 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSegHist: A General Segmentation-based Framework for Chinese Historical Document Text Line Detection
Paper and Code

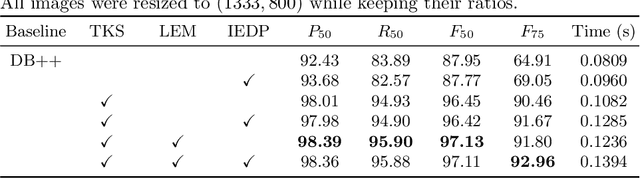
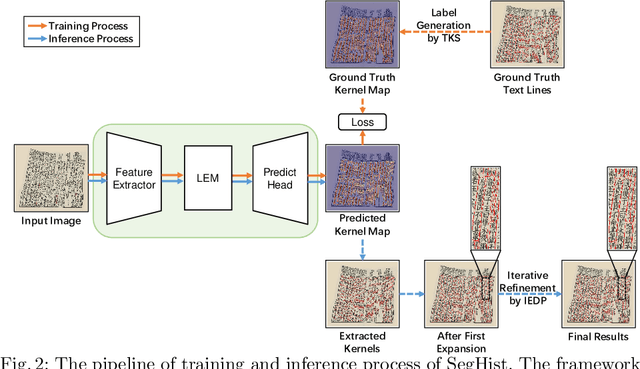
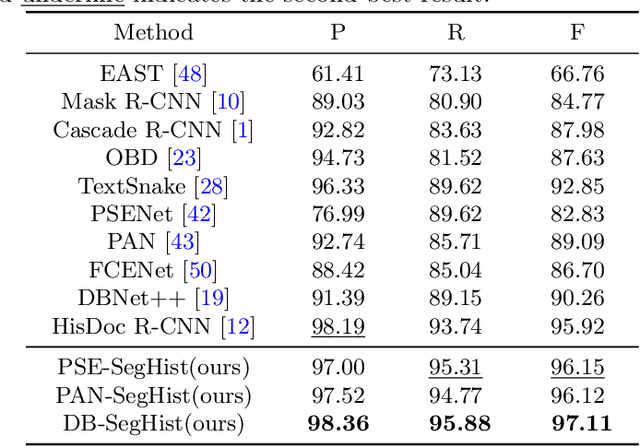
Text line detection is a key task in historical document analysis facing many challenges of arbitrary-shaped text lines, dense texts, and text lines with high aspect ratios, etc. In this paper, we propose a general framework for historical document text detection (SegHist), enabling existing segmentation-based text detection methods to effectively address the challenges, especially text lines with high aspect ratios. Integrating the SegHist framework with the commonly used method DB++, we develop DB-SegHist. This approach achieves SOTA on the CHDAC, MTHv2, and competitive results on HDRC datasets, with a significant improvement of 1.19% on the most challenging CHDAC dataset which features more text lines with high aspect ratios. Moreover, our method attains SOTA on rotated MTHv2 and rotated HDRC, demonstrating its rotational robustness. The code is available at https://github.com/LumionHXJ/SegHist.