 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTeam-related Features in Code Review Prediction Models
Dec 11, 2023Modern Code Review (MCR) is an informal tool-assisted quality assurance practice. It relies on the asynchronous communication among the authors of code changes and reviewers, who are developers that provide feedback. However, from candidate developers, some are able to provide better feedback than others given a particular context. The selection of reviewers is thus an important task, which can benefit from automated support. Many approaches have been proposed in this direction, using for example data from code review repositories to recommend reviewers. In this paper, we propose the use of team-related features to improve the performance of predictions that are helpful to build code reviewer recommenders, with our target predictions being the identification of reviewers that would participate in a review and the provided amount of feedback. We evaluate the prediction power of these features, which are related to code ownership, workload, and team relationship. This evaluation was done by carefully addressing challenges imposed by the MCR domain, such as temporal aspects of the dataset and unbalanced classes. Moreover, given that it is currently unknown how much past data is needed for building MCR prediction models with acceptable performance, we explore the amount of past data used to build prediction models. Our results show that, individually, features related to code ownership have the best prediction power. However, based on feature selection, we conclude that all proposed features together with lines of code can make the best predictions for both reviewer participation and amount of feedback. Regarding the amount of past data, the timeframes of 3, 6, 9, and 12 months of data produce similar results. Therefore, models can be trained considering short timeframes, thus reducing the computational costs with negligible impact in the prediction performance ...
Quantitatively Assessing the Benefits of Model-driven Development in Agent-based Modeling and Simulation
Jun 15, 2020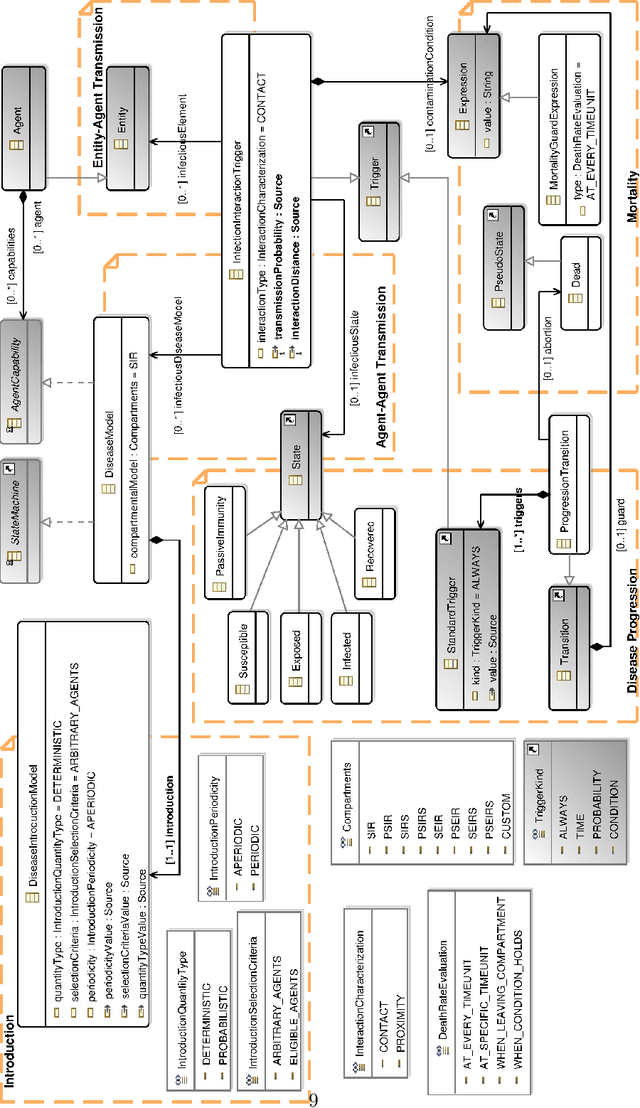
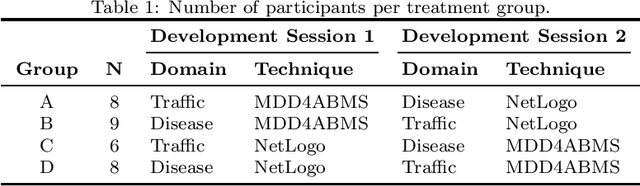
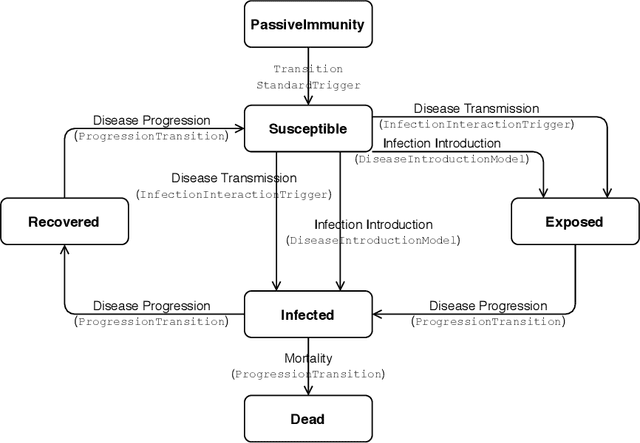
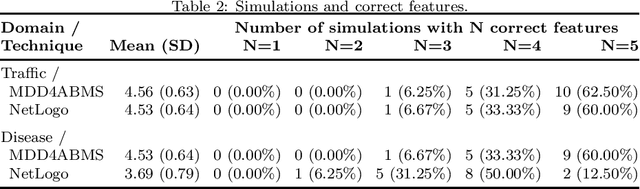
The agent-based modeling and simulation (ABMS) paradigm has been used to analyze, reproduce, and predict phenomena related to many application areas. Although there are many agent-based platforms that support simulation development, they rely on programming languages that require extensive programming knowledge. Model-driven development (MDD) has been explored to facilitate simulation modeling, by means of high-level modeling languages that provide reusable building blocks that hide computational complexity, and code generation. However, there is still limited knowledge of how MDD approaches to ABMS contribute to increasing development productivity and quality. We thus in this paper present an empirical study that quantitatively compares the use of MDD and ABMS platforms mainly in terms of effort and developer mistakes. Our evaluation was performed using MDD4ABMS-an MDD approach with a core and extensions to two application areas, one of which developed for this study-and NetLogo, a widely used platform. The obtained results show that MDD4ABMS requires less effort to develop simulations with similar (sometimes better) design quality than NetLogo, giving evidence of the benefits that MDD can provide to ABMS.
Explaining reputation assessments
Jun 15, 2020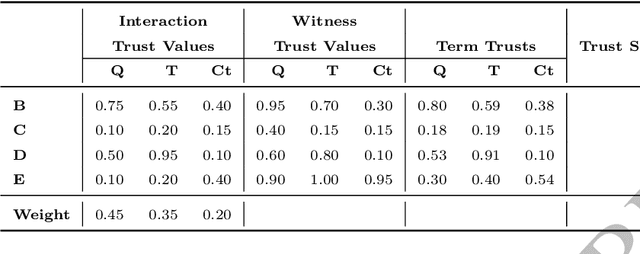


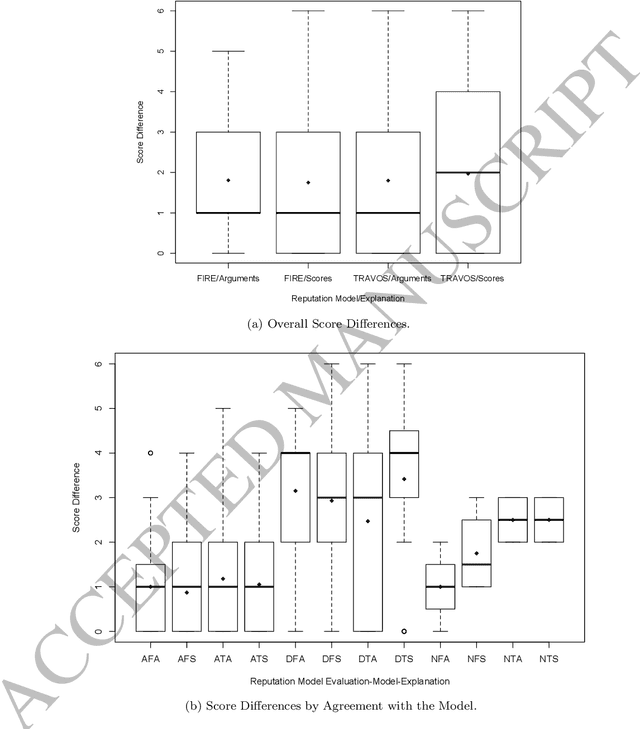
Reputation is crucial to enabling human or software agents to select among alternative providers. Although several effective reputation assessment methods exist, they typically distil reputation into a numerical representation, with no accompanying explanation of the rationale behind the assessment. Such explanations would allow users or clients to make a richer assessment of providers, and tailor selection according to their preferences and current context. In this paper, we propose an approach to explain the rationale behind assessments from quantitative reputation models, by generating arguments that are combined to form explanations. Our approach adapts, extends and combines existing approaches for explaining decisions made using multi-attribute decision models in the context of reputation. We present example argument templates, and describe how to select their parameters using explanation algorithms. Our proposal was evaluated by means of a user study, which followed an existing protocol. Our results give evidence that although explanations present a subset of the information of trust scores, they are sufficient to equally evaluate providers recommended based on their trust score. Moreover, when explanation arguments reveal implicit model information, they are less persuasive than scores.
A systematic review and taxonomy of explanations in decision support and recommender systems
Jun 15, 2020
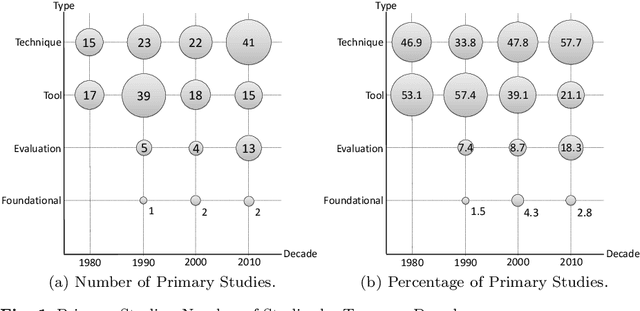

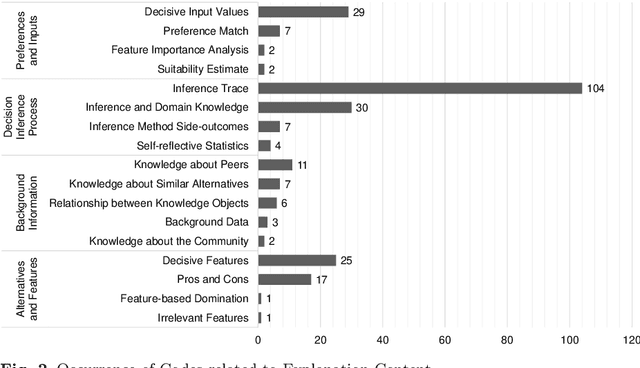
With the recent advances in the field of artificial intelligence, an increasing number of decision-making tasks are delegated to software systems. A key requirement for the success and adoption of such systems is that users must trust system choices or even fully automated decisions. To achieve this, explanation facilities have been widely investigated as a means of establishing trust in these systems since the early years of expert systems. With today's increasingly sophisticated machine learning algorithms, new challenges in the context of explanations, accountability, and trust towards such systems constantly arise. In this work, we systematically review the literature on explanations in advice-giving systems. This is a family of systems that includes recommender systems, which is one of the most successful classes of advice-giving software in practice. We investigate the purposes of explanations as well as how they are generated, presented to users, and evaluated. As a result, we derive a novel comprehensive taxonomy of aspects to be considered when designing explanation facilities for current and future decision support systems. The taxonomy includes a variety of different facets, such as explanation objective, responsiveness, content and presentation. Moreover, we identified several challenges that remain unaddressed so far, for example related to fine-grained issues associated with the presentation of explanations and how explanation facilities are evaluated.