 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty-aware Reward Model: Teaching Reward Models to Know What is Unknown
Oct 01, 2024Reward models (RM) play a critical role in aligning generations of large language models (LLM) to human expectations. However, prevailing RMs fail to capture the stochasticity within human preferences and cannot effectively evaluate the reliability of reward predictions. To address these issues, we propose Uncertain-aware RM (URM) and Uncertain-aware RM Ensemble (URME) to incorporate and manage uncertainty in reward modeling. URM can model the distribution of disentangled attributes within human preferences, while URME quantifies uncertainty through discrepancies in the ensemble, thereby identifying potential lack of knowledge during reward evaluation. Experiment results indicate that the proposed URM achieves state-of-the-art performance compared to models with the same size, demonstrating the effectiveness of modeling uncertainty within human preferences. Furthermore, empirical results show that through uncertainty quantification, URM and URME can identify unreliable predictions to improve the quality of reward evaluations.
Position: Foundation Agents as the Paradigm Shift for Decision Making
May 29, 2024Decision making demands intricate interplay between perception, memory, and reasoning to discern optimal policies. Conventional approaches to decision making face challenges related to low sample efficiency and poor generalization. In contrast, foundation models in language and vision have showcased rapid adaptation to diverse new tasks. Therefore, we advocate for the construction of foundation agents as a transformative shift in the learning paradigm of agents. This proposal is underpinned by the formulation of foundation agents with their fundamental characteristics and challenges motivated by the success of large language models (LLMs). Moreover, we specify the roadmap of foundation agents from large interactive data collection or generation, to self-supervised pretraining and adaptation, and knowledge and value alignment with LLMs. Lastly, we pinpoint critical research questions derived from the formulation and delineate trends for foundation agents supported by real-world use cases, addressing both technical and theoretical aspects to propel the field towards a more comprehensive and impactful future.
SPO: Multi-Dimensional Preference Sequential Alignment With Implicit Reward Modeling
May 21, 2024



Human preference alignment is critical in building powerful and reliable large language models (LLMs). However, current methods either ignore the multi-dimensionality of human preferences (e.g. helpfulness and harmlessness) or struggle with the complexity of managing multiple reward models. To address these issues, we propose Sequential Preference Optimization (SPO), a method that sequentially fine-tunes LLMs to align with multiple dimensions of human preferences. SPO avoids explicit reward modeling, directly optimizing the models to align with nuanced human preferences. We theoretically derive closed-form optimal SPO policy and loss function. Gradient analysis is conducted to show how SPO manages to fine-tune the LLMs while maintaining alignment on previously optimized dimensions. Empirical results on LLMs of different size and multiple evaluation datasets demonstrate that SPO successfully aligns LLMs across multiple dimensions of human preferences and significantly outperforms the baselines.
TAPE: Leveraging Agent Topology for Cooperative Multi-Agent Policy Gradient
Jan 15, 2024



Multi-Agent Policy Gradient (MAPG) has made significant progress in recent years. However, centralized critics in state-of-the-art MAPG methods still face the centralized-decentralized mismatch (CDM) issue, which means sub-optimal actions by some agents will affect other agent's policy learning. While using individual critics for policy updates can avoid this issue, they severely limit cooperation among agents. To address this issue, we propose an agent topology framework, which decides whether other agents should be considered in policy gradient and achieves compromise between facilitating cooperation and alleviating the CDM issue. The agent topology allows agents to use coalition utility as learning objective instead of global utility by centralized critics or local utility by individual critics. To constitute the agent topology, various models are studied. We propose Topology-based multi-Agent Policy gradiEnt (TAPE) for both stochastic and deterministic MAPG methods. We prove the policy improvement theorem for stochastic TAPE and give a theoretical explanation for the improved cooperation among agents. Experiment results on several benchmarks show the agent topology is able to facilitate agent cooperation and alleviate CDM issue respectively to improve performance of TAPE. Finally, multiple ablation studies and a heuristic graph search algorithm are devised to show the efficacy of the agent topology.
Safe Reinforcement Learning with Free-form Natural Language Constraints and Pre-Trained Language Models
Jan 15, 2024



Safe reinforcement learning (RL) agents accomplish given tasks while adhering to specific constraints. Employing constraints expressed via easily-understandable human language offers considerable potential for real-world applications due to its accessibility and non-reliance on domain expertise. Previous safe RL methods with natural language constraints typically adopt a recurrent neural network, which leads to limited capabilities when dealing with various forms of human language input. Furthermore, these methods often require a ground-truth cost function, necessitating domain expertise for the conversion of language constraints into a well-defined cost function that determines constraint violation. To address these issues, we proposes to use pre-trained language models (LM) to facilitate RL agents' comprehension of natural language constraints and allow them to infer costs for safe policy learning. Through the use of pre-trained LMs and the elimination of the need for a ground-truth cost, our method enhances safe policy learning under a diverse set of human-derived free-form natural language constraints. Experiments on grid-world navigation and robot control show that the proposed method can achieve strong performance while adhering to given constraints. The usage of pre-trained LMs allows our method to comprehend complicated constraints and learn safe policies without the need for ground-truth cost at any stage of training or evaluation. Extensive ablation studies are conducted to demonstrate the efficacy of each part of our method.
PECAN: Leveraging Policy Ensemble for Context-Aware Zero-Shot Human-AI Coordination
Jan 16, 2023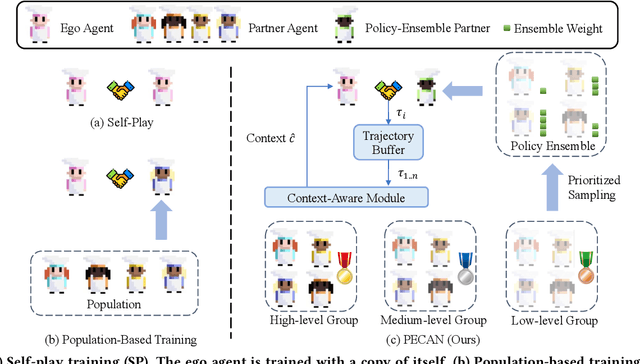
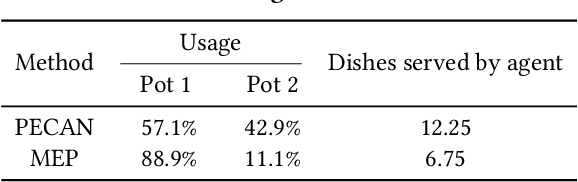
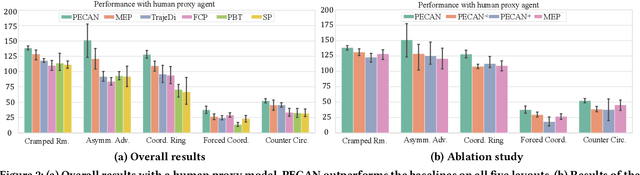
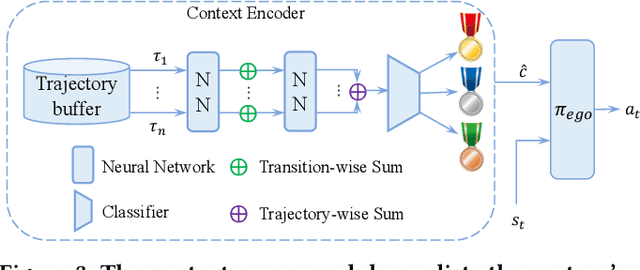
Zero-shot human-AI coordination holds the promise of collaborating with humans without human data. Prevailing methods try to train the ego agent with a population of partners via self-play. However, this kind of method suffers from two problems: 1) The diversity of a population with finite partners is limited, thereby limiting the capacity of the trained ego agent to collaborate with a novel human; 2) Current methods only provide a common best response for every partner in the population, which may result in poor zero-shot coordination performance with a novel partner or humans. To address these issues, we first propose the policy ensemble method to increase the diversity of partners in the population, and then develop a context-aware method enabling the ego agent to analyze and identify the partner's potential policy primitives so that it can take different actions accordingly. In this way, the ego agent is able to learn more universal cooperative behaviors for collaborating with diverse partners. We conduct experiments on the Overcooked environment, and evaluate the zero-shot human-AI coordination performance of our method with both behavior-cloned human proxies and real humans. The results demonstrate that our method significantly increases the diversity of partners and enables ego agents to learn more diverse behaviors than baselines, thus achieving state-of-the-art performance in all scenarios.