 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D-Properties: Identifying Challenges in DPO and Charting a Path Forward
Paper and Code
Jun 11, 2024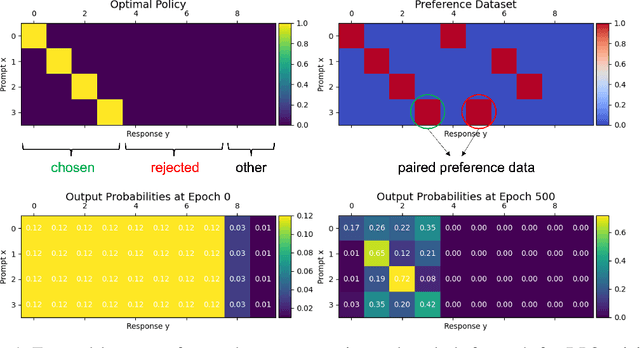
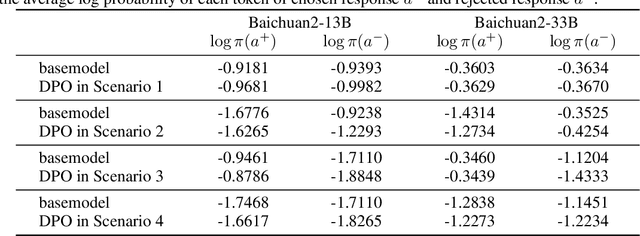
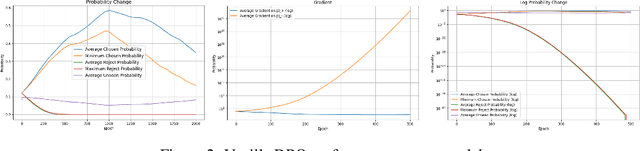
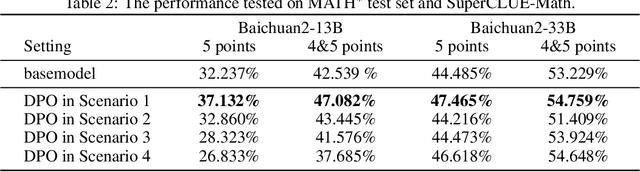
Aligning large language models (LLMs) with human preference has recently gained tremendous attention, with the canonical yet costly RLHF-PPO and the simple and straightforward Direct Preference Optimization (DPO) as two examples. Despite the efficiency, DPO has rarely be used in the state-of-the-art production-level LLMs, implying its potential pathologies. In this work, we revisit DPO with a comprehensive examination of its empirical efficacy and a systematic comparison with RLHF-PPO. We identify the \textbf{3D}-properties of DPO's learning outcomes: the \textbf{D}rastic drop in the likelihood of rejected responses, the \textbf{D}egradation into LLM unlearning, and the \textbf{D}ispersion effect on unseen responses through experiments with both a carefully designed toy model and practical LLMs on tasks including mathematical problem-solving and instruction following. These findings inherently connect to some observations made by related works and we additionally contribute a plausible theoretical explanation for them. Accordingly, we propose easy regularization methods to mitigate the issues caused by \textbf{3D}-properties, improving the training stability and final performance of DPO. Our contributions also include an investigation into how the distribution of the paired preference data impacts the effectiveness of DPO. We hope this work could offer research directions to narrow the gap between reward-free preference learning methods and reward-based ones.