 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeave My Images Alone: Preventing Multi-Modal Large Language Models from Analyzing Images via Visual Prompt Injection
Apr 10, 2026Multi-modal large language models (MLLMs) have emerged as powerful tools for analyzing Internet-scale image data, offering significant benefits but also raising critical safety and societal concerns. In particular, open-weight MLLMs may be misused to extract sensitive information from personal images at scale, such as identities, locations, or other private details. In this work, we propose ImageProtector, a user-side method that proactively protects images before sharing by embedding a carefully crafted, nearly imperceptible perturbation that acts as a visual prompt injection attack on MLLMs. As a result, when an adversary analyzes a protected image with an MLLM, the MLLM is consistently induced to generate a refusal response such as "I'm sorry, I can't help with that request." We empirically demonstrate the effectiveness of ImageProtector across six MLLMs and four datasets. Additionally, we evaluate three potential countermeasures, Gaussian noise, DiffPure, and adversarial training, and show that while they partially mitigate the impact of ImageProtector, they simultaneously degrade model accuracy and/or efficiency. Our study focuses on the practically important setting of open-weight MLLMs and large-scale automated image analysis, and highlights both the promise and the limitations of perturbation-based privacy protection.
* Appeared in ACL 2026 main conference
VideoMarkBench: Benchmarking Robustness of Video Watermarking
May 27, 2025The rapid development of video generative models has led to a surge in highly realistic synthetic videos, raising ethical concerns related to disinformation and copyright infringement. Recently, video watermarking has been proposed as a mitigation strategy by embedding invisible marks into AI-generated videos to enable subsequent detection. However, the robustness of existing video watermarking methods against both common and adversarial perturbations remains underexplored. In this work, we introduce VideoMarkBench, the first systematic benchmark designed to evaluate the robustness of video watermarks under watermark removal and watermark forgery attacks. Our study encompasses a unified dataset generated by three state-of-the-art video generative models, across three video styles, incorporating four watermarking methods and seven aggregation strategies used during detection. We comprehensively evaluate 12 types of perturbations under white-box, black-box, and no-box threat models. Our findings reveal significant vulnerabilities in current watermarking approaches and highlight the urgent need for more robust solutions. Our code is available at https://github.com/zhengyuan-jiang/VideoMarkBench.
EnvInjection: Environmental Prompt Injection Attack to Multi-modal Web Agents
May 16, 2025Multi-modal large language model (MLLM)-based web agents interact with webpage environments by generating actions based on screenshots of the webpages. Environmental prompt injection attacks manipulate the environment to induce the web agent to perform a specific, attacker-chosen action--referred to as the target action. However, existing attacks suffer from limited effectiveness or stealthiness, or are impractical in real-world settings. In this work, we propose EnvInjection, a new attack that addresses these limitations. Our attack adds a perturbation to the raw pixel values of the rendered webpage, which can be implemented by modifying the webpage's source code. After these perturbed pixels are mapped into a screenshot, the perturbation induces the web agent to perform the target action. We formulate the task of finding the perturbation as an optimization problem. A key challenge in solving this problem is that the mapping between raw pixel values and screenshot is non-differentiable, making it difficult to backpropagate gradients to the perturbation. To overcome this, we train a neural network to approximate the mapping and apply projected gradient descent to solve the reformulated optimization problem. Extensive evaluation on multiple webpage datasets shows that EnvInjection is highly effective and significantly outperforms existing baselines.
Zero-shot Autonomous Microscopy for Scalable and Intelligent Characterization of 2D Materials
Apr 14, 2025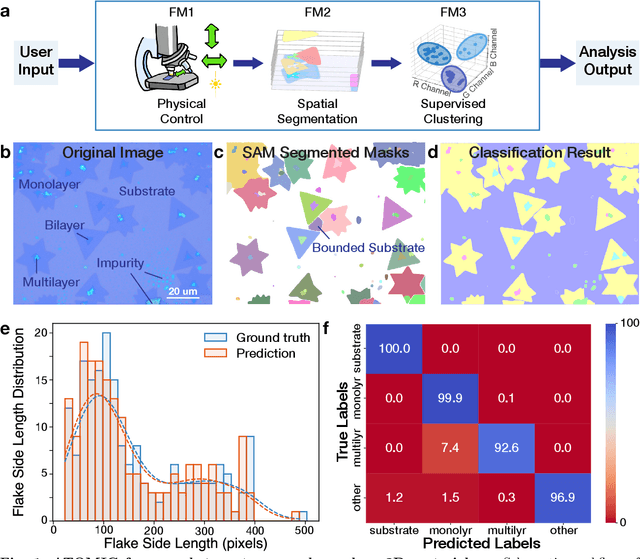
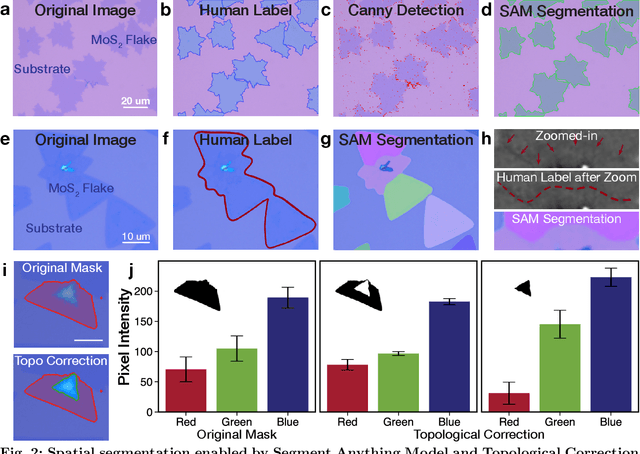
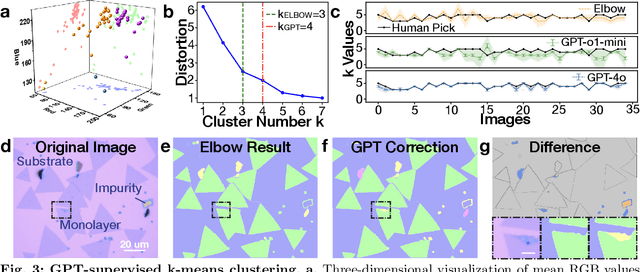
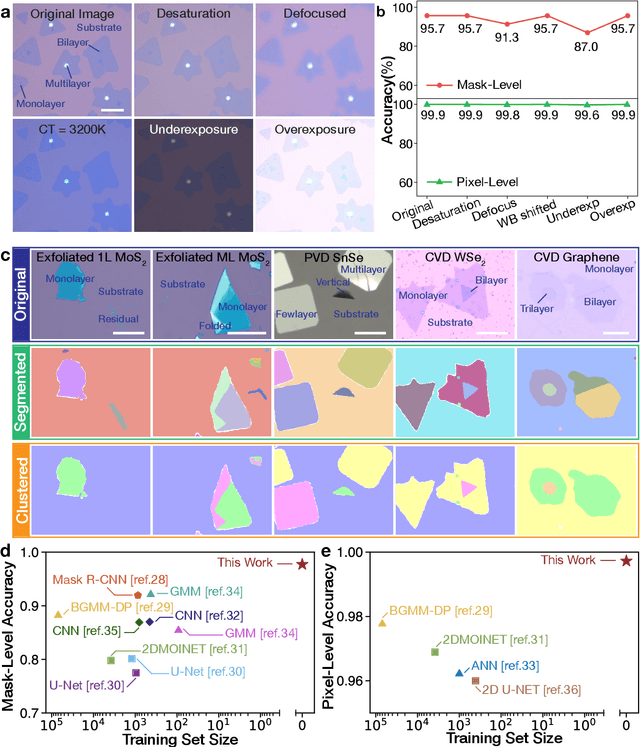
Characterization of atomic-scale materials traditionally requires human experts with months to years of specialized training. Even for trained human operators, accurate and reliable characterization remains challenging when examining newly discovered materials such as two-dimensional (2D) structures. This bottleneck drives demand for fully autonomous experimentation systems capable of comprehending research objectives without requiring large training datasets. In this work, we present ATOMIC (Autonomous Technology for Optical Microscopy & Intelligent Characterization), an end-to-end framework that integrates foundation models to enable fully autonomous, zero-shot characterization of 2D materials. Our system integrates the vision foundation model (i.e., Segment Anything Model), large language models (i.e., ChatGPT), unsupervised clustering, and topological analysis to automate microscope control, sample scanning, image segmentation, and intelligent analysis through prompt engineering, eliminating the need for additional training. When analyzing typical MoS2 samples, our approach achieves 99.7% segmentation accuracy for single layer identification, which is equivalent to that of human experts. In addition, the integrated model is able to detect grain boundary slits that are challenging to identify with human eyes. Furthermore, the system retains robust accuracy despite variable conditions including defocus, color temperature fluctuations, and exposure variations. It is applicable to a broad spectrum of common 2D materials-including graphene, MoS2, WSe2, SnSe-regardless of whether they were fabricated via chemical vapor deposition or mechanical exfoliation. This work represents the implementation of foundation models to achieve autonomous analysis, establishing a scalable and data-efficient characterization paradigm that fundamentally transforms the approach to nanoscale materials research.
Jailbreaking Safeguarded Text-to-Image Models via Large Language Models
Mar 03, 2025



Text-to-Image models may generate harmful content, such as pornographic images, particularly when unsafe prompts are submitted. To address this issue, safety filters are often added on top of text-to-image models, or the models themselves are aligned to reduce harmful outputs. However, these defenses remain vulnerable when an attacker strategically designs adversarial prompts to bypass these safety guardrails. In this work, we propose PromptTune, a method to jailbreak text-to-image models with safety guardrails using a fine-tuned large language model. Unlike other query-based jailbreak attacks that require repeated queries to the target model, our attack generates adversarial prompts efficiently after fine-tuning our AttackLLM. We evaluate our method on three datasets of unsafe prompts and against five safety guardrails. Our results demonstrate that our approach effectively bypasses safety guardrails, outperforms existing no-box attacks, and also facilitates other query-based attacks.
SafeText: Safe Text-to-image Models via Aligning the Text Encoder
Feb 28, 2025Text-to-image models can generate harmful images when presented with unsafe prompts, posing significant safety and societal risks. Alignment methods aim to modify these models to ensure they generate only non-harmful images, even when exposed to unsafe prompts. A typical text-to-image model comprises two main components: 1) a text encoder and 2) a diffusion module. Existing alignment methods mainly focus on modifying the diffusion module to prevent harmful image generation. However, this often significantly impacts the model's behavior for safe prompts, causing substantial quality degradation of generated images. In this work, we propose SafeText, a novel alignment method that fine-tunes the text encoder rather than the diffusion module. By adjusting the text encoder, SafeText significantly alters the embedding vectors for unsafe prompts, while minimally affecting those for safe prompts. As a result, the diffusion module generates non-harmful images for unsafe prompts while preserving the quality of images for safe prompts. We evaluate SafeText on multiple datasets of safe and unsafe prompts, including those generated through jailbreak attacks. Our results show that SafeText effectively prevents harmful image generation with minor impact on the images for safe prompts, and SafeText outperforms six existing alignment methods. We will publish our code and data after paper acceptance.
AI-generated Image Detection: Passive or Watermark?
Nov 20, 2024


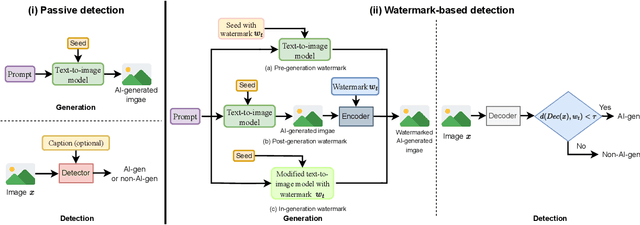
While text-to-image models offer numerous benefits, they also pose significant societal risks. Detecting AI-generated images is crucial for mitigating these risks. Detection methods can be broadly categorized into passive and watermark-based approaches: passive detectors rely on artifacts present in AI-generated images, whereas watermark-based detectors proactively embed watermarks into such images. A key question is which type of detector performs better in terms of effectiveness, robustness, and efficiency. However, the current literature lacks a comprehensive understanding of this issue. In this work, we aim to bridge that gap by developing ImageDetectBench, the first comprehensive benchmark to compare the effectiveness, robustness, and efficiency of passive and watermark-based detectors. Our benchmark includes four datasets, each containing a mix of AI-generated and non-AI-generated images. We evaluate five passive detectors and four watermark-based detectors against eight types of common perturbations and three types of adversarial perturbations. Our benchmark results reveal several interesting findings. For instance, watermark-based detectors consistently outperform passive detectors, both in the presence and absence of perturbations. Based on these insights, we provide recommendations for detecting AI-generated images, e.g., when both types of detectors are applicable, watermark-based detectors should be the preferred choice.
Automatically Generating Visual Hallucination Test Cases for Multimodal Large Language Models
Oct 15, 2024Visual hallucination (VH) occurs when a multimodal large language model (MLLM) generates responses with incorrect visual details for prompts. Existing methods for generating VH test cases primarily rely on human annotations, typically in the form of triples: (image, question, answer). In this paper, we introduce VHExpansion, the first automated method for expanding VH test cases for MLLMs. Given an initial VH test case, VHExpansion automatically expands it by perturbing the question and answer through negation as well as modifying the image using both common and adversarial perturbations. Additionally, we propose a new evaluation metric, symmetric accuracy, which measures the proportion of correctly answered VH test-case pairs. Each pair consists of a test case and its negated counterpart. Our theoretical analysis shows that symmetric accuracy is an unbiased evaluation metric that remains unaffected by the imbalance of VH testing cases with varying answers when an MLLM is randomly guessing the answers, whereas traditional accuracy is prone to such imbalance. We apply VHExpansion to expand three VH datasets annotated manually and use these expanded datasets to benchmark seven MLLMs. Our evaluation shows that VHExpansion effectively identifies more VH test cases. Moreover, symmetric accuracy, being unbiased, leads to different conclusions about the vulnerability of MLLMs to VH compared to traditional accuracy metric. Finally, we show that fine-tuning MLLMs on the expanded VH dataset generated by VHExpansion mitigates VH more effectively than fine-tuning on the original, manually annotated dataset. Our code is available at: https://github.com/lycheeefish/VHExpansion.
Refusing Safe Prompts for Multi-modal Large Language Models
Jul 12, 2024Multimodal large language models (MLLMs) have become the cornerstone of today's generative AI ecosystem, sparking intense competition among tech giants and startups. In particular, an MLLM generates a text response given a prompt consisting of an image and a question. While state-of-the-art MLLMs use safety filters and alignment techniques to refuse unsafe prompts, in this work, we introduce MLLM-Refusal, the first method that induces refusals for safe prompts. In particular, our MLLM-Refusal optimizes a nearly-imperceptible refusal perturbation and adds it to an image, causing target MLLMs to likely refuse a safe prompt containing the perturbed image and a safe question. Specifically, we formulate MLLM-Refusal as a constrained optimization problem and propose an algorithm to solve it. Our method offers competitive advantages for MLLM model providers by potentially disrupting user experiences of competing MLLMs, since competing MLLM's users will receive unexpected refusals when they unwittingly use these perturbed images in their prompts. We evaluate MLLM-Refusal on four MLLMs across four datasets, demonstrating its effectiveness in causing competing MLLMs to refuse safe prompts while not affecting non-competing MLLMs. Furthermore, we explore three potential countermeasures -- adding Gaussian noise, DiffPure, and adversarial training. Our results show that they are insufficient: though they can mitigate MLLM-Refusal's effectiveness, they also sacrifice the accuracy and/or efficiency of the competing MLLM. The code is available at https://github.com/Sadcardation/MLLM-Refusal.
Certifiably Robust Image Watermark
Jul 04, 2024Generative AI raises many societal concerns such as boosting disinformation and propaganda campaigns. Watermarking AI-generated content is a key technology to address these concerns and has been widely deployed in industry. However, watermarking is vulnerable to removal attacks and forgery attacks. In this work, we propose the first image watermarks with certified robustness guarantees against removal and forgery attacks. Our method leverages randomized smoothing, a popular technique to build certifiably robust classifiers and regression models. Our major technical contributions include extending randomized smoothing to watermarking by considering its unique characteristics, deriving the certified robustness guarantees, and designing algorithms to estimate them. Moreover, we extensively evaluate our image watermarks in terms of both certified and empirical robustness. Our code is available at \url{https://github.com/zhengyuan-jiang/Watermark-Library}.