 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Alignment Bottleneck in Decomposition-Based Claim Verification
Feb 11, 2026Structured claim decomposition is often proposed as a solution for verifying complex, multi-faceted claims, yet empirical results have been inconsistent. We argue that these inconsistencies stem from two overlooked bottlenecks: evidence alignment and sub-claim error profiles. To better understand these factors, we introduce a new dataset of real-world complex claims, featuring temporally bounded evidence and human-annotated sub-claim evidence spans. We evaluate decomposition under two evidence alignment setups: Sub-claim Aligned Evidence (SAE) and Repeated Claim-level Evidence (SRE). Our results reveal that decomposition brings significant performance improvement only when evidence is granular and strictly aligned. By contrast, standard setups that rely on repeated claim-level evidence (SRE) fail to improve and often degrade performance as shown across different datasets and domains (PHEMEPlus, MMM-Fact, COVID-Fact). Furthermore, we demonstrate that in the presence of noisy sub-claim labels, the nature of the error ends up determining downstream robustness. We find that conservative "abstention" significantly reduces error propagation compared to aggressive but incorrect predictions. These findings suggest that future claim decomposition frameworks must prioritize precise evidence synthesis and calibrate the label bias of sub-claim verification models.
A Novel, Human-in-the-Loop Computational Grounded Theory Framework for Big Social Data
Jun 06, 2025The availability of big data has significantly influenced the possibilities and methodological choices for conducting large-scale behavioural and social science research. In the context of qualitative data analysis, a major challenge is that conventional methods require intensive manual labour and are often impractical to apply to large datasets. One effective way to address this issue is by integrating emerging computational methods to overcome scalability limitations. However, a critical concern for researchers is the trustworthiness of results when Machine Learning (ML) and Natural Language Processing (NLP) tools are used to analyse such data. We argue that confidence in the credibility and robustness of results depends on adopting a 'human-in-the-loop' methodology that is able to provide researchers with control over the analytical process, while retaining the benefits of using ML and NLP. With this in mind, we propose a novel methodological framework for Computational Grounded Theory (CGT) that supports the analysis of large qualitative datasets, while maintaining the rigour of established Grounded Theory (GT) methodologies. To illustrate the framework's value, we present the results of testing it on a dataset collected from Reddit in a study aimed at understanding tutors' experiences in the gig economy.
Machine Learning Information Retrieval and Summarisation to Support Systematic Review on Outcomes Based Contracting
Dec 11, 2024As academic literature proliferates, traditional review methods are increasingly challenged by the sheer volume and diversity of available research. This article presents a study that aims to address these challenges by enhancing the efficiency and scope of systematic reviews in the social sciences through advanced machine learning (ML) and natural language processing (NLP) tools. In particular, we focus on automating stages within the systematic reviewing process that are time-intensive and repetitive for human annotators and which lend themselves to immediate scalability through tools such as information retrieval and summarisation guided by expert advice. The article concludes with a summary of lessons learnt regarding the integrated approach towards systematic reviews and future directions for improvement, including explainability.
SyROCCo: Enhancing Systematic Reviews using Machine Learning
Jun 24, 2024

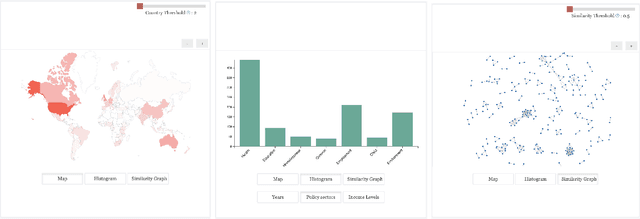

The sheer number of research outputs published every year makes systematic reviewing increasingly time- and resource-intensive. This paper explores the use of machine learning techniques to help navigate the systematic review process. ML has previously been used to reliably 'screen' articles for review - that is, identify relevant articles based on reviewers' inclusion criteria. The application of ML techniques to subsequent stages of a review, however, such as data extraction and evidence mapping, is in its infancy. We therefore set out to develop a series of tools that would assist in the profiling and analysis of 1,952 publications on the theme of 'outcomes-based contracting'. Tools were developed for the following tasks: assign publications into 'policy area' categories; identify and extract key information for evidence mapping, such as organisations, laws, and geographical information; connect the evidence base to an existing dataset on the same topic; and identify subgroups of articles that may share thematic content. An interactive tool using these techniques and a public dataset with their outputs have been released. Our results demonstrate the utility of ML techniques to enhance evidence accessibility and analysis within the systematic review processes. These efforts show promise in potentially yielding substantial efficiencies for future systematic reviewing and for broadening their analytical scope. Our work suggests that there may be implications for the ease with which policymakers and practitioners can access evidence. While ML techniques seem poised to play a significant role in bridging the gap between research and policy by offering innovative ways of gathering, accessing, and analysing data from systematic reviews, we also highlight their current limitations and the need to exercise caution in their application, particularly given the potential for errors and biases.
Multi-Layer Ranking with Large Language Models for News Source Recommendation
Jun 17, 2024To seek reliable information sources for news events, we introduce a novel task of expert recommendation, which aims to identify trustworthy sources based on their previously quoted statements. To achieve this, we built a novel dataset, called NewsQuote, consisting of 23,571 quote-speaker pairs sourced from a collection of news articles. We formulate the recommendation task as the retrieval of experts based on their likelihood of being associated with a given query. We also propose a multi-layer ranking framework employing Large Language Models to improve the recommendation performance. Our results show that employing an in-context learning based LLM ranker and a multi-layer ranking-based filter significantly improve both the predictive quality and behavioural quality of the recommender system.
Generating Unsupervised Abstractive Explanations for Rumour Verification
Jan 23, 2024



The task of rumour verification in social media concerns assessing the veracity of a claim on the basis of conversation threads that result from it. While previous work has focused on predicting a veracity label, here we reformulate the task to generate model-centric, free-text explanations of a rumour's veracity. We follow an unsupervised approach by first utilising post-hoc explainability methods to score the most important posts within a thread and then we use these posts to generate informative explanatory summaries by employing template-guided summarisation. To evaluate the informativeness of the explanatory summaries, we exploit the few-shot learning capabilities of a large language model (LLM). Our experiments show that LLMs can have similar agreement to humans in evaluating summaries. Importantly, we show that explanatory abstractive summaries are more informative and better reflect the predicted rumour veracity than just using the highest ranking posts in the thread.
BERTTM: Leveraging Contextualized Word Embeddings from Pre-trained Language Models for Neural Topic Modeling
May 17, 2023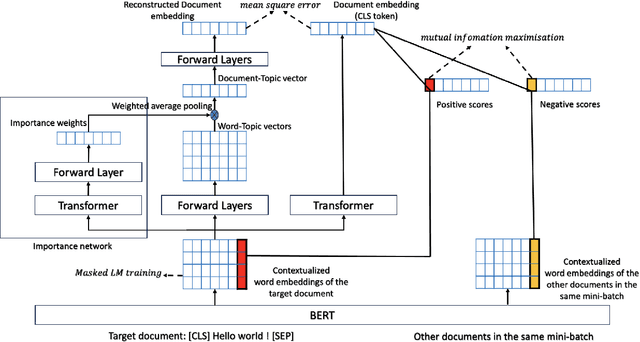
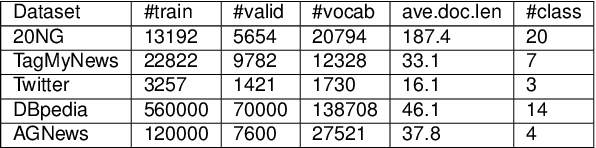
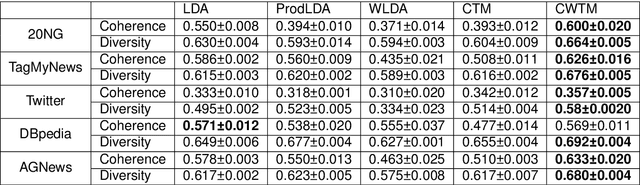
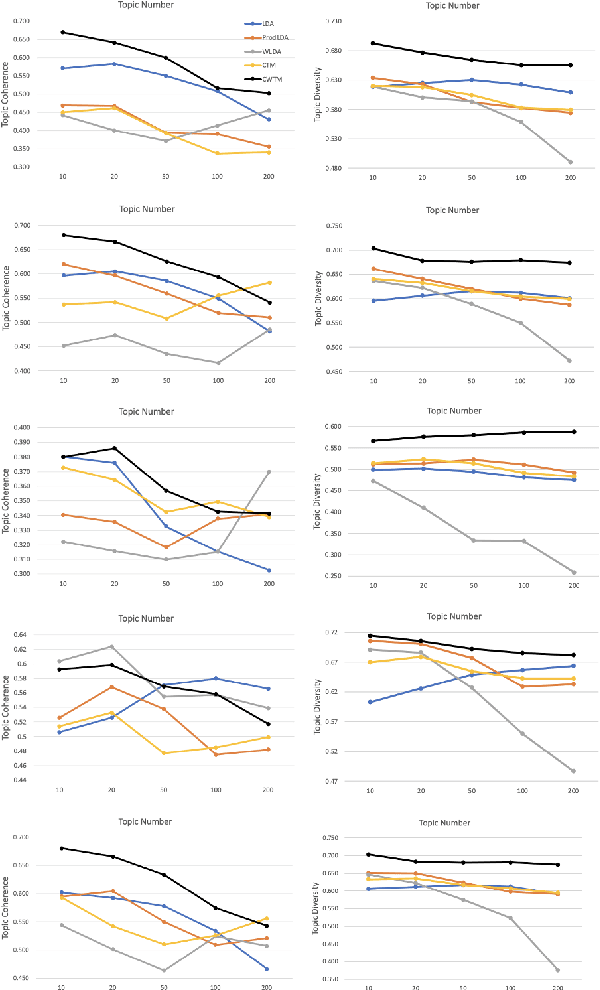
With the development of neural topic models in recent years, topic modelling is playing an increasingly important role in natural language understanding. However, most existing topic models still rely on bag-of-words (BoW) information, either as training input or training target. This limits their ability to capture word order information in documents and causes them to suffer from the out-of-vocabulary (OOV) issue, i.e. they cannot handle unobserved words in new documents. Contextualized word embeddings from pre-trained language models show superiority in the ability of word sense disambiguation and prove to be effective in dealing with OOV words. In this work, we developed a novel neural topic model combining contextualized word embeddings from the pre-trained language model BERT. The model can infer the topic distribution of a document without using any BoW information. In addition, the model can infer the topic distribution of each word in a document directly from the contextualized word embeddings. Experiments on several datasets show that our model outperforms existing topic models in terms of both document classification and topic coherence metrics and can accommodate unseen words from newly arrived documents. Experiments on the NER dataset also show that our model can produce high-quality word topic representations.
NewsQuote: A Dataset Built on Quote Extraction and Attribution for Expert Recommendation in Fact-Checking
May 05, 2023



To enhance the ability to find credible evidence in news articles, we propose a novel task of expert recommendation, which aims to identify trustworthy experts on a specific news topic. To achieve the aim, we describe the construction of a novel NewsQuote dataset consisting of 24,031 quote-speaker pairs that appeared on a COVID-19 news corpus. We demonstrate an automatic pipeline for speaker and quote extraction via a BERT-based Question Answering model. Then, we formulate expert recommendations as document retrieval task by retrieving relevant quotes first as an intermediate step for expert identification, and expert retrieval by directly retrieving sources based on the probability of a query conditional on a candidate expert. Experimental results on NewsQuote show that document retrieval is more effective in identifying relevant experts for a given news topic compared to expert retrieval
A User-Centered, Interactive, Human-in-the-Loop Topic Modelling System
Apr 04, 2023Human-in-the-loop topic modelling incorporates users' knowledge into the modelling process, enabling them to refine the model iteratively. Recent research has demonstrated the value of user feedback, but there are still issues to consider, such as the difficulty in tracking changes, comparing different models and the lack of evaluation based on real-world examples of use. We developed a novel, interactive human-in-the-loop topic modeling system with a user-friendly interface that enables users compare and record every step they take, and a novel topic words suggestion feature to help users provide feedback that is faithful to the ground truth. Our system also supports not only what traditional topic models can do, i.e., learning the topics from the whole corpus, but also targeted topic modelling, i.e., learning topics for specific aspects of the corpus. In this article, we provide an overview of the system and present the results of a series of user studies designed to assess the value of the system in progressively more realistic applications of topic modelling.
PANACEA: An Automated Misinformation Detection System on COVID-19
Feb 28, 2023In this demo, we introduce a web-based misinformation detection system PANACEA on COVID-19 related claims, which has two modules, fact-checking and rumour detection. Our fact-checking module, which is supported by novel natural language inference methods with a self-attention network, outperforms state-of-the-art approaches. It is also able to give automated veracity assessment and ranked supporting evidence with the stance towards the claim to be checked. In addition, PANACEA adapts the bi-directional graph convolutional networks model, which is able to detect rumours based on comment networks of related tweets, instead of relying on the knowledge base. This rumour detection module assists by warning the users in the early stages when a knowledge base may not be available.