 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConceptually Diverse Base Model Selection for Meta-Learners in Concept Drifting Data Streams
Nov 29, 2021
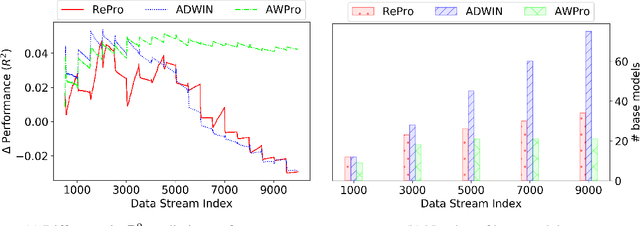

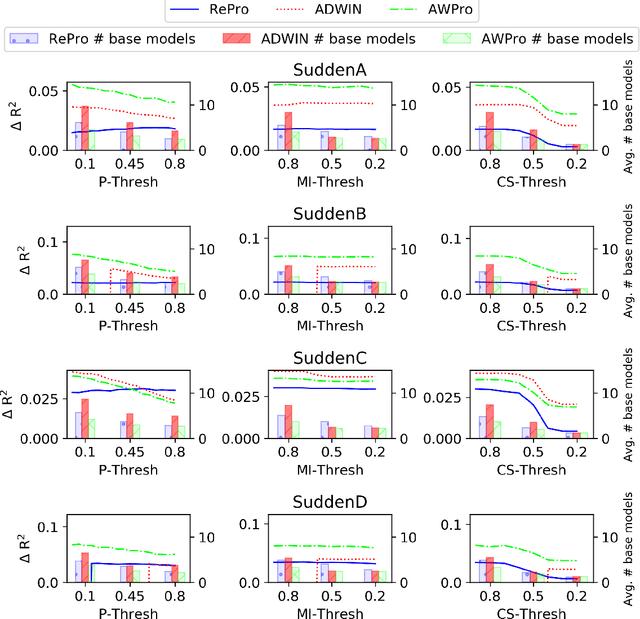
Meta-learners and ensembles aim to combine a set of relevant yet diverse base models to improve predictive performance. However, determining an appropriate set of base models is challenging, especially in online environments where the underlying distribution of data can change over time. In this paper, we present a novel approach for estimating the conceptual similarity of base models, which is calculated using the Principal Angles (PAs) between their underlying subspaces. We propose two methods that use conceptual similarity as a metric to obtain a relevant yet diverse subset of base models: (i) parameterised threshold culling and (ii) parameterless conceptual clustering. We evaluate these methods against thresholding using common ensemble pruning metrics, namely predictive performance and Mutual Information (MI), in the context of online Transfer Learning (TL), using both synthetic and real-world data. Our results show that conceptual similarity thresholding has a reduced computational overhead, and yet yields comparable predictive performance to thresholding using predictive performance and MI. Furthermore, conceptual clustering achieves similar predictive performances without requiring parameterisation, and achieves this with lower computational overhead than thresholding using predictive performance and MI when the number of base models becomes large.
Explaining reputation assessments
Jun 15, 2020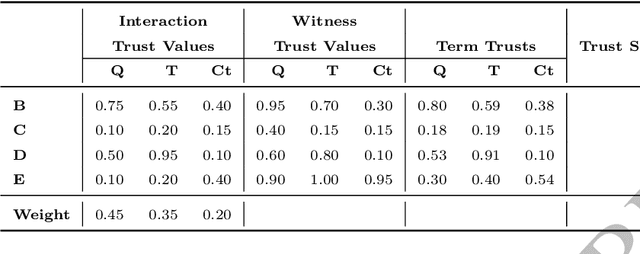


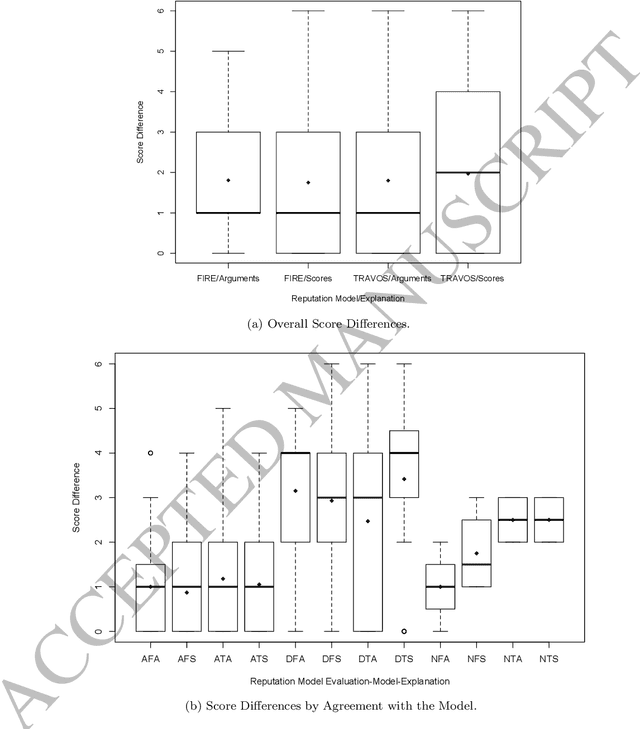
Reputation is crucial to enabling human or software agents to select among alternative providers. Although several effective reputation assessment methods exist, they typically distil reputation into a numerical representation, with no accompanying explanation of the rationale behind the assessment. Such explanations would allow users or clients to make a richer assessment of providers, and tailor selection according to their preferences and current context. In this paper, we propose an approach to explain the rationale behind assessments from quantitative reputation models, by generating arguments that are combined to form explanations. Our approach adapts, extends and combines existing approaches for explaining decisions made using multi-attribute decision models in the context of reputation. We present example argument templates, and describe how to select their parameters using explanation algorithms. Our proposal was evaluated by means of a user study, which followed an existing protocol. Our results give evidence that although explanations present a subset of the information of trust scores, they are sufficient to equally evaluate providers recommended based on their trust score. Moreover, when explanation arguments reveal implicit model information, they are less persuasive than scores.