 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePopulation Gradients improve performance across data-sets and architectures in object classification
Paper and Code
Oct 23, 2020
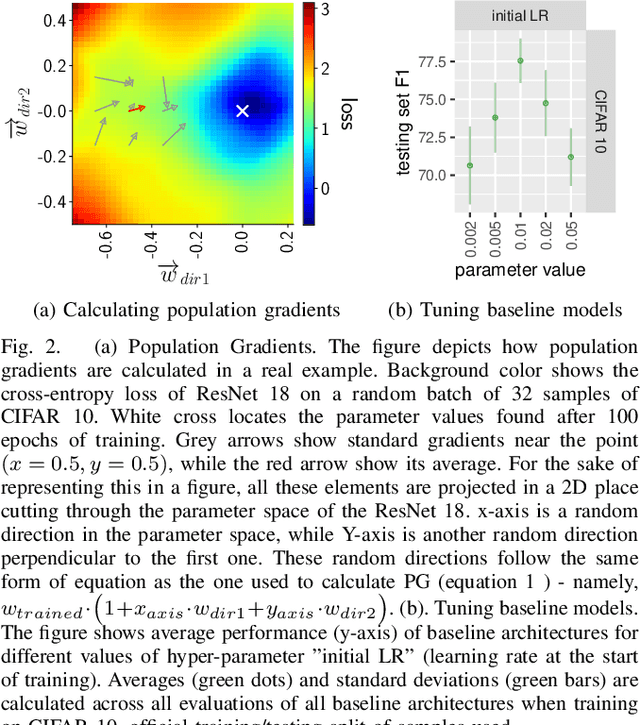
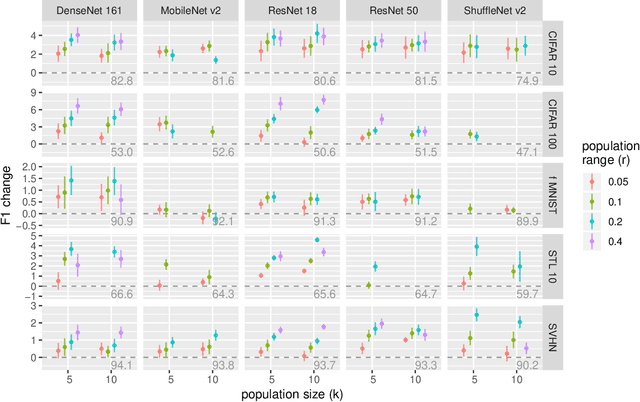
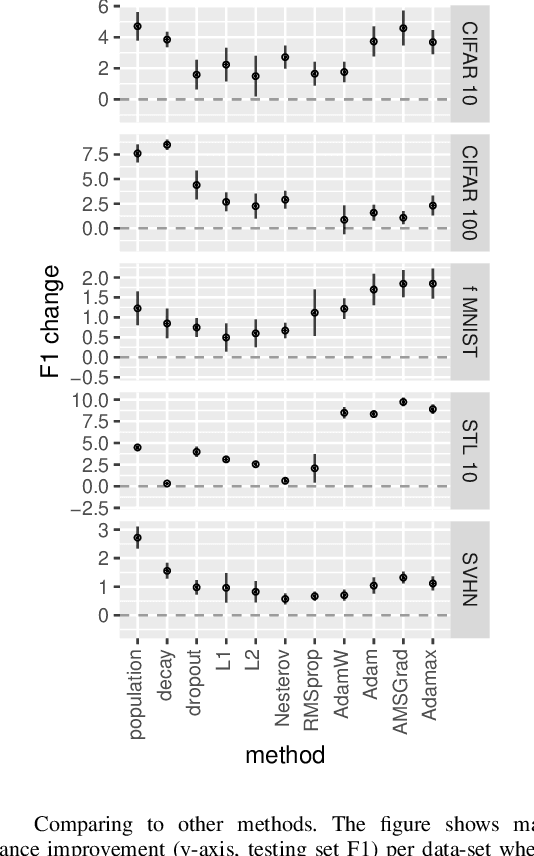
The most successful methods such as ReLU transfer functions, batch normalization, Xavier initialization, dropout, learning rate decay, or dynamic optimizers, have become standards in the field due, particularly, to their ability to increase the performance of Neural Networks (NNs) significantly and in almost all situations. Here we present a new method to calculate the gradients while training NNs, and show that it significantly improves final performance across architectures, data-sets, hyper-parameter values, training length, and model sizes, including when it is being combined with other common performance-improving methods (such as the ones mentioned above). Besides being effective in the wide array situations that we have tested, the increase in performance (e.g. F1) it provides is as high or higher than this one of all the other widespread performance-improving methods that we have compared against. We call our method Population Gradients (PG), and it consists on using a population of NNs to calculate a non-local estimation of the gradient, which is closer to the theoretical exact gradient (i.e. this one obtainable only with an infinitely big data-set) of the error function than the empirical gradient (i.e. this one obtained with the real finite data-set).