 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBuilding a Legal Dialogue System: Development Process, Challenges and Opportunities
Sep 01, 2021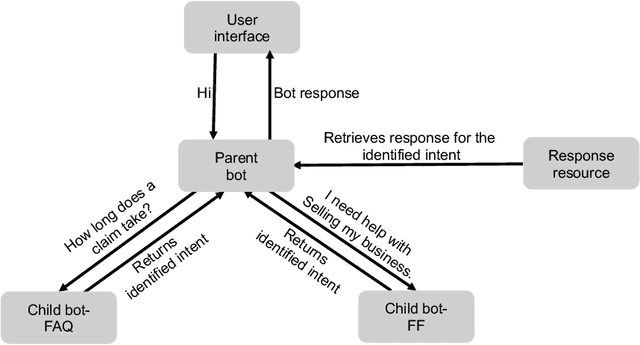

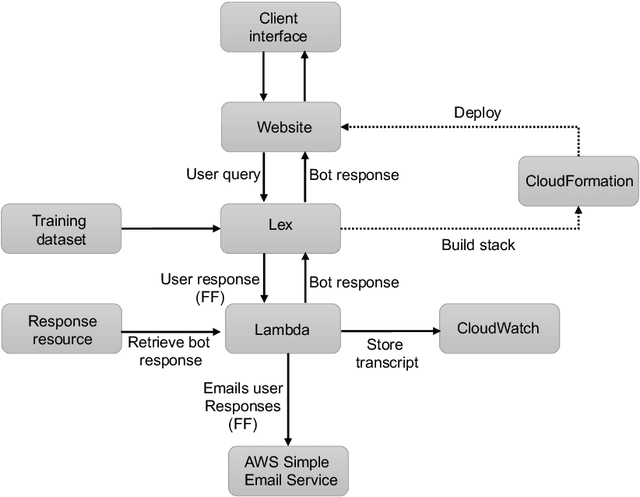
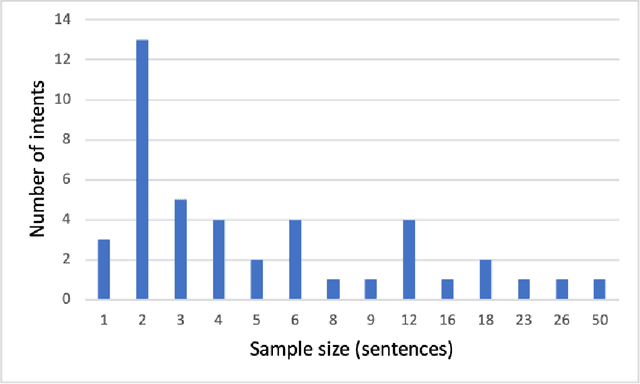
This paper presents key principles and solutions to the challenges faced in designing a domain-specific conversational agent for the legal domain. It includes issues of scope, platform, architecture and preparation of input data. It provides functionality in answering user queries and recording user information including contact details and case-related information. It utilises deep learning technology built upon Amazon Web Services (AWS) LEX in combination with AWS Lambda. Due to lack of publicly available data, we identified two methods including crowdsourcing experiments and archived enquiries to develop a number of linguistic resources. This includes a training dataset, set of predetermined responses for the conversational agent, a set of regression test cases and a further conversation test set. We propose a hierarchical bot structure that facilitates multi-level delegation and report model accuracy on the regression test set. Additionally, we highlight features that are added to the bot to improve the conversation flow and overall user experience.
Explaining reputation assessments
Jun 15, 2020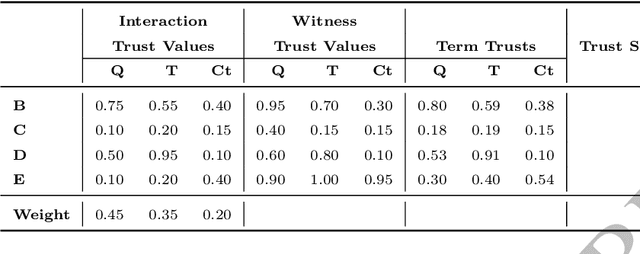


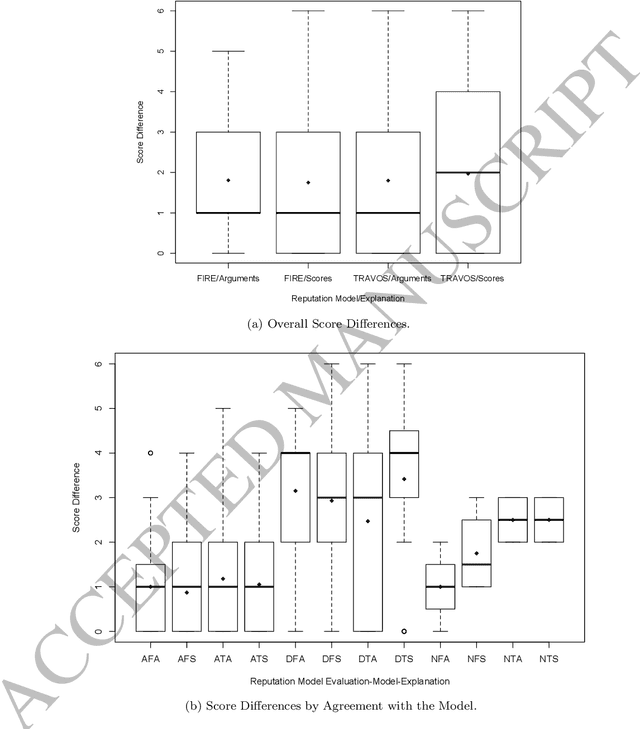
Reputation is crucial to enabling human or software agents to select among alternative providers. Although several effective reputation assessment methods exist, they typically distil reputation into a numerical representation, with no accompanying explanation of the rationale behind the assessment. Such explanations would allow users or clients to make a richer assessment of providers, and tailor selection according to their preferences and current context. In this paper, we propose an approach to explain the rationale behind assessments from quantitative reputation models, by generating arguments that are combined to form explanations. Our approach adapts, extends and combines existing approaches for explaining decisions made using multi-attribute decision models in the context of reputation. We present example argument templates, and describe how to select their parameters using explanation algorithms. Our proposal was evaluated by means of a user study, which followed an existing protocol. Our results give evidence that although explanations present a subset of the information of trust scores, they are sufficient to equally evaluate providers recommended based on their trust score. Moreover, when explanation arguments reveal implicit model information, they are less persuasive than scores.