 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA study on the efficacy of model pre-training in developing neural text-to-speech system
Paper and Code
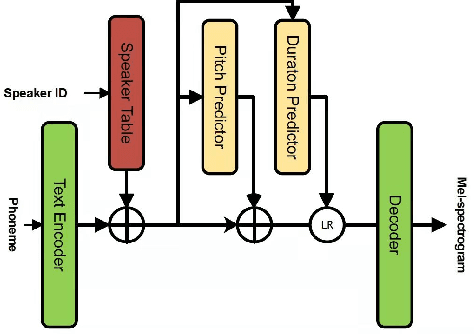
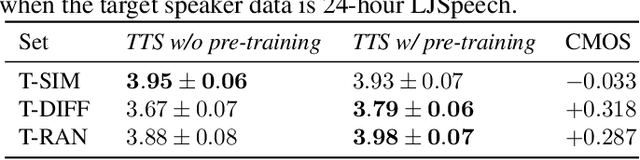
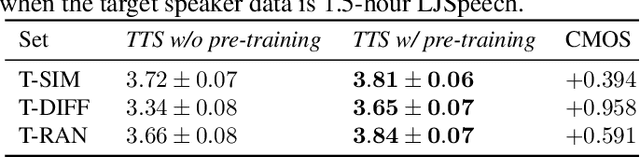
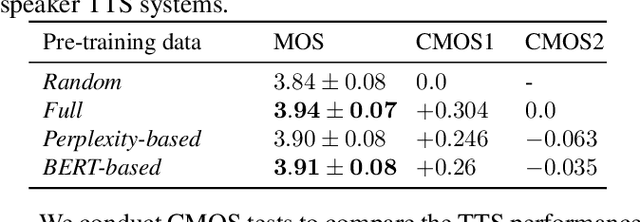
In the development of neural text-to-speech systems, model pre-training with a large amount of non-target speakers' data is a common approach. However, in terms of ultimately achieved system performance for target speaker(s), the actual benefits of model pre-training are uncertain and unstable, depending very much on the quantity and text content of training data. This study aims to understand better why and how model pre-training can positively contribute to TTS system performance. It is postulated that the pre-training process plays a critical role in learning text-related variation in speech, while further training with the target speaker's data aims to capture the speaker-related variation. Different test sets are created with varying degrees of similarity to target speaker data in terms of text content. Experiments show that leveraging a speaker-independent TTS trained on speech data with diverse text content can improve the target speaker TTS on domain-mismatched text. We also attempt to reduce the amount of pre-training data for a new text domain and improve the data and computational efficiency. It is found that the TTS system could achieve comparable performance when the pre-training data is reduced to 1/8 of its original size.