 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStainFuser: Controlling Diffusion for Faster Neural Style Transfer in Multi-Gigapixel Histology Images
Mar 14, 2024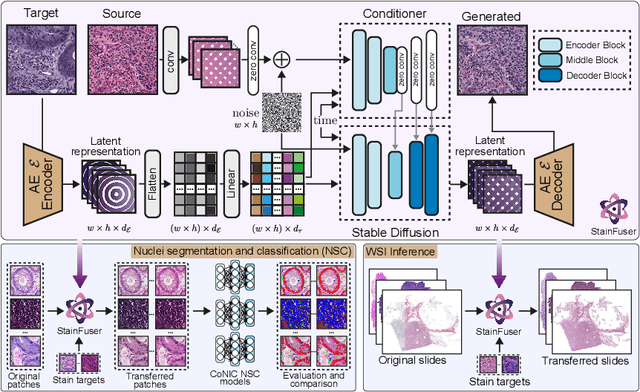

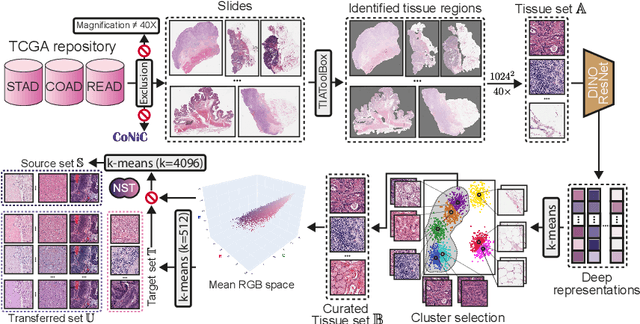
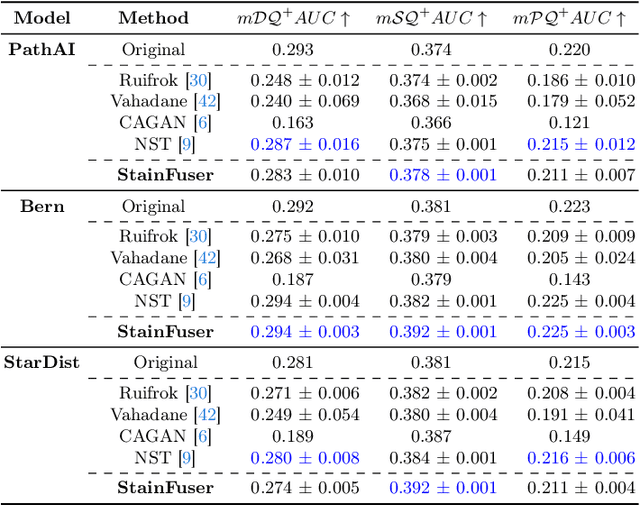
Stain normalization algorithms aim to transform the color and intensity characteristics of a source multi-gigapixel histology image to match those of a target image, mitigating inconsistencies in the appearance of stains used to highlight cellular components in the images. We propose a new approach, StainFuser, which treats this problem as a style transfer task using a novel Conditional Latent Diffusion architecture, eliminating the need for handcrafted color components. With this method, we curate SPI-2M the largest stain normalization dataset to date of over 2 million histology images with neural style transfer for high-quality transformations. Trained on this data, StainFuser outperforms current state-of-the-art GAN and handcrafted methods in terms of the quality of normalized images. Additionally, compared to existing approaches, it improves the performance of nuclei instance segmentation and classification models when used as a test time augmentation method on the challenging CoNIC dataset. Finally, we apply StainFuser on multi-gigapixel Whole Slide Images (WSIs) and demonstrate improved performance in terms of computational efficiency, image quality and consistency across tiles over current methods.
Nuclear Segmentation and Classification: On Color & Compression Generalization
Jan 09, 2023Since the introduction of digital and computational pathology as a field, one of the major problems in the clinical application of algorithms has been the struggle to generalize well to examples outside the distribution of the training data. Existing work to address this in both pathology and natural images has focused almost exclusively on classification tasks. We explore and evaluate the robustness of the 7 best performing nuclear segmentation and classification models from the largest computational pathology challenge for this problem to date, the CoNIC challenge. We demonstrate that existing state-of-the-art (SoTA) models are robust towards compression artifacts but suffer substantial performance reduction when subjected to shifts in the color domain. We find that using stain normalization to address the domain shift problem can be detrimental to the model performance. On the other hand, neural style transfer is more consistent in improving test performance when presented with large color variations in the wild.
An Aggregation of Aggregation Methods in Computational Pathology
Nov 02, 2022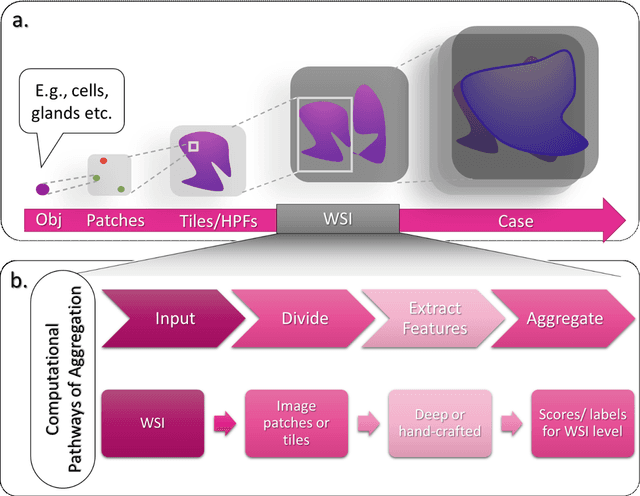
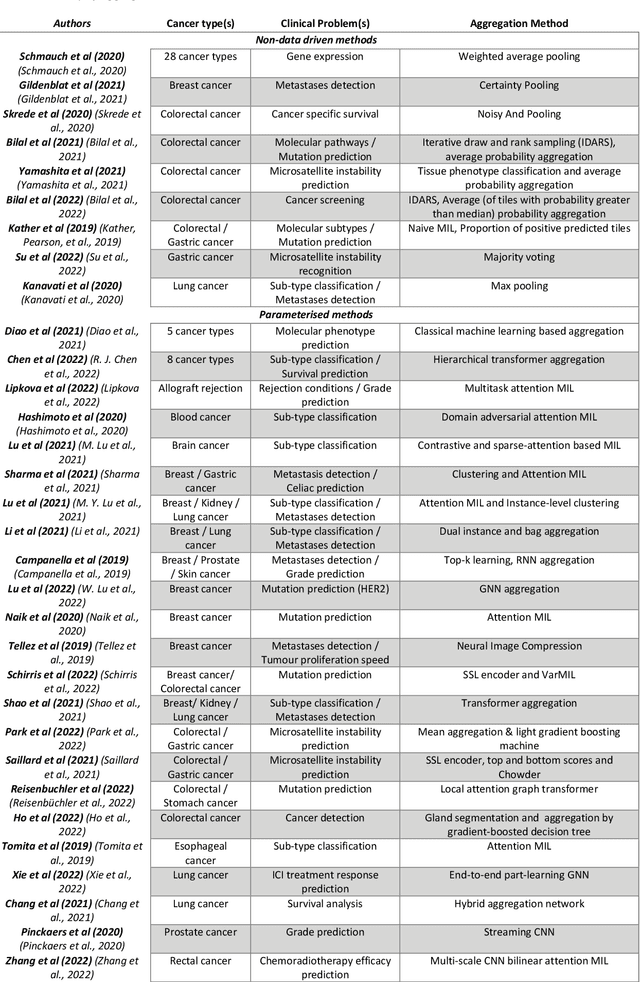
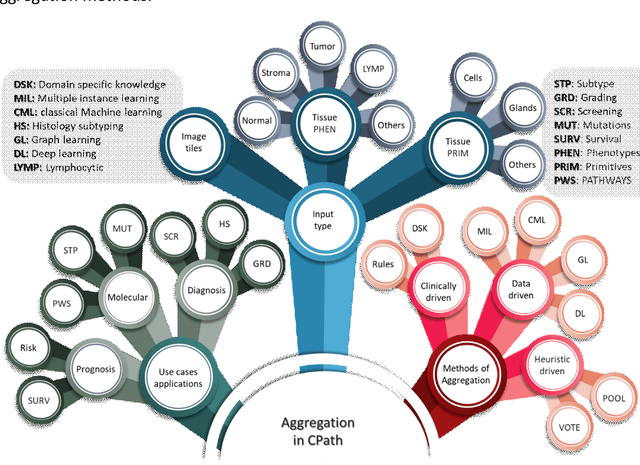
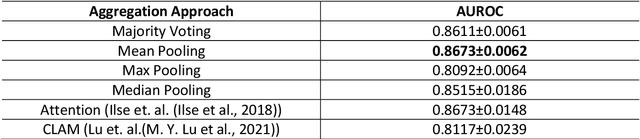
Image analysis and machine learning algorithms operating on multi-gigapixel whole-slide images (WSIs) often process a large number of tiles (sub-images) and require aggregating predictions from the tiles in order to predict WSI-level labels. In this paper, we present a review of existing literature on various types of aggregation methods with a view to help guide future research in the area of computational pathology (CPath). We propose a general CPath workflow with three pathways that consider multiple levels and types of data and the nature of computation to analyse WSIs for predictive modelling. We categorize aggregation methods according to the context and representation of the data, features of computational modules and CPath use cases. We compare and contrast different methods based on the principle of multiple instance learning, perhaps the most commonly used aggregation method, covering a wide range of CPath literature. To provide a fair comparison, we consider a specific WSI-level prediction task and compare various aggregation methods for that task. Finally, we conclude with a list of objectives and desirable attributes of aggregation methods in general, pros and cons of the various approaches, some recommendations and possible future directions.