 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Medical Visual Representation Learning with Pathological-level Cross-Modal Alignment and Correlation Exploration
Jun 12, 2025Learning medical visual representations from image-report pairs through joint learning has garnered increasing research attention due to its potential to alleviate the data scarcity problem in the medical domain. The primary challenges stem from the lengthy reports that feature complex discourse relations and semantic pathologies. Previous works have predominantly focused on instance-wise or token-wise cross-modal alignment, often neglecting the importance of pathological-level consistency. This paper presents a novel framework PLACE that promotes the Pathological-Level Alignment and enriches the fine-grained details via Correlation Exploration without additional human annotations. Specifically, we propose a novel pathological-level cross-modal alignment (PCMA) approach to maximize the consistency of pathology observations from both images and reports. To facilitate this, a Visual Pathology Observation Extractor is introduced to extract visual pathological observation representations from localized tokens. The PCMA module operates independently of any external disease annotations, enhancing the generalizability and robustness of our methods. Furthermore, we design a proxy task that enforces the model to identify correlations among image patches, thereby enriching the fine-grained details crucial for various downstream tasks. Experimental results demonstrate that our proposed framework achieves new state-of-the-art performance on multiple downstream tasks, including classification, image-to-text retrieval, semantic segmentation, object detection and report generation.
STX-Search: Explanation Search for Continuous Dynamic Spatio-Temporal Models
Mar 06, 2025



Recent improvements in the expressive power of spatio-temporal models have led to performance gains in many real-world applications, such as traffic forecasting and social network modelling. However, understanding the predictions from a model is crucial to ensure reliability and trustworthiness, particularly for high-risk applications, such as healthcare and transport. Few existing methods are able to generate explanations for models trained on continuous-time dynamic graph data and, of these, the computational complexity and lack of suitable explanation objectives pose challenges. In this paper, we propose $\textbf{S}$patio-$\textbf{T}$emporal E$\textbf{X}$planation $\textbf{Search}$ (STX-Search), a novel method for generating instance-level explanations that is applicable to static and dynamic temporal graph structures. We introduce a novel search strategy and objective function, to find explanations that are highly faithful and interpretable. When compared with existing methods, STX-Search produces explanations of higher fidelity whilst optimising explanation size to maintain interpretability.
MASALA: Model-Agnostic Surrogate Explanations by Locality Adaptation
Aug 19, 2024



Existing local Explainable AI (XAI) methods, such as LIME, select a region of the input space in the vicinity of a given input instance, for which they approximate the behaviour of a model using a simpler and more interpretable surrogate model. The size of this region is often controlled by a user-defined locality hyperparameter. In this paper, we demonstrate the difficulties associated with defining a suitable locality size to capture impactful model behaviour, as well as the inadequacy of using a single locality size to explain all predictions. We propose a novel method, MASALA, for generating explanations, which automatically determines the appropriate local region of impactful model behaviour for each individual instance being explained. MASALA approximates the local behaviour used by a complex model to make a prediction by fitting a linear surrogate model to a set of points which experience similar model behaviour. These points are found by clustering the input space into regions of linear behavioural trends exhibited by the model. We compare the fidelity and consistency of explanations generated by our method with existing local XAI methods, namely LIME and CHILLI. Experiments on the PHM08 and MIDAS datasets show that our method produces more faithful and consistent explanations than existing methods, without the need to define any sensitive locality hyperparameters.
CHILLI: A data context-aware perturbation method for XAI
Jul 10, 2024



The trustworthiness of Machine Learning (ML) models can be difficult to assess, but is critical in high-risk or ethically sensitive applications. Many models are treated as a `black-box' where the reasoning or criteria for a final decision is opaque to the user. To address this, some existing Explainable AI (XAI) approaches approximate model behaviour using perturbed data. However, such methods have been criticised for ignoring feature dependencies, with explanations being based on potentially unrealistic data. We propose a novel framework, CHILLI, for incorporating data context into XAI by generating contextually aware perturbations, which are faithful to the training data of the base model being explained. This is shown to improve both the soundness and accuracy of the explanations.
StainFuser: Controlling Diffusion for Faster Neural Style Transfer in Multi-Gigapixel Histology Images
Mar 14, 2024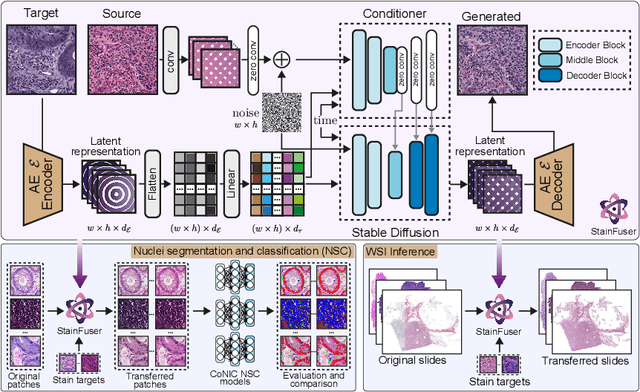

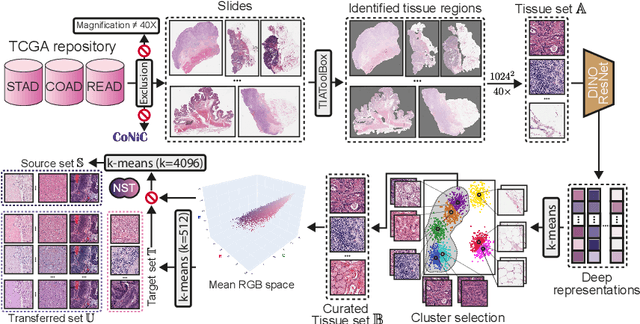
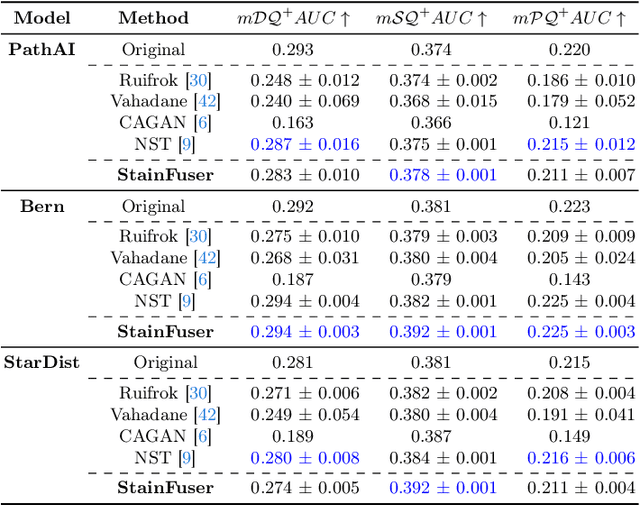
Stain normalization algorithms aim to transform the color and intensity characteristics of a source multi-gigapixel histology image to match those of a target image, mitigating inconsistencies in the appearance of stains used to highlight cellular components in the images. We propose a new approach, StainFuser, which treats this problem as a style transfer task using a novel Conditional Latent Diffusion architecture, eliminating the need for handcrafted color components. With this method, we curate SPI-2M the largest stain normalization dataset to date of over 2 million histology images with neural style transfer for high-quality transformations. Trained on this data, StainFuser outperforms current state-of-the-art GAN and handcrafted methods in terms of the quality of normalized images. Additionally, compared to existing approaches, it improves the performance of nuclei instance segmentation and classification models when used as a test time augmentation method on the challenging CoNIC dataset. Finally, we apply StainFuser on multi-gigapixel Whole Slide Images (WSIs) and demonstrate improved performance in terms of computational efficiency, image quality and consistency across tiles over current methods.
Scene Graph Aided Radiology Report Generation
Mar 08, 2024



Radiology report generation (RRG) methods often lack sufficient medical knowledge to produce clinically accurate reports. The scene graph contains rich information to describe the objects in an image. We explore enriching the medical knowledge for RRG via a scene graph, which has not been done in the current RRG literature. To this end, we propose the Scene Graph aided RRG (SGRRG) network, a framework that generates region-level visual features, predicts anatomical attributes, and leverages an automatically generated scene graph, thus achieving medical knowledge distillation in an end-to-end manner. SGRRG is composed of a dedicated scene graph encoder responsible for translating the scene graph, and a scene graph-aided decoder that takes advantage of both patch-level and region-level visual information. A fine-grained, sentence-level attention method is designed to better dis-till the scene graph information. Extensive experiments demonstrate that SGRRG outperforms previous state-of-the-art methods in report generation and can better capture abnormal findings.
Can Prompt Learning Benefit Radiology Report Generation?
Aug 30, 2023Radiology report generation aims to automatically provide clinically meaningful descriptions of radiology images such as MRI and X-ray. Although great success has been achieved in natural scene image captioning tasks, radiology report generation remains challenging and requires prior medical knowledge. In this paper, we propose PromptRRG, a method that utilizes prompt learning to activate a pretrained model and incorporate prior knowledge. Since prompt learning for radiology report generation has not been explored before, we begin with investigating prompt designs and categorise them based on varying levels of knowledge: common, domain-specific and disease-enriched prompts. Additionally, we propose an automatic prompt learning mechanism to alleviate the burden of manual prompt engineering. This is the first work to systematically examine the effectiveness of prompt learning for radiology report generation. Experimental results on the largest radiology report generation benchmark, MIMIC-CXR, demonstrate that our proposed method achieves state-of-the-art performance. Code will be available upon the acceptance.
LYSTO: The Lymphocyte Assessment Hackathon and Benchmark Dataset
Jan 16, 2023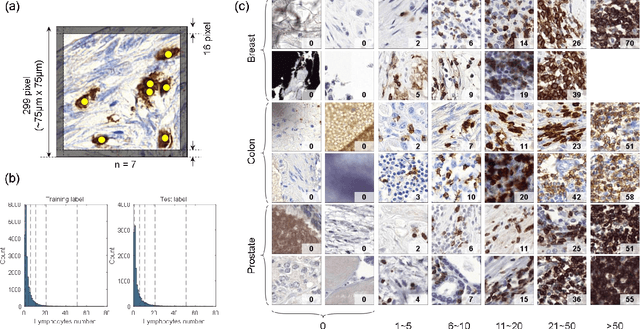
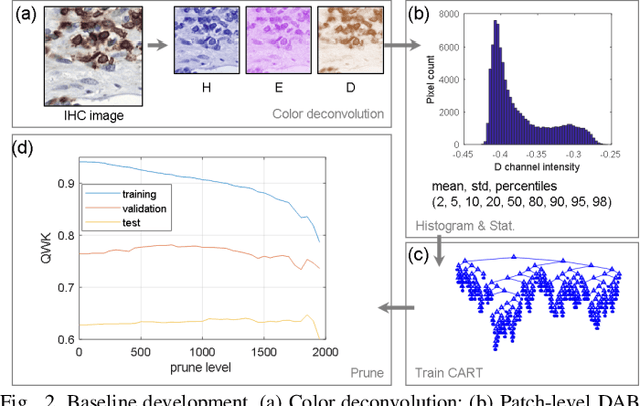
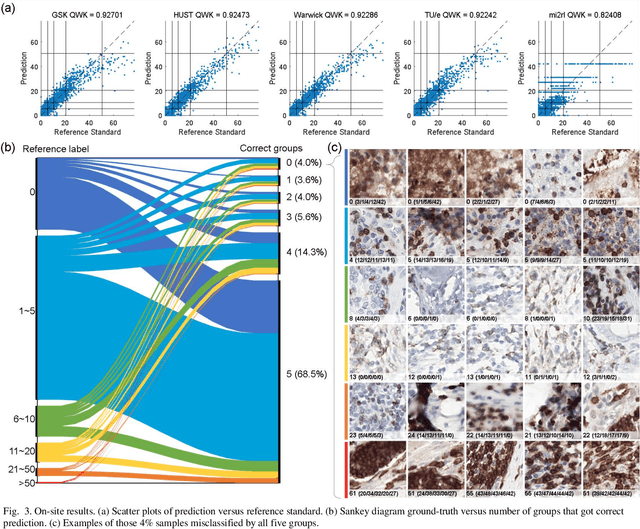
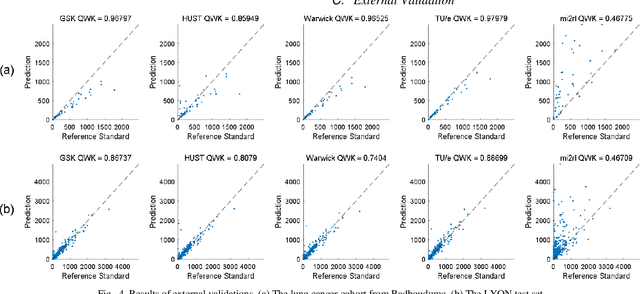
We introduce LYSTO, the Lymphocyte Assessment Hackathon, which was held in conjunction with the MICCAI 2019 Conference in Shenzen (China). The competition required participants to automatically assess the number of lymphocytes, in particular T-cells, in histopathological images of colon, breast, and prostate cancer stained with CD3 and CD8 immunohistochemistry. Differently from other challenges setup in medical image analysis, LYSTO participants were solely given a few hours to address this problem. In this paper, we describe the goal and the multi-phase organization of the hackathon; we describe the proposed methods and the on-site results. Additionally, we present post-competition results where we show how the presented methods perform on an independent set of lung cancer slides, which was not part of the initial competition, as well as a comparison on lymphocyte assessment between presented methods and a panel of pathologists. We show that some of the participants were capable to achieve pathologist-level performance at lymphocyte assessment. After the hackathon, LYSTO was left as a lightweight plug-and-play benchmark dataset on grand-challenge website, together with an automatic evaluation platform. LYSTO has supported a number of research in lymphocyte assessment in oncology. LYSTO will be a long-lasting educational challenge for deep learning and digital pathology, it is available at https://lysto.grand-challenge.org/.
Nuclear Segmentation and Classification: On Color & Compression Generalization
Jan 09, 2023Since the introduction of digital and computational pathology as a field, one of the major problems in the clinical application of algorithms has been the struggle to generalize well to examples outside the distribution of the training data. Existing work to address this in both pathology and natural images has focused almost exclusively on classification tasks. We explore and evaluate the robustness of the 7 best performing nuclear segmentation and classification models from the largest computational pathology challenge for this problem to date, the CoNIC challenge. We demonstrate that existing state-of-the-art (SoTA) models are robust towards compression artifacts but suffer substantial performance reduction when subjected to shifts in the color domain. We find that using stain normalization to address the domain shift problem can be detrimental to the model performance. On the other hand, neural style transfer is more consistent in improving test performance when presented with large color variations in the wild.
CAMANet: Class Activation Map Guided Attention Network for Radiology Report Generation
Nov 02, 2022Radiology report generation (RRG) has gained increasing research attention because of its huge potential to mitigate medical resource shortages and aid the process of disease decision making by radiologists. Recent advancements in Radiology Report Generation (RRG) are largely driven by improving models' capabilities in encoding single-modal feature representations, while few studies explore explicitly the cross-modal alignment between image regions and words. Radiologists typically focus first on abnormal image regions before they compose the corresponding text descriptions, thus cross-modal alignment is of great importance to learn an abnormality-aware RRG model. Motivated by this, we propose a Class Activation Map guided Attention Network (CAMANet) which explicitly promotes cross-modal alignment by employing the aggregated class activation maps to supervise the cross-modal attention learning, and simultaneously enriches the discriminative information. Experimental results demonstrate that CAMANet outperforms previous SOTA methods on two commonly used RRG benchmarks.