 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTX-Search: Explanation Search for Continuous Dynamic Spatio-Temporal Models
Mar 06, 2025



Recent improvements in the expressive power of spatio-temporal models have led to performance gains in many real-world applications, such as traffic forecasting and social network modelling. However, understanding the predictions from a model is crucial to ensure reliability and trustworthiness, particularly for high-risk applications, such as healthcare and transport. Few existing methods are able to generate explanations for models trained on continuous-time dynamic graph data and, of these, the computational complexity and lack of suitable explanation objectives pose challenges. In this paper, we propose $\textbf{S}$patio-$\textbf{T}$emporal E$\textbf{X}$planation $\textbf{Search}$ (STX-Search), a novel method for generating instance-level explanations that is applicable to static and dynamic temporal graph structures. We introduce a novel search strategy and objective function, to find explanations that are highly faithful and interpretable. When compared with existing methods, STX-Search produces explanations of higher fidelity whilst optimising explanation size to maintain interpretability.
MASALA: Model-Agnostic Surrogate Explanations by Locality Adaptation
Aug 19, 2024



Existing local Explainable AI (XAI) methods, such as LIME, select a region of the input space in the vicinity of a given input instance, for which they approximate the behaviour of a model using a simpler and more interpretable surrogate model. The size of this region is often controlled by a user-defined locality hyperparameter. In this paper, we demonstrate the difficulties associated with defining a suitable locality size to capture impactful model behaviour, as well as the inadequacy of using a single locality size to explain all predictions. We propose a novel method, MASALA, for generating explanations, which automatically determines the appropriate local region of impactful model behaviour for each individual instance being explained. MASALA approximates the local behaviour used by a complex model to make a prediction by fitting a linear surrogate model to a set of points which experience similar model behaviour. These points are found by clustering the input space into regions of linear behavioural trends exhibited by the model. We compare the fidelity and consistency of explanations generated by our method with existing local XAI methods, namely LIME and CHILLI. Experiments on the PHM08 and MIDAS datasets show that our method produces more faithful and consistent explanations than existing methods, without the need to define any sensitive locality hyperparameters.
CHILLI: A data context-aware perturbation method for XAI
Jul 10, 2024



The trustworthiness of Machine Learning (ML) models can be difficult to assess, but is critical in high-risk or ethically sensitive applications. Many models are treated as a `black-box' where the reasoning or criteria for a final decision is opaque to the user. To address this, some existing Explainable AI (XAI) approaches approximate model behaviour using perturbed data. However, such methods have been criticised for ignoring feature dependencies, with explanations being based on potentially unrealistic data. We propose a novel framework, CHILLI, for incorporating data context into XAI by generating contextually aware perturbations, which are faithful to the training data of the base model being explained. This is shown to improve both the soundness and accuracy of the explanations.
Conceptually Diverse Base Model Selection for Meta-Learners in Concept Drifting Data Streams
Nov 29, 2021
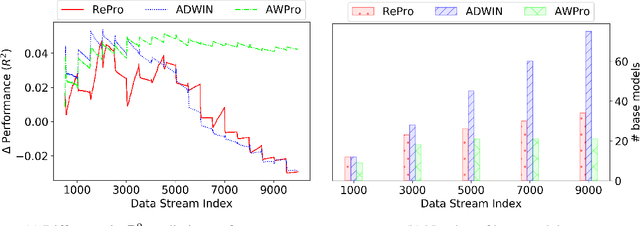

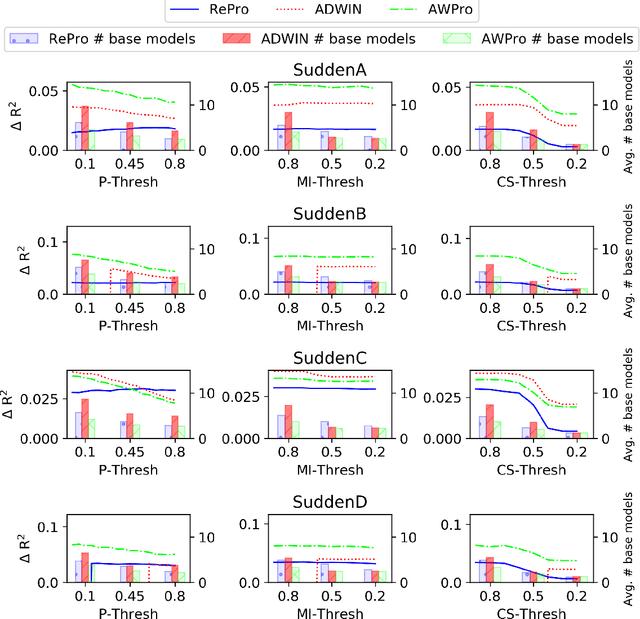
Meta-learners and ensembles aim to combine a set of relevant yet diverse base models to improve predictive performance. However, determining an appropriate set of base models is challenging, especially in online environments where the underlying distribution of data can change over time. In this paper, we present a novel approach for estimating the conceptual similarity of base models, which is calculated using the Principal Angles (PAs) between their underlying subspaces. We propose two methods that use conceptual similarity as a metric to obtain a relevant yet diverse subset of base models: (i) parameterised threshold culling and (ii) parameterless conceptual clustering. We evaluate these methods against thresholding using common ensemble pruning metrics, namely predictive performance and Mutual Information (MI), in the context of online Transfer Learning (TL), using both synthetic and real-world data. Our results show that conceptual similarity thresholding has a reduced computational overhead, and yet yields comparable predictive performance to thresholding using predictive performance and MI. Furthermore, conceptual clustering achieves similar predictive performances without requiring parameterisation, and achieves this with lower computational overhead than thresholding using predictive performance and MI when the number of base models becomes large.
Explaining reputation assessments
Jun 15, 2020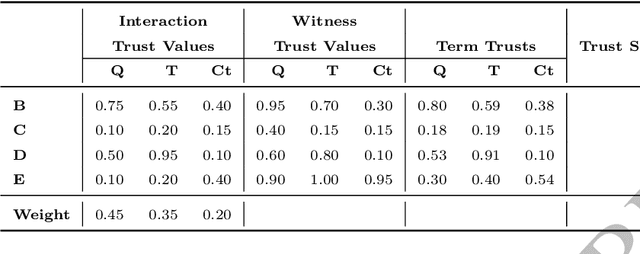


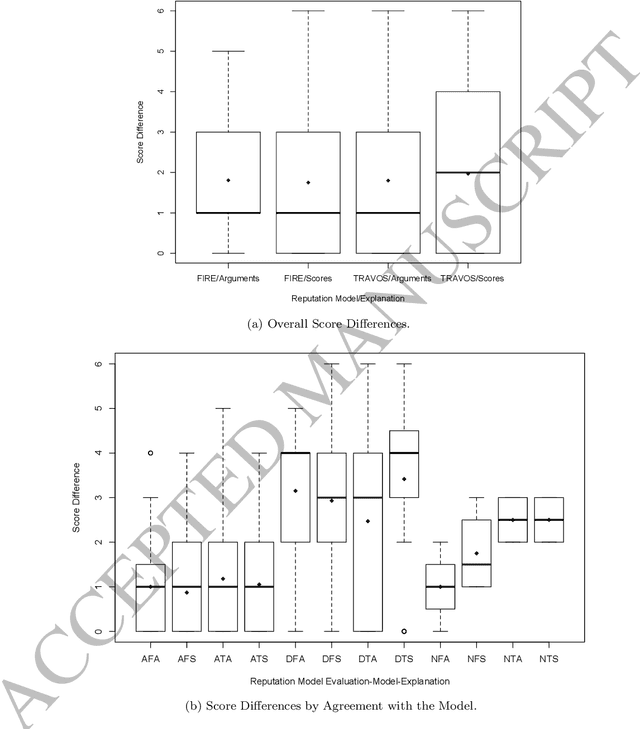
Reputation is crucial to enabling human or software agents to select among alternative providers. Although several effective reputation assessment methods exist, they typically distil reputation into a numerical representation, with no accompanying explanation of the rationale behind the assessment. Such explanations would allow users or clients to make a richer assessment of providers, and tailor selection according to their preferences and current context. In this paper, we propose an approach to explain the rationale behind assessments from quantitative reputation models, by generating arguments that are combined to form explanations. Our approach adapts, extends and combines existing approaches for explaining decisions made using multi-attribute decision models in the context of reputation. We present example argument templates, and describe how to select their parameters using explanation algorithms. Our proposal was evaluated by means of a user study, which followed an existing protocol. Our results give evidence that although explanations present a subset of the information of trust scores, they are sufficient to equally evaluate providers recommended based on their trust score. Moreover, when explanation arguments reveal implicit model information, they are less persuasive than scores.
The Predictive Context Tree: Predicting Contexts and Interactions
Oct 05, 2016



With a large proportion of people carrying location-aware smartphones, we have an unprecedented platform from which to understand individuals and predict their future actions. This work builds upon the Context Tree data structure that summarises the historical contexts of individuals from augmented geospatial trajectories, and constructs a predictive model for their likely future contexts. The Predictive Context Tree (PCT) is constructed as a hierarchical classifier, capable of predicting both the future locations that a user will visit and the contexts that a user will be immersed within. The PCT is evaluated over real-world geospatial trajectories, and compared against existing location extraction and prediction techniques, as well as a proposed hybrid approach that uses identified land usage elements in combination with machine learning to predict future interactions. Our results demonstrate that higher predictive accuracies can be achieved using this hybrid approach over traditional extracted location datasets, and the PCT itself matches the performance of the hybrid approach at predicting future interactions, while adding utility in the form of context predictions. Such a prediction system is capable of understanding not only where a user will visit, but also their context, in terms of what they are likely to be doing.
Context Trees: Augmenting Geospatial Trajectories with Context
Jun 14, 2016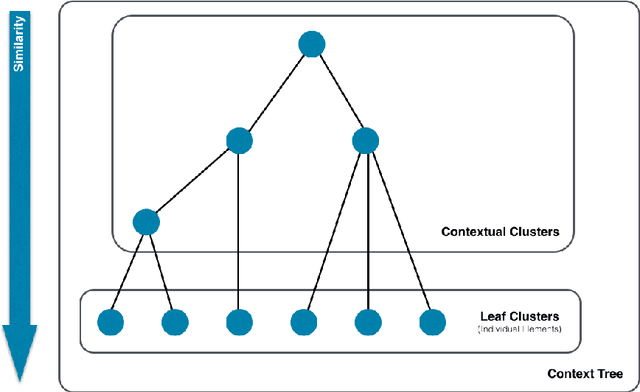
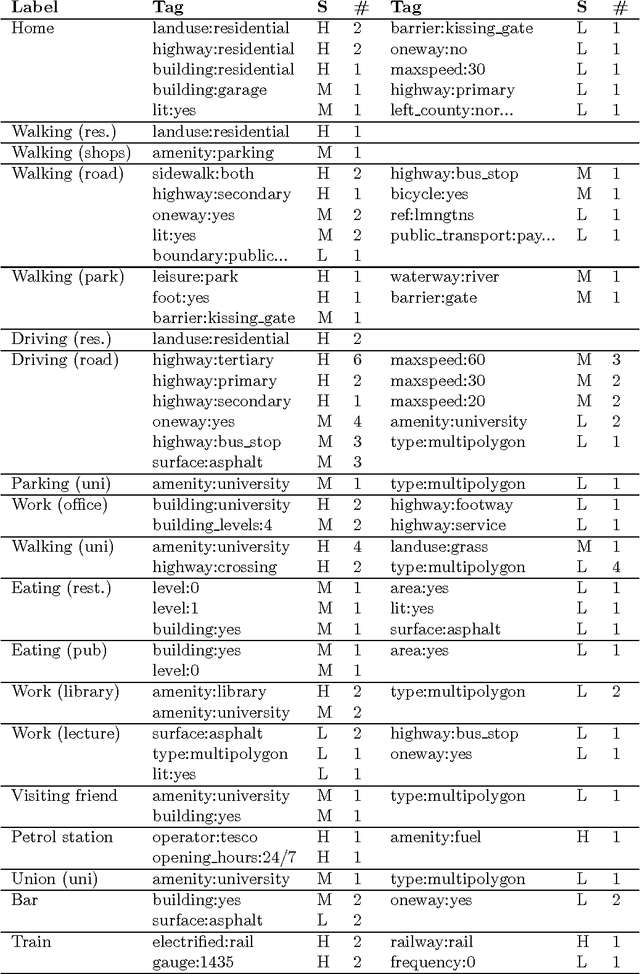
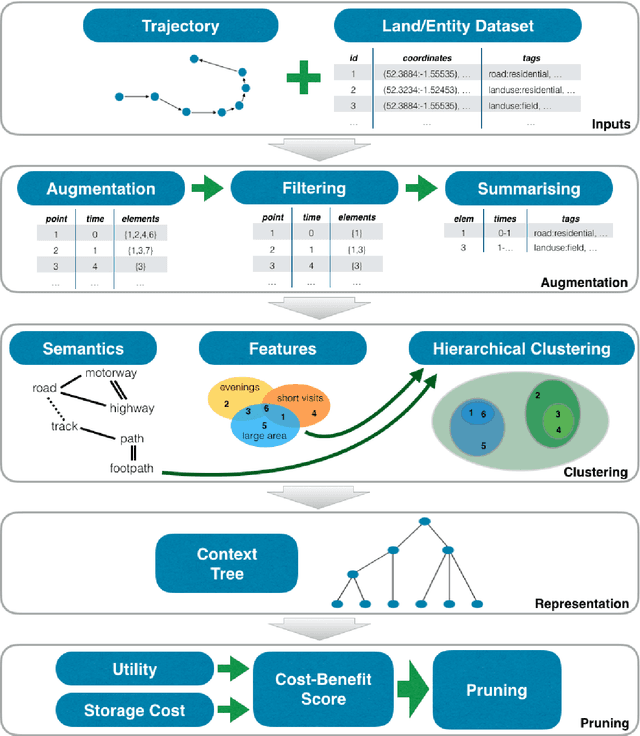
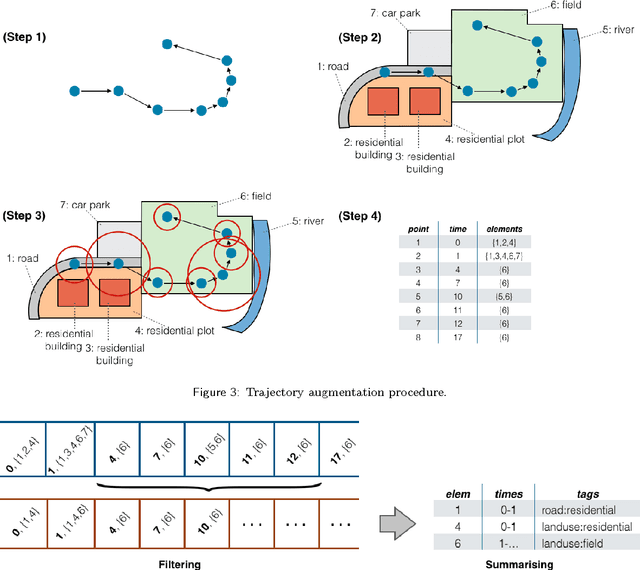
Exposing latent knowledge in geospatial trajectories has the potential to provide a better understanding of the movements of individuals and groups. Motivated by such a desire, this work presents the context tree, a new hierarchical data structure that summarises the context behind user actions in a single model. We propose a method for context tree construction that augments geospatial trajectories with land usage data to identify such contexts. Through evaluation of the construction method and analysis of the properties of generated context trees, we demonstrate the foundation for understanding and modelling behaviour afforded. Summarising user contexts into a single data structure gives easy access to information that would otherwise remain latent, providing the basis for better understanding and predicting the actions and behaviours of individuals and groups. Finally, we also present a method for pruning context trees, for use in applications where it is desirable to reduce the size of the tree while retaining useful information.