 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMed7: a transferable clinical natural language processing model for electronic health records
Paper and Code
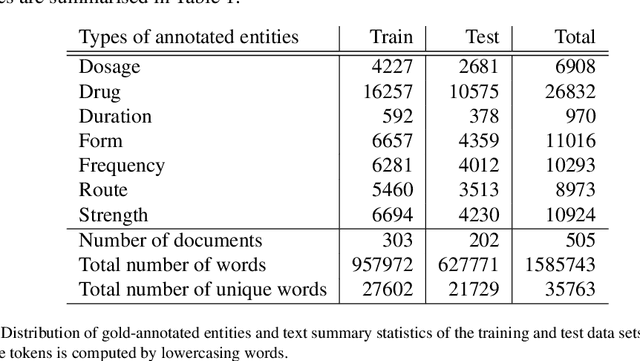
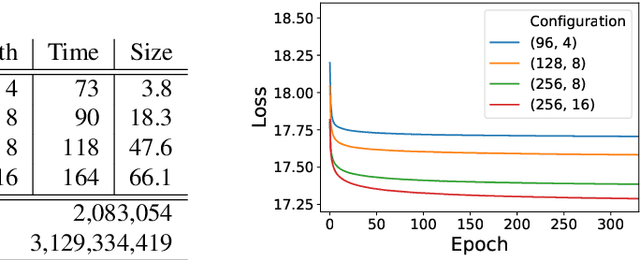
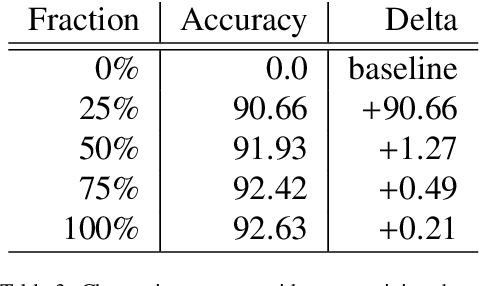
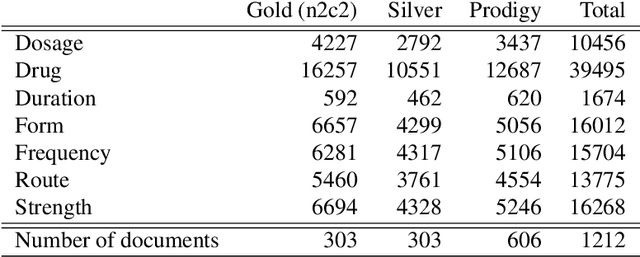
The field of clinical natural language processing has been advanced significantly since the introduction of deep learning models. The self-supervised representation learning and the transfer learning paradigm became the methods of choice in many natural language processing application, in particular in the settings with the dearth of high quality manually annotated data. Electronic health record systems are ubiquitous and the majority of patients' data are now being collected electronically and in particular in the form of free text. Identification of medical concepts and information extraction is a challenging task, yet important ingredient for parsing unstructured data into structured and tabulated format for downstream analytical tasks. In this work we introduced a named-entity recognition model for clinical natural language processing. The model is trained to recognise seven categories: drug names, route, frequency, dosage, strength, form, duration. The model was first self-supervisedly pre-trained by predicting the next word, using a collection of 2 million free-text patients' records from MIMIC-III corpora and then fine-tuned on the named-entity recognition task. The model achieved a lenient (strict) micro-averaged F1 score of 0.957 (0.893) across all seven categories. Additionally, we evaluated the transferability of the developed model using the data from the Intensive Care Unit in the US to secondary care mental health records (CRIS) in the UK. A direct application of the trained NER model to CRIS data resulted in reduced performance of F1=0.762, however after fine-tuning on a small sample from CRIS, the model achieved a reasonable performance of F1=0.944. This demonstrated that despite a close similarity between the data sets and the NER tasks, it is essential to fine-tune on the target domain data in order to achieve more accurate results.