 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBERTTM: Leveraging Contextualized Word Embeddings from Pre-trained Language Models for Neural Topic Modeling
Paper and Code
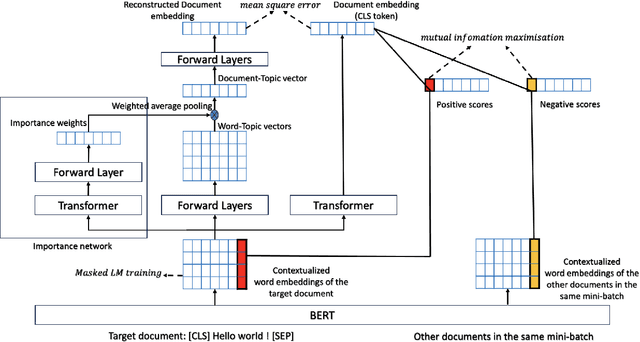
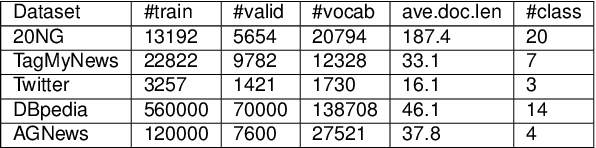
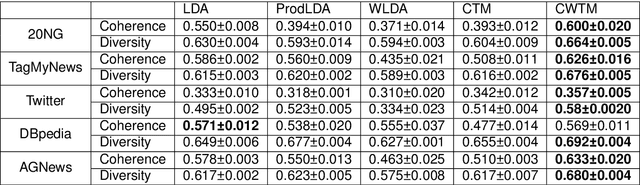
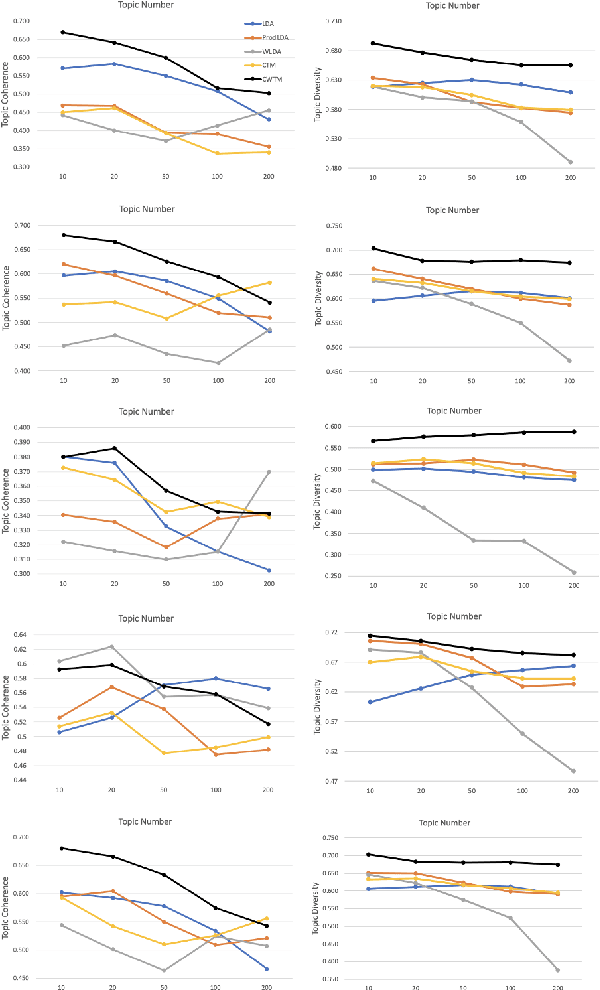
With the development of neural topic models in recent years, topic modelling is playing an increasingly important role in natural language understanding. However, most existing topic models still rely on bag-of-words (BoW) information, either as training input or training target. This limits their ability to capture word order information in documents and causes them to suffer from the out-of-vocabulary (OOV) issue, i.e. they cannot handle unobserved words in new documents. Contextualized word embeddings from pre-trained language models show superiority in the ability of word sense disambiguation and prove to be effective in dealing with OOV words. In this work, we developed a novel neural topic model combining contextualized word embeddings from the pre-trained language model BERT. The model can infer the topic distribution of a document without using any BoW information. In addition, the model can infer the topic distribution of each word in a document directly from the contextualized word embeddings. Experiments on several datasets show that our model outperforms existing topic models in terms of both document classification and topic coherence metrics and can accommodate unseen words from newly arrived documents. Experiments on the NER dataset also show that our model can produce high-quality word topic representations.