 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCreating Personalized Synthetic Voices from Post-Glossectomy Speech with Guided Diffusion Models
Paper and Code
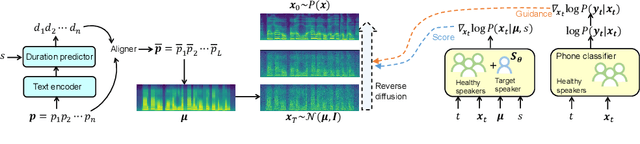
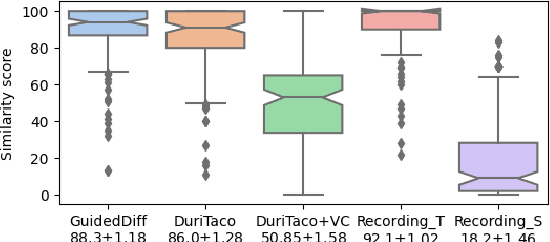
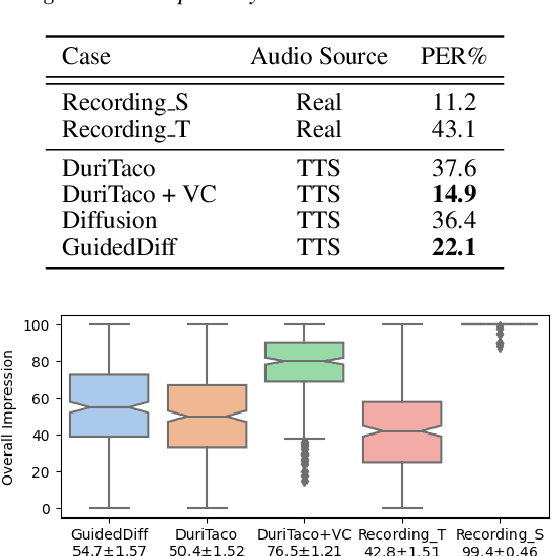
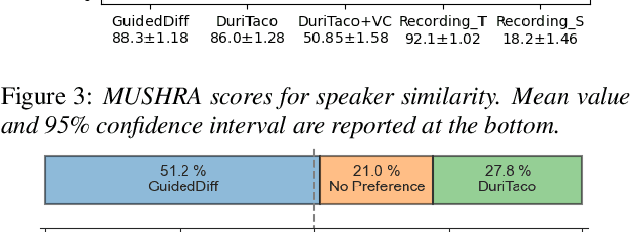
This paper is about developing personalized speech synthesis systems with recordings of mildly impaired speech. In particular, we consider consonant and vowel alterations resulted from partial glossectomy, the surgical removal of part of the tongue. The aim is to restore articulation in the synthesized speech and maximally preserve the target speaker's individuality. We propose to tackle the problem with guided diffusion models. Specifically, a diffusion-based speech synthesis model is trained on original recordings, to capture and preserve the target speaker's original articulation style. When using the model for inference, a separately trained phone classifier will guide the synthesis process towards proper articulation. Objective and subjective evaluation results show that the proposed method substantially improves articulation in the synthesized speech over original recordings, and preserves more of the target speaker's individuality than a voice conversion baseline.