjy1994/BadEncoder.
Security Analysis of Camera-LiDAR Semantic-Level Fusion Against Black-Box Attacks on Autonomous Vehicles
Jun 29, 2021



To enable safe and reliable decision-making, autonomous vehicles (AVs) feed sensor data to perception algorithms to understand the environment. Sensor fusion, and particularly semantic fusion, with multi-frame tracking is becoming increasingly popular for detecting 3D objects. Recently, it was shown that LiDAR-based perception built on deep neural networks is vulnerable to LiDAR spoofing attacks. Thus, in this work, we perform the first analysis of camera-LiDAR fusion under spoofing attacks and the first security analysis of semantic fusion in any AV context. We find first that fusion is more successful than existing defenses at guarding against naive spoofing. However, we then define the frustum attack as a new class of attacks on AVs and find that semantic camera-LiDAR fusion exhibits widespread vulnerability to frustum attacks with between 70% and 90% success against target models. Importantly, the attacker needs less than 20 random spoof points on average for successful attacks - an order of magnitude less than established maximum capability. Finally, we are the first to analyze the longitudinal impact of perception attacks by showing the impact of multi-frame attacks.