 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-shot Autonomous Microscopy for Scalable and Intelligent Characterization of 2D Materials
Apr 14, 2025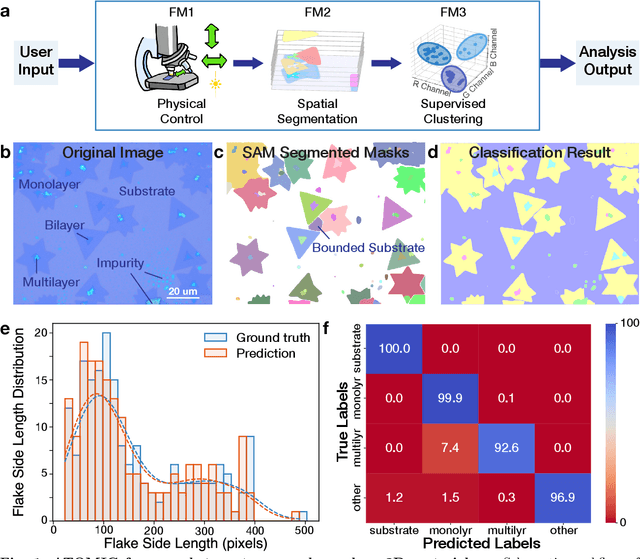
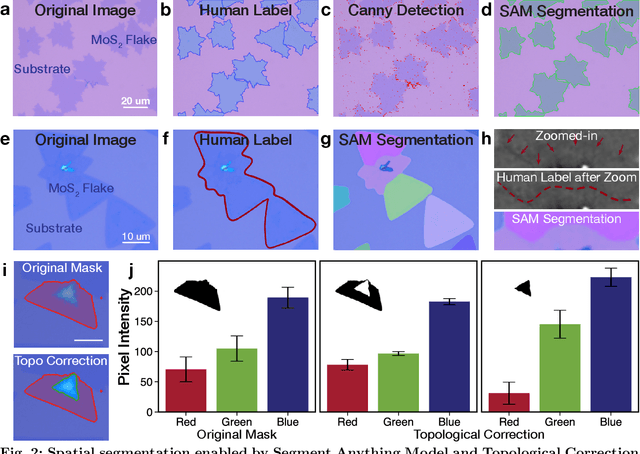
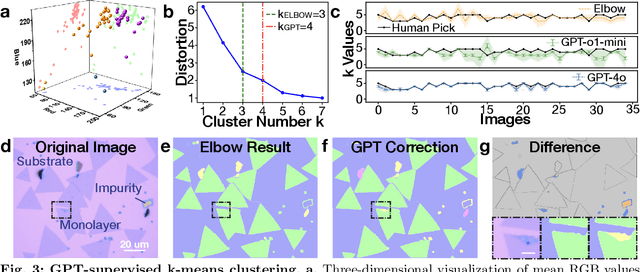
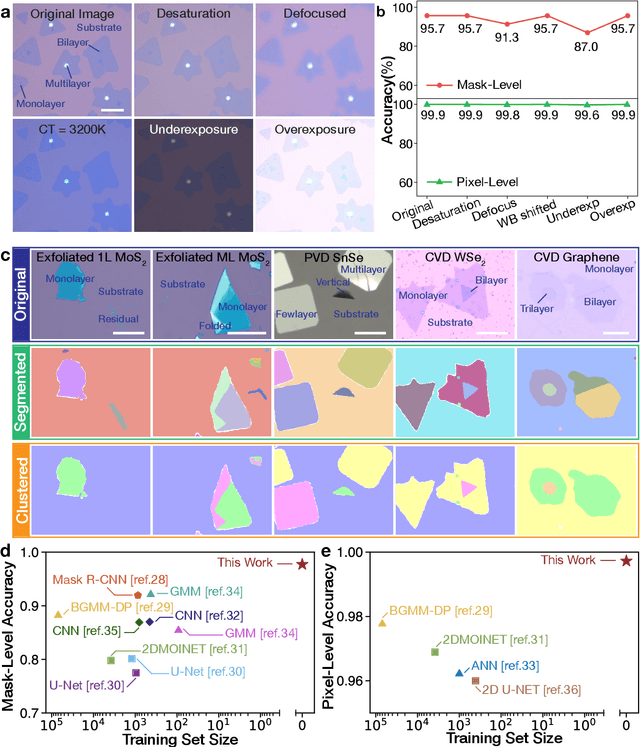
Characterization of atomic-scale materials traditionally requires human experts with months to years of specialized training. Even for trained human operators, accurate and reliable characterization remains challenging when examining newly discovered materials such as two-dimensional (2D) structures. This bottleneck drives demand for fully autonomous experimentation systems capable of comprehending research objectives without requiring large training datasets. In this work, we present ATOMIC (Autonomous Technology for Optical Microscopy & Intelligent Characterization), an end-to-end framework that integrates foundation models to enable fully autonomous, zero-shot characterization of 2D materials. Our system integrates the vision foundation model (i.e., Segment Anything Model), large language models (i.e., ChatGPT), unsupervised clustering, and topological analysis to automate microscope control, sample scanning, image segmentation, and intelligent analysis through prompt engineering, eliminating the need for additional training. When analyzing typical MoS2 samples, our approach achieves 99.7% segmentation accuracy for single layer identification, which is equivalent to that of human experts. In addition, the integrated model is able to detect grain boundary slits that are challenging to identify with human eyes. Furthermore, the system retains robust accuracy despite variable conditions including defocus, color temperature fluctuations, and exposure variations. It is applicable to a broad spectrum of common 2D materials-including graphene, MoS2, WSe2, SnSe-regardless of whether they were fabricated via chemical vapor deposition or mechanical exfoliation. This work represents the implementation of foundation models to achieve autonomous analysis, establishing a scalable and data-efficient characterization paradigm that fundamentally transforms the approach to nanoscale materials research.
SketchRef: A Benchmark Dataset and Evaluation Metrics for Automated Sketch Synthesis
Aug 16, 2024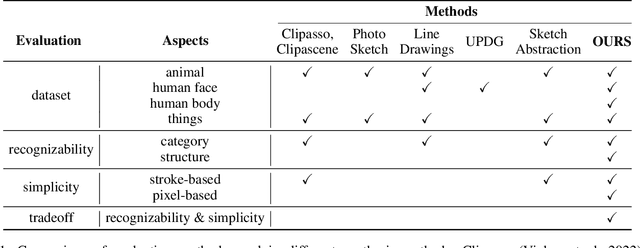
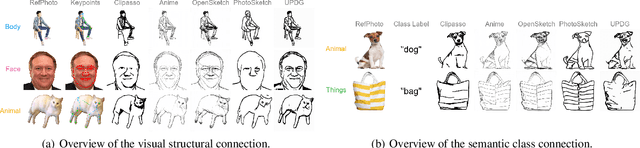
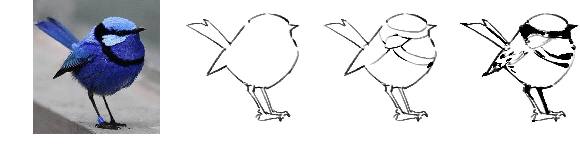

Sketch, a powerful artistic technique to capture essential visual information about real-world objects, is increasingly gaining attention in the image synthesis field. However, evaluating the quality of synthesized sketches presents unique unsolved challenges. Current evaluation methods for sketch synthesis are inadequate due to the lack of a unified benchmark dataset, over-reliance on classification accuracy for recognizability, and unfair evaluation of sketches with different levels of simplification. To address these issues, we introduce SketchRef, a benchmark dataset comprising 4 categories of reference photos--animals, human faces, human bodies, and common objects--alongside novel evaluation metrics. Considering that classification accuracy is insufficient to measure the structural consistency between a sketch and its reference photo, we propose the mean Object Keypoint Similarity (mOKS) metric, utilizing pose estimation to assess structure-level recognizability. To ensure fair evaluation sketches with different simplification levels, we propose a recognizability calculation method constrained by simplicity. We also collect 8K responses from art enthusiasts, validating the effectiveness of our proposed evaluation methods. We hope this work can provide a comprehensive evaluation of sketch synthesis algorithms, thereby aligning their performance more closely with human understanding.
TAMER: Tree-Aware Transformer for Handwritten Mathematical Expression Recognition
Aug 16, 2024



Handwritten Mathematical Expression Recognition (HMER) has extensive applications in automated grading and office automation. However, existing sequence-based decoding methods, which directly predict $\LaTeX$ sequences, struggle to understand and model the inherent tree structure of $\LaTeX$ and often fail to ensure syntactic correctness in the decoded results. To address these challenges, we propose a novel model named TAMER (Tree-Aware Transformer) for handwritten mathematical expression recognition. TAMER introduces an innovative Tree-aware Module while maintaining the flexibility and efficient training of Transformer. TAMER combines the advantages of both sequence decoding and tree decoding models by jointly optimizing sequence prediction and tree structure prediction tasks, which enhances the model's understanding and generalization of complex mathematical expression structures. During inference, TAMER employs a Tree Structure Prediction Scoring Mechanism to improve the structural validity of the generated $\LaTeX$ sequences. Experimental results on CROHME datasets demonstrate that TAMER outperforms traditional sequence decoding and tree decoding models, especially in handling complex mathematical structures, achieving state-of-the-art (SOTA) performance.
SegHist: A General Segmentation-based Framework for Chinese Historical Document Text Line Detection
Jun 25, 2024
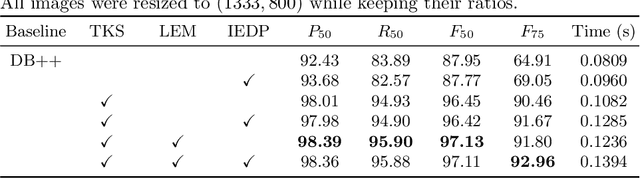
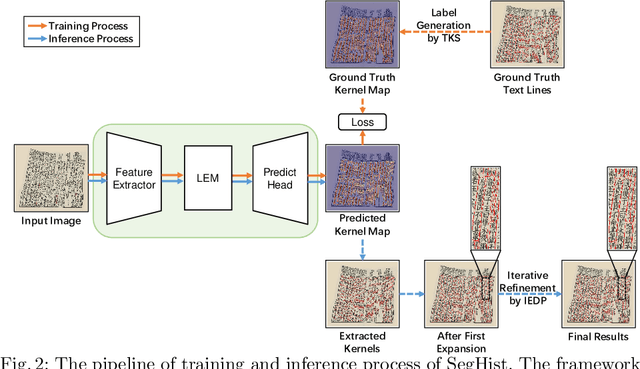
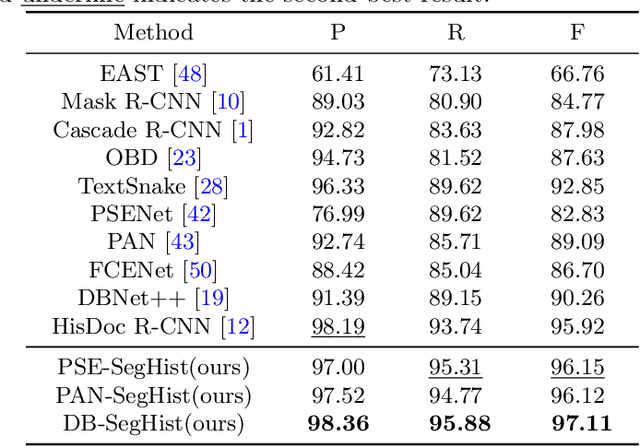
Text line detection is a key task in historical document analysis facing many challenges of arbitrary-shaped text lines, dense texts, and text lines with high aspect ratios, etc. In this paper, we propose a general framework for historical document text detection (SegHist), enabling existing segmentation-based text detection methods to effectively address the challenges, especially text lines with high aspect ratios. Integrating the SegHist framework with the commonly used method DB++, we develop DB-SegHist. This approach achieves SOTA on the CHDAC, MTHv2, and competitive results on HDRC datasets, with a significant improvement of 1.19% on the most challenging CHDAC dataset which features more text lines with high aspect ratios. Moreover, our method attains SOTA on rotated MTHv2 and rotated HDRC, demonstrating its rotational robustness. The code is available at https://github.com/LumionHXJ/SegHist.