 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBuilding a Legal Dialogue System: Development Process, Challenges and Opportunities
Sep 01, 2021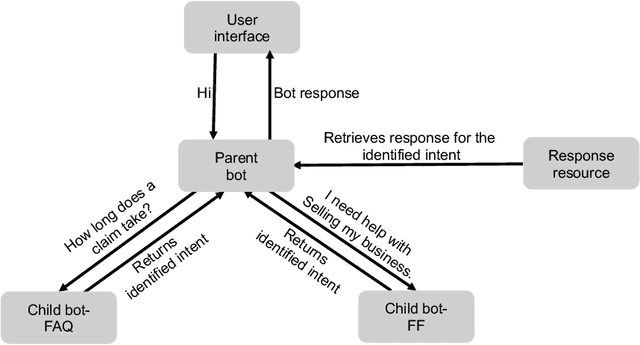

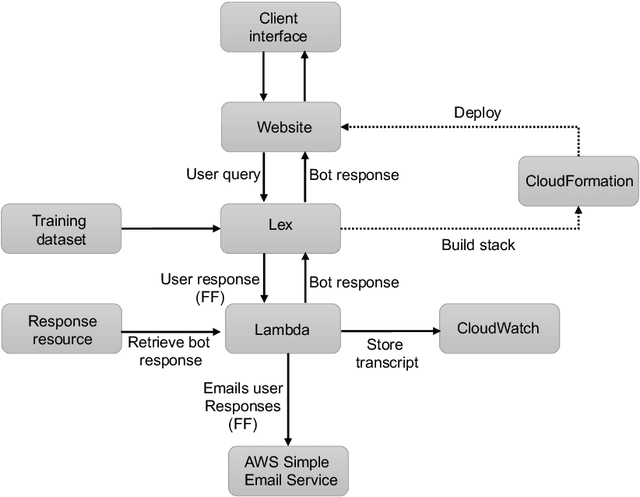
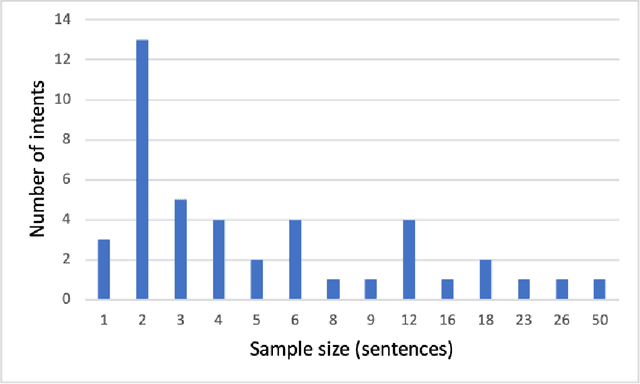
This paper presents key principles and solutions to the challenges faced in designing a domain-specific conversational agent for the legal domain. It includes issues of scope, platform, architecture and preparation of input data. It provides functionality in answering user queries and recording user information including contact details and case-related information. It utilises deep learning technology built upon Amazon Web Services (AWS) LEX in combination with AWS Lambda. Due to lack of publicly available data, we identified two methods including crowdsourcing experiments and archived enquiries to develop a number of linguistic resources. This includes a training dataset, set of predetermined responses for the conversational agent, a set of regression test cases and a further conversation test set. We propose a hierarchical bot structure that facilitates multi-level delegation and report model accuracy on the regression test set. Additionally, we highlight features that are added to the bot to improve the conversation flow and overall user experience.
Unified Framework for the Adaptive Operator Selection of Discrete Parameters
May 12, 2020

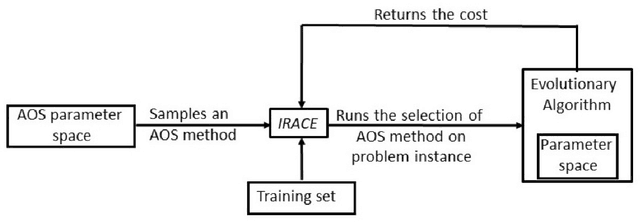
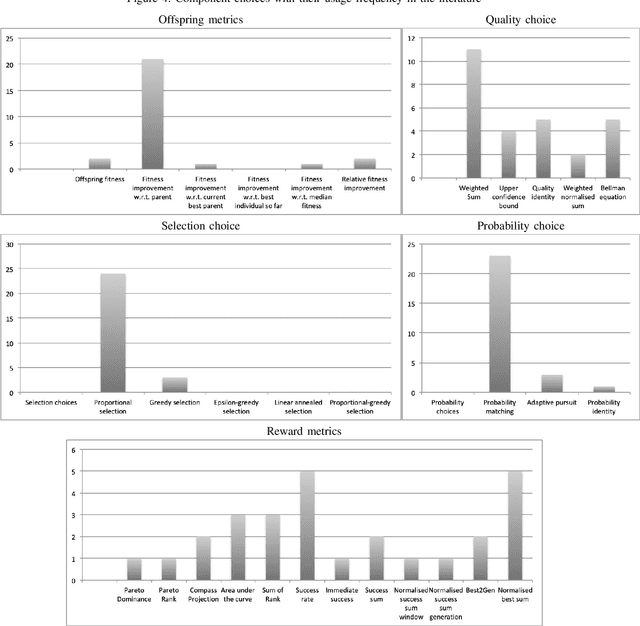
We conduct an exhaustive survey of adaptive selection of operators (AOS) in Evolutionary Algorithms (EAs). We simplified the AOS structure by adding more components to the framework to built upon the existing categorisation of AOS methods. In addition to simplifying, we looked at the commonality among AOS methods from literature to generalise them. Each component is presented with a number of alternative choices, each represented with a formula. We make three sets of comparisons. First, the methods from literature are tested on the BBOB test bed with their default hyper parameters. Second, the hyper parameters of these methods are tuned using an offline configurator known as IRACE. Third, for a given set of problems, we use IRACE to select the best combination of components and tune their hyper parameters.
Deep Reinforcement Learning Based Parameter Control in Differential Evolution
May 20, 2019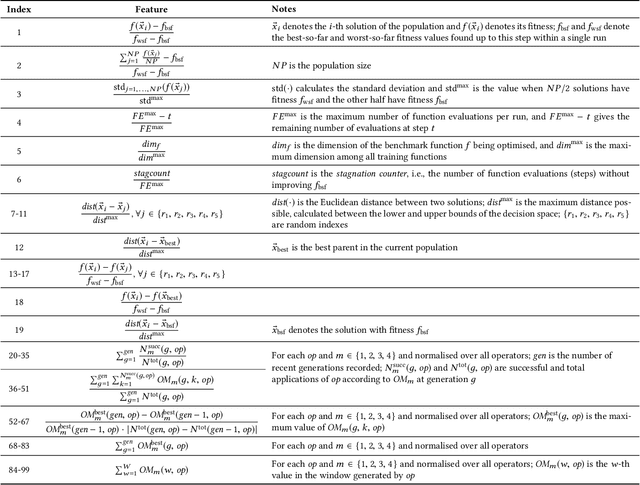

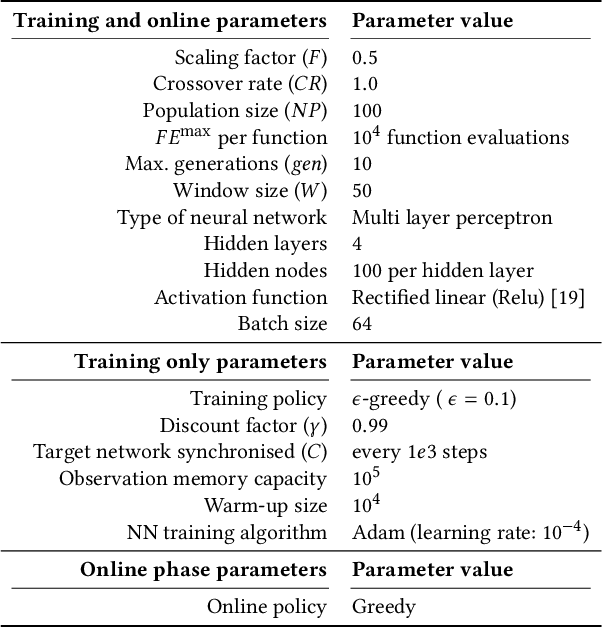

Adaptive Operator Selection (AOS) is an approach that controls discrete parameters of an Evolutionary Algorithm (EA) during the run. In this paper, we propose an AOS method based on Double Deep Q-Learning (DDQN), a Deep Reinforcement Learning method, to control the mutation strategies of Differential Evolution (DE). The application of DDQN to DE requires two phases. First, a neural network is trained offline by collecting data about the DE state and the benefit (reward) of applying each mutation strategy during multiple runs of DE tackling benchmark functions. We define the DE state as the combination of 99 different features and we analyze three alternative reward functions. Second, when DDQN is applied as a parameter controller within DE to a different test set of benchmark functions, DDQN uses the trained neural network to predict which mutation strategy should be applied to each parent at each generation according to the DE state. Benchmark functions for training and testing are taken from the CEC2005 benchmark with dimensions 10 and 30. We compare the results of the proposed DE-DDQN algorithm to several baseline DE algorithms using no online selection, random selection and other AOS methods, and also to the two winners of the CEC2005 competition. The results show that DE-DDQN outperforms the non-adaptive methods for all functions in the test set; while its results are comparable with the last two algorithms.