 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine Learning Information Retrieval and Summarisation to Support Systematic Review on Outcomes Based Contracting
Dec 11, 2024As academic literature proliferates, traditional review methods are increasingly challenged by the sheer volume and diversity of available research. This article presents a study that aims to address these challenges by enhancing the efficiency and scope of systematic reviews in the social sciences through advanced machine learning (ML) and natural language processing (NLP) tools. In particular, we focus on automating stages within the systematic reviewing process that are time-intensive and repetitive for human annotators and which lend themselves to immediate scalability through tools such as information retrieval and summarisation guided by expert advice. The article concludes with a summary of lessons learnt regarding the integrated approach towards systematic reviews and future directions for improvement, including explainability.
Generating Unsupervised Abstractive Explanations for Rumour Verification
Jan 23, 2024



The task of rumour verification in social media concerns assessing the veracity of a claim on the basis of conversation threads that result from it. While previous work has focused on predicting a veracity label, here we reformulate the task to generate model-centric, free-text explanations of a rumour's veracity. We follow an unsupervised approach by first utilising post-hoc explainability methods to score the most important posts within a thread and then we use these posts to generate informative explanatory summaries by employing template-guided summarisation. To evaluate the informativeness of the explanatory summaries, we exploit the few-shot learning capabilities of a large language model (LLM). Our experiments show that LLMs can have similar agreement to humans in evaluating summaries. Importantly, we show that explanatory abstractive summaries are more informative and better reflect the predicted rumour veracity than just using the highest ranking posts in the thread.
Sig-Networks Toolkit: Signature Networks for Longitudinal Language Modelling
Dec 06, 2023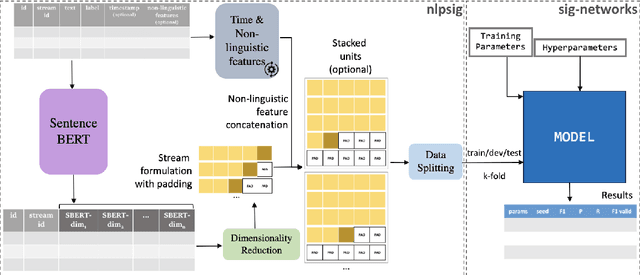
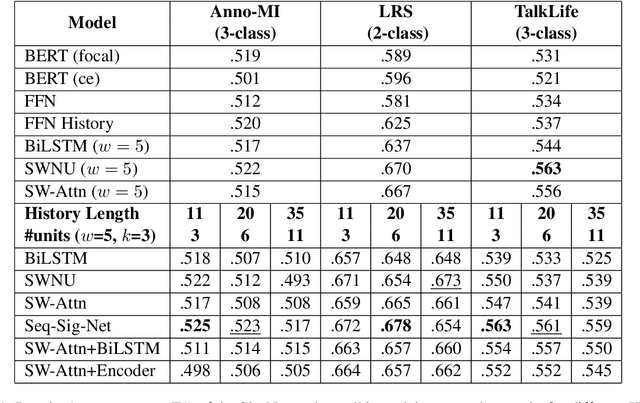
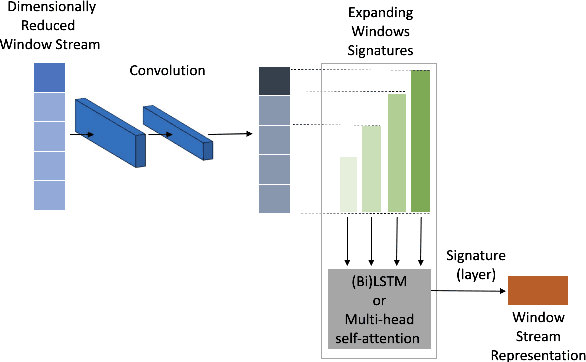
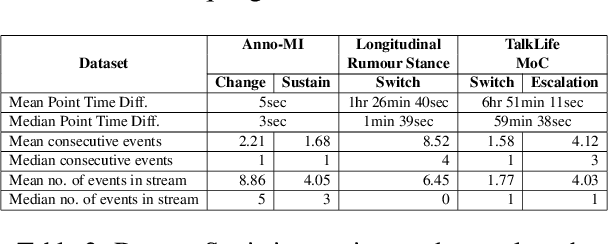
We present an open-source, pip installable toolkit, Sig-Networks, the first of its kind for longitudinal language modelling. A central focus is the incorporation of Signature-based Neural Network models, which have recently shown success in temporal tasks. We apply and extend published research providing a full suite of signature-based models. Their components can be used as PyTorch building blocks in future architectures. Sig-Networks enables task-agnostic dataset plug-in, seamless pre-processing for sequential data, parameter flexibility, automated tuning across a range of models. We examine signature networks under three different NLP tasks of varying temporal granularity: counselling conversations, rumour stance switch and mood changes in social media threads, showing SOTA performance in all three, and provide guidance for future tasks. We release the Toolkit as a PyTorch package with an introductory video, Git repositories for preprocessing and modelling including sample notebooks on the modeled NLP tasks.
Unsupervised Opinion Summarisation in the Wasserstein Space
Nov 27, 2022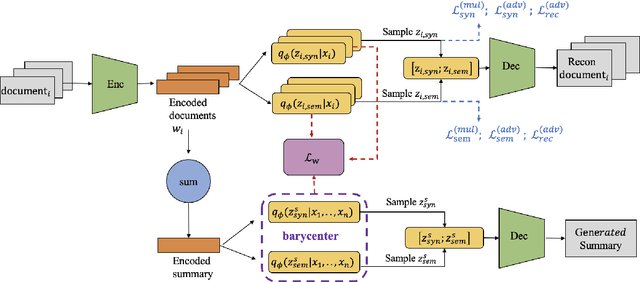
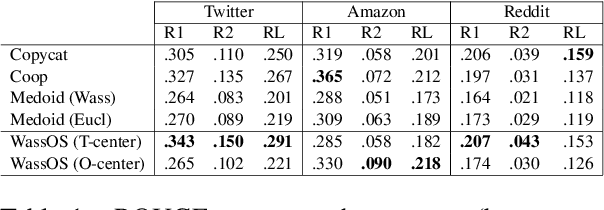
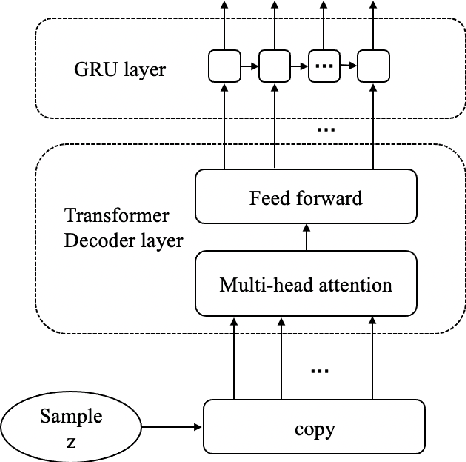
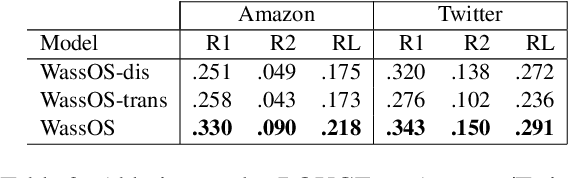
Opinion summarisation synthesises opinions expressed in a group of documents discussing the same topic to produce a single summary. Recent work has looked at opinion summarisation of clusters of social media posts. Such posts are noisy and have unpredictable structure, posing additional challenges for the construction of the summary distribution and the preservation of meaning compared to online reviews, which has been so far the focus of opinion summarisation. To address these challenges we present \textit{WassOS}, an unsupervised abstractive summarization model which makes use of the Wasserstein distance. A Variational Autoencoder is used to get the distribution of documents/posts, and the distributions are disentangled into separate semantic and syntactic spaces. The summary distribution is obtained using the Wasserstein barycenter of the semantic and syntactic distributions. A latent variable sampled from the summary distribution is fed into a GRU decoder with a transformer layer to produce the final summary. Our experiments on multiple datasets including Twitter clusters, Reddit threads, and reviews show that WassOS almost always outperforms the state-of-the-art on ROUGE metrics and consistently produces the best summaries with respect to meaning preservation according to human evaluations.
Template-based Abstractive Microblog Opinion Summarisation
Aug 08, 2022
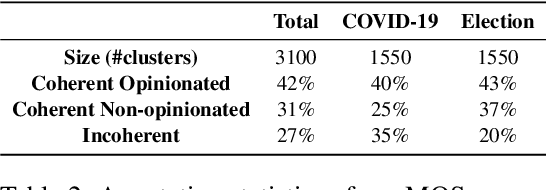


We introduce the task of microblog opinion summarisation (MOS) and share a dataset of 3100 gold-standard opinion summaries to facilitate research in this domain. The dataset contains summaries of tweets spanning a 2-year period and covers more topics than any other public Twitter summarisation dataset. Summaries are abstractive in nature and have been created by journalists skilled in summarising news articles following a template separating factual information (main story) from author opinions. Our method differs from previous work on generating gold-standard summaries from social media, which usually involves selecting representative posts and thus favours extractive summarisation models. To showcase the dataset's utility and challenges, we benchmark a range of abstractive and extractive state-of-the-art summarisation models and achieve good performance, with the former outperforming the latter. We also show that fine-tuning is necessary to improve performance and investigate the benefits of using different sample sizes.
Evaluation of Thematic Coherence in Microblogs
Jun 30, 2021
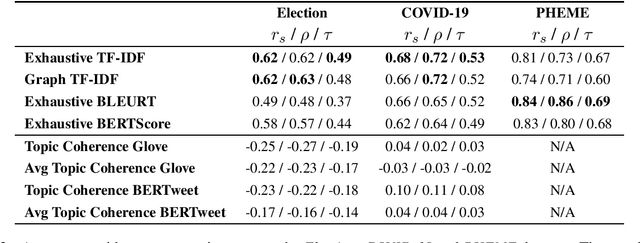


Collecting together microblogs representing opinions about the same topics within the same timeframe is useful to a number of different tasks and practitioners. A major question is how to evaluate the quality of such thematic clusters. Here we create a corpus of microblog clusters from three different domains and time windows and define the task of evaluating thematic coherence. We provide annotation guidelines and human annotations of thematic coherence by journalist experts. We subsequently investigate the efficacy of different automated evaluation metrics for the task. We consider a range of metrics including surface level metrics, ones for topic model coherence and text generation metrics (TGMs). While surface level metrics perform well, outperforming topic coherence metrics, they are not as consistent as TGMs. TGMs are more reliable than all other metrics considered for capturing thematic coherence in microblog clusters due to being less sensitive to the effect of time windows.