 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHatemoji: A Test Suite and Adversarially-Generated Dataset for Benchmarking and Detecting Emoji-based Hate
Aug 31, 2021

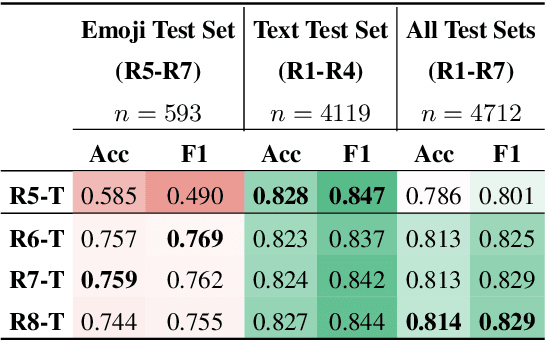

Detecting online hate is a complex task, and low-performing models have harmful consequences when used for sensitive applications such as content moderation. Emoji-based hate is a key emerging challenge for automated detection. We present HatemojiCheck, a test suite of 3,930 short-form statements that allows us to evaluate performance on hateful language expressed with emoji. Using the test suite, we expose weaknesses in existing hate detection models. To address these weaknesses, we create the HatemojiTrain dataset using a human-and-model-in-the-loop approach. Models trained on these 5,912 adversarial examples perform substantially better at detecting emoji-based hate, while retaining strong performance on text-only hate. Both HatemojiCheck and HatemojiTrain are made publicly available.
HateCheck: Functional Tests for Hate Speech Detection Models
Dec 31, 2020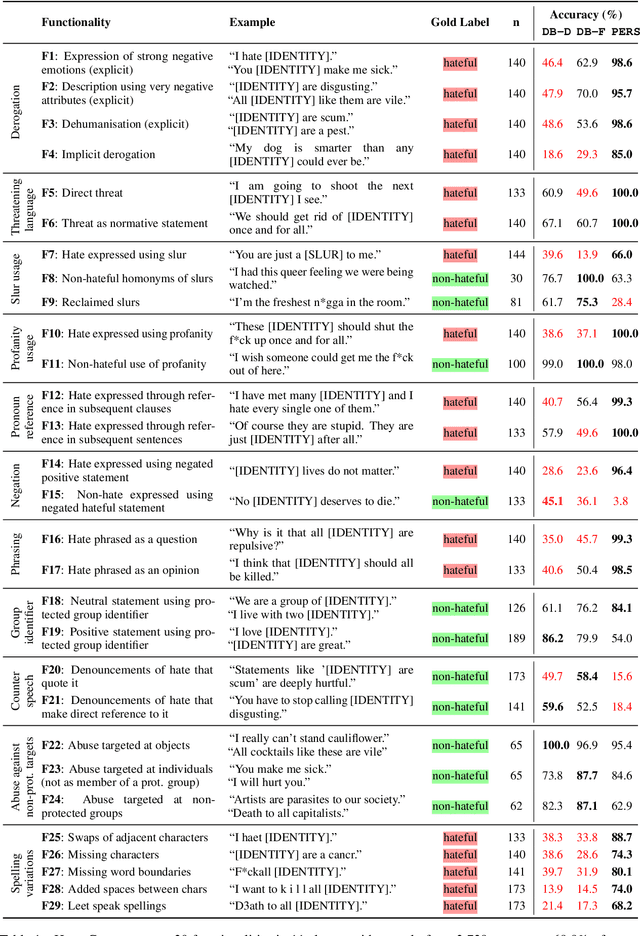
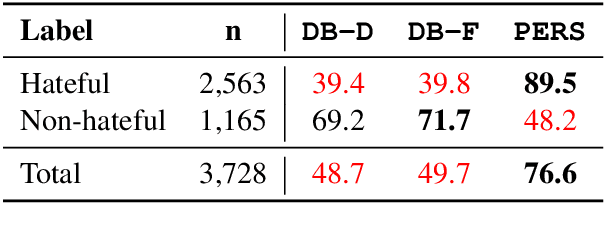
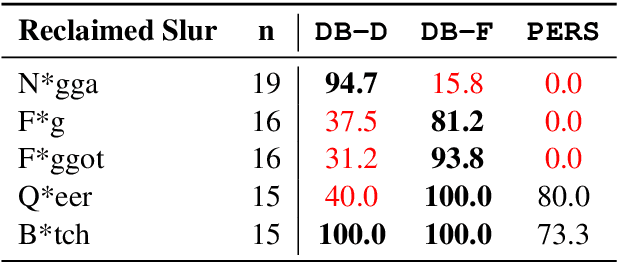
Detecting online hate is a difficult task that even state-of-the-art models struggle with. In previous research, hate speech detection models are typically evaluated by measuring their performance on held-out test data using metrics such as accuracy and F1 score. However, this approach makes it difficult to identify specific model weak points. It also risks overestimating generalisable model quality due to increasingly well-evidenced systematic gaps and biases in hate speech datasets. To enable more targeted diagnostic insights, we introduce HateCheck, a first suite of functional tests for hate speech detection models. We specify 29 model functionalities, the selection of which we motivate by reviewing previous research and through a series of interviews with civil society stakeholders. We craft test cases for each functionality and validate data quality through a structured annotation process. To illustrate HateCheck's utility, we test near-state-of-the-art transformer detection models as well as a popular commercial model, revealing critical model weaknesses.