 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixed-Phoneme BERT: Improving BERT with Mixed Phoneme and Sup-Phoneme Representations for Text to Speech
Paper and Code
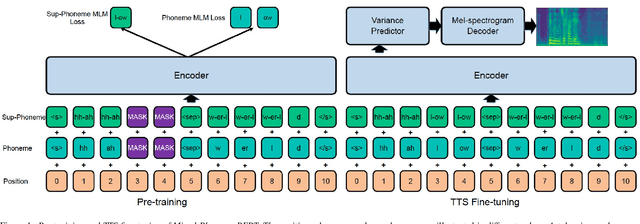
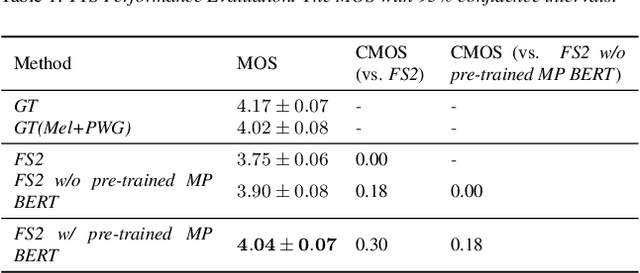

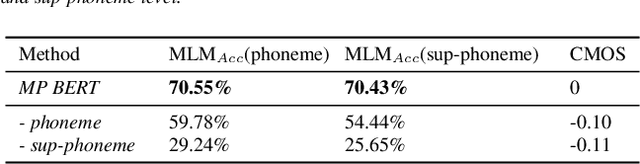
Recently, leveraging BERT pre-training to improve the phoneme encoder in text to speech (TTS) has drawn increasing attention. However, the works apply pre-training with character-based units to enhance the TTS phoneme encoder, which is inconsistent with the TTS fine-tuning that takes phonemes as input. Pre-training only with phonemes as input can alleviate the input mismatch but lack the ability to model rich representations and semantic information due to limited phoneme vocabulary. In this paper, we propose MixedPhoneme BERT, a novel variant of the BERT model that uses mixed phoneme and sup-phoneme representations to enhance the learning capability. Specifically, we merge the adjacent phonemes into sup-phonemes and combine the phoneme sequence and the merged sup-phoneme sequence as the model input, which can enhance the model capacity to learn rich contextual representations. Experiment results demonstrate that our proposed Mixed-Phoneme BERT significantly improves the TTS performance with 0.30 CMOS gain compared with the FastSpeech 2 baseline. The Mixed-Phoneme BERT achieves 3x inference speedup and similar voice quality to the previous TTS pre-trained model PnG BERT