 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmpirical Likelihood-Based Fairness Auditing: Distribution-Free Certification and Flagging
Jan 28, 2026Machine learning models in high-stakes applications, such as recidivism prediction and automated personnel selection, often exhibit systematic performance disparities across sensitive subpopulations, raising critical concerns regarding algorithmic bias. Fairness auditing addresses these risks through two primary functions: certification, which verifies adherence to fairness constraints; and flagging, which isolates specific demographic groups experiencing disparate treatment. However, existing auditing techniques are frequently limited by restrictive distributional assumptions or prohibitive computational overhead. We propose a novel empirical likelihood-based (EL) framework that constructs robust statistical measures for model performance disparities. Unlike traditional methods, our approach is non-parametric; the proposed disparity statistics follow asymptotically chi-square or mixed chi-square distributions, ensuring valid inference without assuming underlying data distributions. This framework uses a constrained optimization profile that admits stable numerical solutions, facilitating both large-scale certification and efficient subpopulation discovery. Empirically, the EL methods outperform bootstrap-based approaches, yielding coverage rates closer to nominal levels while reducing computational latency by several orders of magnitude. We demonstrate the practical utility of this framework on the COMPAS dataset, where it successfully flags intersectional biases, specifically identifying a significantly higher positive prediction rate for African-American males under 25 and a systemic under-prediction for Caucasian females relative to the population mean.
In-Context Learning as Nonparametric Conditional Probability Estimation: Risk Bounds and Optimality
Aug 12, 2025This paper investigates the expected excess risk of In-Context Learning (ICL) for multiclass classification. We model each task as a sequence of labeled prompt samples and a query input, where a pre-trained model estimates the conditional class probabilities of the query. The expected excess risk is defined as the average truncated Kullback-Leibler (KL) divergence between the predicted and ground-truth conditional class distributions, averaged over a specified family of tasks. We establish a new oracle inequality for the expected excess risk based on KL divergence in multiclass classification. This allows us to derive tight upper and lower bounds for the expected excess risk in transformer-based models, demonstrating that the ICL estimator achieves the minimax optimal rate - up to a logarithmic factor - for conditional probability estimation. From a technical standpoint, our results introduce a novel method for controlling generalization error using the uniform empirical covering entropy of the log-likelihood function class. Furthermore, we show that multilayer perceptrons (MLPs) can also perform ICL and achieve this optimal rate under specific assumptions, suggesting that transformers may not be the exclusive architecture capable of effective ICL.
Statistical Theory of Multi-stage Newton Iteration Algorithm for Online Continual Learning
Aug 10, 2025We focus on the critical challenge of handling non-stationary data streams in online continual learning environments, where constrained storage capacity prevents complete retention of historical data, leading to catastrophic forgetting during sequential task training. To more effectively analyze and address the problem of catastrophic forgetting in continual learning, we propose a novel continual learning framework from a statistical perspective. Our approach incorporates random effects across all model parameters and allows the dimension of parameters to diverge to infinity, offering a general formulation for continual learning problems. To efficiently process streaming data, we develop a Multi-step Newton Iteration algorithm that significantly reduces computational costs in certain scenarios by alleviating the burden of matrix inversion. Theoretically, we derive the asymptotic normality of the estimator, enabling subsequent statistical inference. Comprehensive validation through synthetic data experiments and two real datasets analyses demonstrates the effectiveness of our proposed method.
Improving Medical Visual Representation Learning with Pathological-level Cross-Modal Alignment and Correlation Exploration
Jun 12, 2025Learning medical visual representations from image-report pairs through joint learning has garnered increasing research attention due to its potential to alleviate the data scarcity problem in the medical domain. The primary challenges stem from the lengthy reports that feature complex discourse relations and semantic pathologies. Previous works have predominantly focused on instance-wise or token-wise cross-modal alignment, often neglecting the importance of pathological-level consistency. This paper presents a novel framework PLACE that promotes the Pathological-Level Alignment and enriches the fine-grained details via Correlation Exploration without additional human annotations. Specifically, we propose a novel pathological-level cross-modal alignment (PCMA) approach to maximize the consistency of pathology observations from both images and reports. To facilitate this, a Visual Pathology Observation Extractor is introduced to extract visual pathological observation representations from localized tokens. The PCMA module operates independently of any external disease annotations, enhancing the generalizability and robustness of our methods. Furthermore, we design a proxy task that enforces the model to identify correlations among image patches, thereby enriching the fine-grained details crucial for various downstream tasks. Experimental results demonstrate that our proposed framework achieves new state-of-the-art performance on multiple downstream tasks, including classification, image-to-text retrieval, semantic segmentation, object detection and report generation.
Distributed quasi-Newton robust estimation under differential privacy
Aug 22, 2024For distributed computing with Byzantine machines under Privacy Protection (PP) constraints, this paper develops a robust PP distributed quasi-Newton estimation, which only requires the node machines to transmit five vectors to the central processor with high asymptotic relative efficiency. Compared with the gradient descent strategy which requires more rounds of transmission and the Newton iteration strategy which requires the entire Hessian matrix to be transmitted, the novel quasi-Newton iteration has advantages in reducing privacy budgeting and transmission cost. Moreover, our PP algorithm does not depend on the boundedness of gradients and second-order derivatives. When gradients and second-order derivatives follow sub-exponential distributions, we offer a mechanism that can ensure PP with a sufficiently high probability. Furthermore, this novel estimator can achieve the optimal convergence rate and the asymptotic normality. The numerical studies on synthetic and real data sets evaluate the performance of the proposed algorithm.
Scene Graph Aided Radiology Report Generation
Mar 08, 2024



Radiology report generation (RRG) methods often lack sufficient medical knowledge to produce clinically accurate reports. The scene graph contains rich information to describe the objects in an image. We explore enriching the medical knowledge for RRG via a scene graph, which has not been done in the current RRG literature. To this end, we propose the Scene Graph aided RRG (SGRRG) network, a framework that generates region-level visual features, predicts anatomical attributes, and leverages an automatically generated scene graph, thus achieving medical knowledge distillation in an end-to-end manner. SGRRG is composed of a dedicated scene graph encoder responsible for translating the scene graph, and a scene graph-aided decoder that takes advantage of both patch-level and region-level visual information. A fine-grained, sentence-level attention method is designed to better dis-till the scene graph information. Extensive experiments demonstrate that SGRRG outperforms previous state-of-the-art methods in report generation and can better capture abnormal findings.
OpenToM: A Comprehensive Benchmark for Evaluating Theory-of-Mind Reasoning Capabilities of Large Language Models
Feb 14, 2024



Neural Theory-of-Mind (N-ToM), machine's ability to understand and keep track of the mental states of others, is pivotal in developing socially intelligent agents. However, prevalent N-ToM benchmarks have several shortcomings, including the presence of ambiguous and artificial narratives, absence of personality traits and preferences, a lack of questions addressing characters' psychological mental states, and limited diversity in the questions posed. In response to these issues, we construct OpenToM, a new benchmark for assessing N-ToM with (1) longer and clearer narrative stories, (2) characters with explicit personality traits, (3) actions that are triggered by character intentions, and (4) questions designed to challenge LLMs' capabilities of modeling characters' mental states of both the physical and psychological world. Using OpenToM, we reveal that state-of-the-art LLMs thrive at modeling certain aspects of mental states in the physical world but fall short when tracking characters' mental states in the psychological world.
Are NLP Models Good at Tracing Thoughts: An Overview of Narrative Understanding
Oct 28, 2023Narrative understanding involves capturing the author's cognitive processes, providing insights into their knowledge, intentions, beliefs, and desires. Although large language models (LLMs) excel in generating grammatically coherent text, their ability to comprehend the author's thoughts remains uncertain. This limitation hinders the practical applications of narrative understanding. In this paper, we conduct a comprehensive survey of narrative understanding tasks, thoroughly examining their key features, definitions, taxonomy, associated datasets, training objectives, evaluation metrics, and limitations. Furthermore, we explore the potential of expanding the capabilities of modularized LLMs to address novel narrative understanding tasks. By framing narrative understanding as the retrieval of the author's imaginative cues that outline the narrative structure, our study introduces a fresh perspective on enhancing narrative comprehension.
NarrativePlay: Interactive Narrative Understanding
Oct 02, 2023

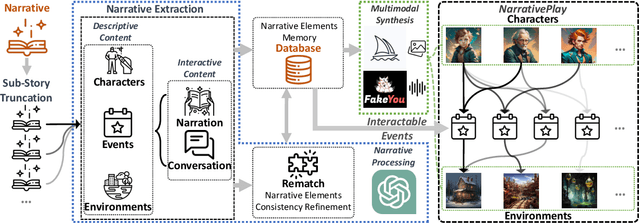
In this paper, we introduce NarrativePlay, a novel system that allows users to role-play a fictional character and interact with other characters in narratives such as novels in an immersive environment. We leverage Large Language Models (LLMs) to generate human-like responses, guided by personality traits extracted from narratives. The system incorporates auto-generated visual display of narrative settings, character portraits, and character speech, greatly enhancing user experience. Our approach eschews predefined sandboxes, focusing instead on main storyline events extracted from narratives from the perspective of a user-selected character. NarrativePlay has been evaluated on two types of narratives, detective and adventure stories, where users can either explore the world or improve their favorability with the narrative characters through conversations.
Can Prompt Learning Benefit Radiology Report Generation?
Aug 30, 2023Radiology report generation aims to automatically provide clinically meaningful descriptions of radiology images such as MRI and X-ray. Although great success has been achieved in natural scene image captioning tasks, radiology report generation remains challenging and requires prior medical knowledge. In this paper, we propose PromptRRG, a method that utilizes prompt learning to activate a pretrained model and incorporate prior knowledge. Since prompt learning for radiology report generation has not been explored before, we begin with investigating prompt designs and categorise them based on varying levels of knowledge: common, domain-specific and disease-enriched prompts. Additionally, we propose an automatic prompt learning mechanism to alleviate the burden of manual prompt engineering. This is the first work to systematically examine the effectiveness of prompt learning for radiology report generation. Experimental results on the largest radiology report generation benchmark, MIMIC-CXR, demonstrate that our proposed method achieves state-of-the-art performance. Code will be available upon the acceptance.