 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Datasets for Multi-Sensor, Multi-Agent, and Multi-Domain Learning in Autonomous Systems
Jun 03, 2026Existing datasets cannot support large-scale learning in multi-agent, multi-sensor, or multi-domain autonomy, where diversity and coordination are essential. We present a modular dataset generation pipeline that creates terabyte-scale, ground-truth-labeled data for ground, aerial, and infrastructure-based systems using the AVstack framework and CARLA simulator. Supporting single- and multi-agent configurations with flexible sensor suites, the pipeline enables controllable experimentation across challenging conditions. Representative perception and fusion studies show how generated data can support application-specific training and collaborative autonomy.
Assured Autonomy with Neuro-Symbolic Perception
May 27, 2025Many state-of-the-art AI models deployed in cyber-physical systems (CPS), while highly accurate, are simply pattern-matchers.~With limited security guarantees, there are concerns for their reliability in safety-critical and contested domains. To advance assured AI, we advocate for a paradigm shift that imbues data-driven perception models with symbolic structure, inspired by a human's ability to reason over low-level features and high-level context. We propose a neuro-symbolic paradigm for perception (NeuSPaPer) and illustrate how joint object detection and scene graph generation (SGG) yields deep scene understanding.~Powered by foundation models for offline knowledge extraction and specialized SGG algorithms for real-time deployment, we design a framework leveraging structured relational graphs that ensures the integrity of situational awareness in autonomy. Using physics-based simulators and real-world datasets, we demonstrate how SGG bridges the gap between low-level sensor perception and high-level reasoning, establishing a foundation for resilient, context-aware AI and advancing trusted autonomy in CPS.
Probabilistic Segmentation for Robust Field of View Estimation
Mar 10, 2025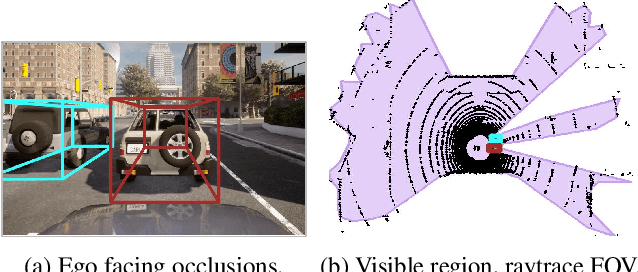
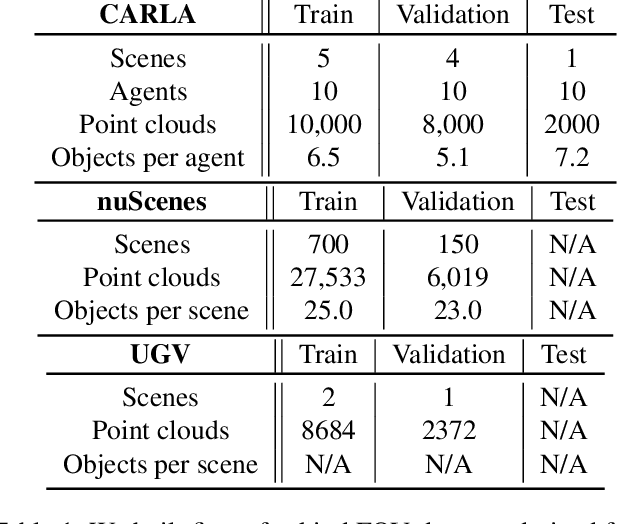
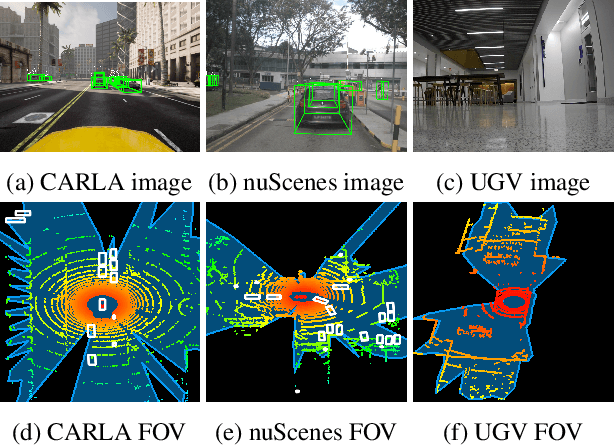
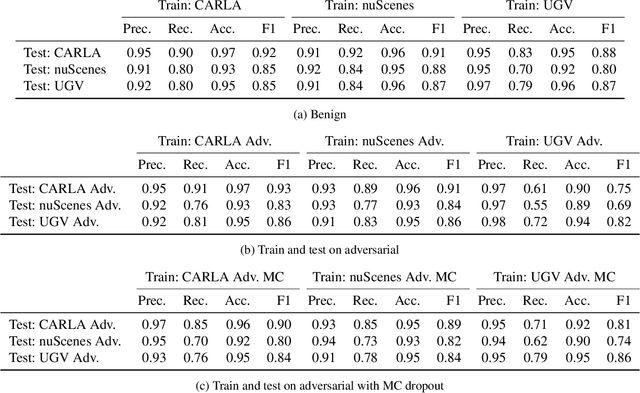
Attacks on sensing and perception threaten the safe deployment of autonomous vehicles (AVs). Security-aware sensor fusion helps mitigate threats but requires accurate field of view (FOV) estimation which has not been evaluated autonomy. To address this gap, we adapt classical computer graphics algorithms to develop the first autonomy-relevant FOV estimators and create the first datasets with ground truth FOV labels. Unfortunately, we find that these approaches are themselves highly vulnerable to attacks on sensing. To improve robustness of FOV estimation against attacks, we propose a learning-based segmentation model that captures FOV features, integrates Monte Carlo dropout (MCD) for uncertainty quantification, and performs anomaly detection on confidence maps. We illustrate through comprehensive evaluations attack resistance and strong generalization across environments. Architecture trade studies demonstrate the model is feasible for real-time deployment in multiple applications.
Bayesian Methods for Trust in Collaborative Multi-Agent Autonomy
Mar 25, 2024



Multi-agent, collaborative sensor fusion is a vital component of a multi-national intelligence toolkit. In safety-critical and/or contested environments, adversaries may infiltrate and compromise a number of agents. We analyze state of the art multi-target tracking algorithms under this compromised agent threat model. We prove that the track existence probability test ("track score") is significantly vulnerable to even small numbers of adversaries. To add security awareness, we design a trust estimation framework using hierarchical Bayesian updating. Our framework builds beliefs of trust on tracks and agents by mapping sensor measurements to trust pseudomeasurements (PSMs) and incorporating prior trust beliefs in a Bayesian context. In case studies, our trust estimation algorithm accurately estimates the trustworthiness of tracks/agents, subject to observability limitations.
A Multi-Agent Security Testbed for the Analysis of Attacks and Defenses in Collaborative Sensor Fusion
Jan 17, 2024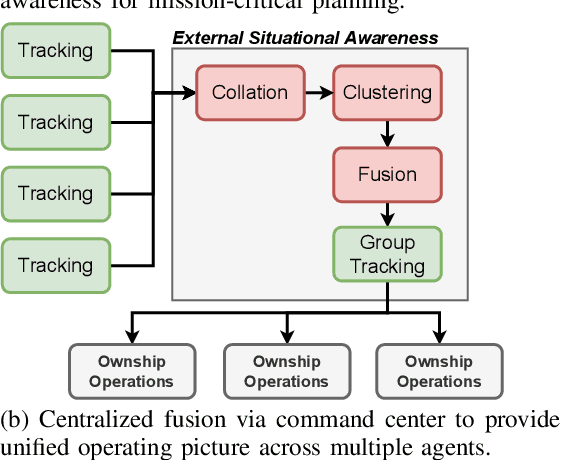
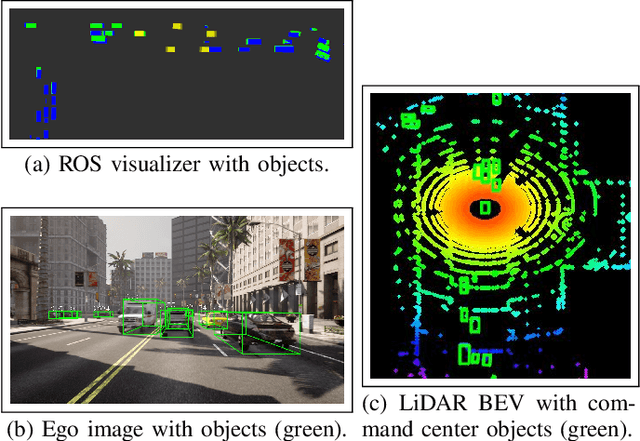
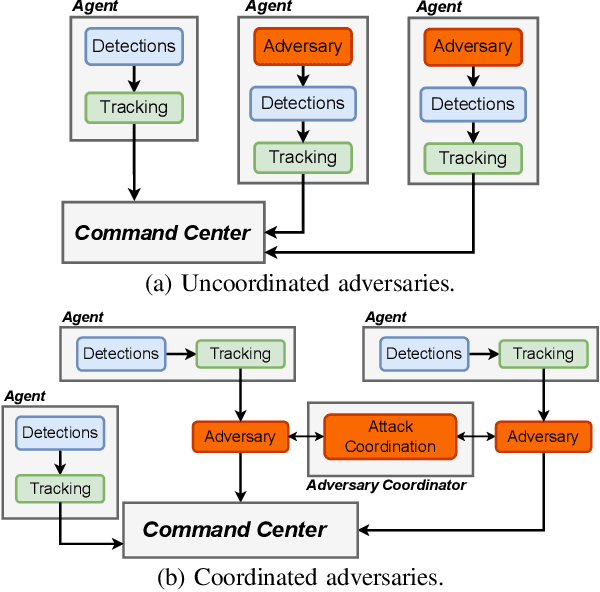
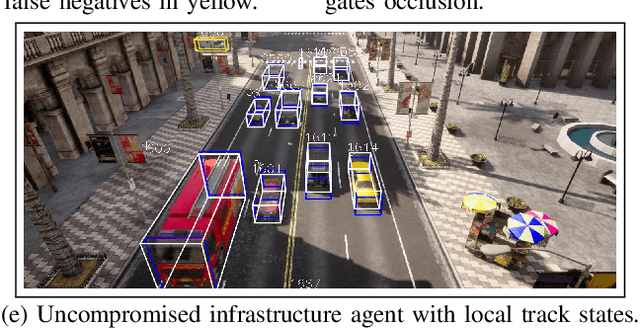
The performance and safety of autonomous vehicles (AVs) deteriorates under adverse environments and adversarial actors. The investment in multi-sensor, multi-agent (MSMA) AVs is meant to promote improved efficiency of travel and mitigate safety risks. Unfortunately, minimal investment has been made to develop security-aware MSMA sensor fusion pipelines leaving them vulnerable to adversaries. To advance security analysis of AVs, we develop the Multi-Agent Security Testbed, MAST, in the Robot Operating System (ROS2). Our framework is scalable for general AV scenarios and is integrated with recent multi-agent datasets. We construct the first bridge between AVstack and ROS and develop automated AV pipeline builds to enable rapid AV prototyping. We tackle the challenge of deploying variable numbers of agent/adversary nodes at launch-time with dynamic topic remapping. Using this testbed, we motivate the need for security-aware AV architectures by exposing the vulnerability of centralized multi-agent fusion pipelines to (un)coordinated adversary models in case studies and Monte Carlo analysis.
Datasets, Models, and Algorithms for Multi-Sensor, Multi-agent Autonomy Using AVstack
Dec 08, 2023



Recent advancements in assured autonomy have brought autonomous vehicles (AVs) closer to fruition. Despite strong evidence that multi-sensor, multi-agent (MSMA) systems can yield substantial improvements in the safety and security of AVs, there exists no unified framework for developing and testing representative MSMA configurations. Using the recently-released autonomy platform, AVstack, this work proposes a new framework for datasets, models, and algorithms in MSMA autonomy. Instead of releasing a single dataset, we deploy a dataset generation pipeline capable of generating unlimited volumes of ground-truth-labeled MSMA perception data. The data derive from cameras (semantic segmentation, RGB, depth), LiDAR, and radar, and are sourced from ground-vehicles and, for the first time, infrastructure platforms. Pipelining generating labeled MSMA data along with AVstack's third-party integrations defines a model training framework that allows training multi-sensor perception for vehicle and infrastructure applications. We provide the framework and pretrained models open-source. Finally, the dataset and model training pipelines culminate in insightful multi-agent case studies. While previous works used specific ego-centric multi-agent designs, our framework considers the collaborative autonomy space as a network of noisy, time-correlated sensors. Within this environment, we quantify the impact of the network topology and data fusion pipeline on an agent's situational awareness.
A Modular Platform For Collaborative, Distributed Sensor Fusion
Mar 29, 2023

Leading autonomous vehicle (AV) platforms and testing infrastructures are, unfortunately, proprietary and closed-source. Thus, it is difficult to evaluate how well safety-critical AVs perform and how safe they truly are. Similarly, few platforms exist for much-needed multi-agent analysis. To provide a starting point for analysis of sensor fusion and collaborative & distributed sensing, we design an accessible, modular sensing platform with AVstack. We build collaborative and distributed camera-radar fusion algorithms and demonstrate an evaluation ecosystem of AV datasets, physics-based simulators, and hardware in the physical world. This three-part ecosystem enables testing next-generation configurations that are prohibitively challenging in existing development platforms.
AVstack: An Open-Source, Reconfigurable Platform for Autonomous Vehicle Development
Dec 28, 2022



Pioneers of autonomous vehicles (AVs) promised to revolutionize the driving experience and driving safety. However, milestones in AVs have materialized slower than forecast. Two culprits are (1) the lack of verifiability of proposed state-of-the-art AV components, and (2) stagnation of pursuing next-level evaluations, e.g., vehicle-to-infrastructure (V2I) and multi-agent collaboration. In part, progress has been hampered by: the large volume of software in AVs, the multiple disparate conventions, the difficulty of testing across datasets and simulators, and the inflexibility of state-of-the-art AV components. To address these challenges, we present AVstack, an open-source, reconfigurable software platform for AV design, implementation, test, and analysis. AVstack solves the validation problem by enabling first-of-a-kind trade studies on datasets and physics-based simulators. AVstack solves the stagnation problem as a reconfigurable AV platform built on dozens of open-source AV components in a high-level programming language. We demonstrate the power of AVstack through longitudinal testing across multiple benchmark datasets and V2I-collaboration case studies that explore trade-offs of designing multi-sensor, multi-agent algorithms.
Security Analysis of Camera-LiDAR Semantic-Level Fusion Against Black-Box Attacks on Autonomous Vehicles
Jun 29, 2021



To enable safe and reliable decision-making, autonomous vehicles (AVs) feed sensor data to perception algorithms to understand the environment. Sensor fusion, and particularly semantic fusion, with multi-frame tracking is becoming increasingly popular for detecting 3D objects. Recently, it was shown that LiDAR-based perception built on deep neural networks is vulnerable to LiDAR spoofing attacks. Thus, in this work, we perform the first analysis of camera-LiDAR fusion under spoofing attacks and the first security analysis of semantic fusion in any AV context. We find first that fusion is more successful than existing defenses at guarding against naive spoofing. However, we then define the frustum attack as a new class of attacks on AVs and find that semantic camera-LiDAR fusion exhibits widespread vulnerability to frustum attacks with between 70% and 90% success against target models. Importantly, the attacker needs less than 20 random spoof points on average for successful attacks - an order of magnitude less than established maximum capability. Finally, we are the first to analyze the longitudinal impact of perception attacks by showing the impact of multi-frame attacks.