 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models
Aug 08, 2025We present GLM-4.5, an open-source Mixture-of-Experts (MoE) large language model with 355B total parameters and 32B activated parameters, featuring a hybrid reasoning method that supports both thinking and direct response modes. Through multi-stage training on 23T tokens and comprehensive post-training with expert model iteration and reinforcement learning, GLM-4.5 achieves strong performance across agentic, reasoning, and coding (ARC) tasks, scoring 70.1% on TAU-Bench, 91.0% on AIME 24, and 64.2% on SWE-bench Verified. With much fewer parameters than several competitors, GLM-4.5 ranks 3rd overall among all evaluated models and 2nd on agentic benchmarks. We release both GLM-4.5 (355B parameters) and a compact version, GLM-4.5-Air (106B parameters), to advance research in reasoning and agentic AI systems. Code, models, and more information are available at https://github.com/zai-org/GLM-4.5.
EvolvTrip: Enhancing Literary Character Understanding with Temporal Theory-of-Mind Graphs
Jun 16, 2025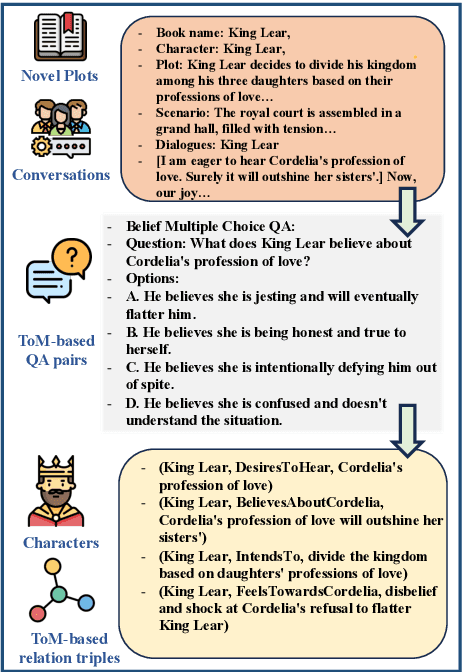
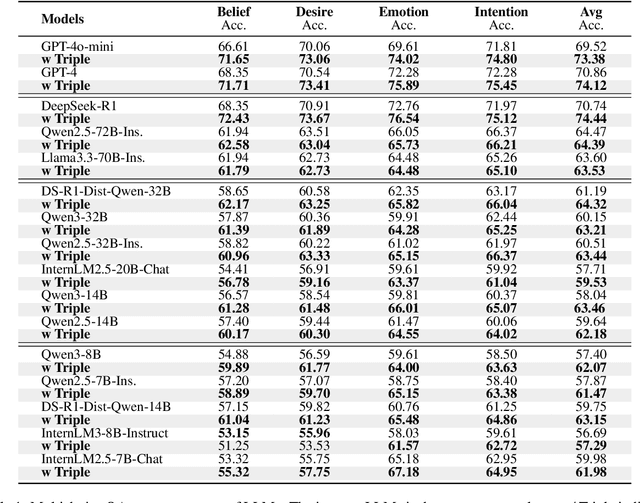
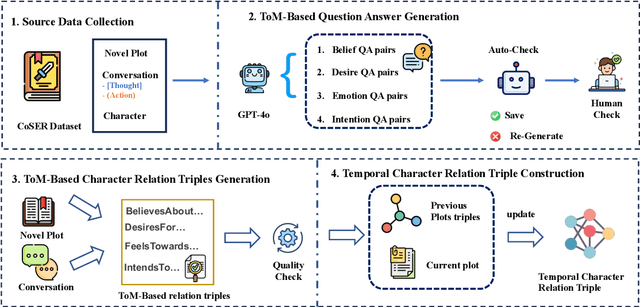
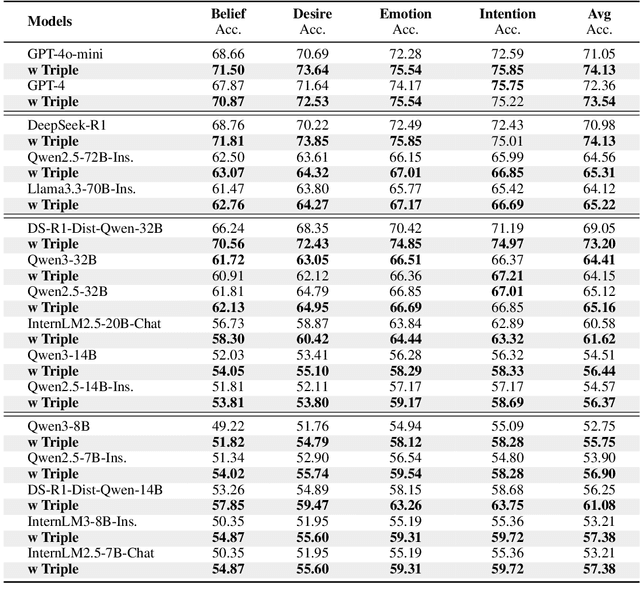
A compelling portrayal of characters is essential to the success of narrative writing. For readers, appreciating a character's traits requires the ability to infer their evolving beliefs, desires, and intentions over the course of a complex storyline, a cognitive skill known as Theory-of-Mind (ToM). Performing ToM reasoning in prolonged narratives requires readers to integrate historical context with current narrative information, a task at which humans excel but Large Language Models (LLMs) often struggle. To systematically evaluate LLMs' ToM reasoning capability in long narratives, we construct LitCharToM, a benchmark of character-centric questions across four ToM dimensions from classic literature. Further, we introduce EvolvTrip, a perspective-aware temporal knowledge graph that tracks psychological development throughout narratives. Our experiments demonstrate that EvolvTrip consistently enhances performance of LLMs across varying scales, even in challenging extended-context scenarios. EvolvTrip proves to be particularly valuable for smaller models, partially bridging the performance gap with larger LLMs and showing great compatibility with lengthy narratives. Our findings highlight the importance of explicit representation of temporal character mental states in narrative comprehension and offer a foundation for more sophisticated character understanding. Our data and code are publicly available at https://github.com/Bernard-Yang/EvolvTrip.
A Survey on Large Language Models in Multimodal Recommender Systems
May 14, 2025Multimodal recommender systems (MRS) integrate heterogeneous user and item data, such as text, images, and structured information, to enhance recommendation performance. The emergence of large language models (LLMs) introduces new opportunities for MRS by enabling semantic reasoning, in-context learning, and dynamic input handling. Compared to earlier pre-trained language models (PLMs), LLMs offer greater flexibility and generalisation capabilities but also introduce challenges related to scalability and model accessibility. This survey presents a comprehensive review of recent work at the intersection of LLMs and MRS, focusing on prompting strategies, fine-tuning methods, and data adaptation techniques. We propose a novel taxonomy to characterise integration patterns, identify transferable techniques from related recommendation domains, provide an overview of evaluation metrics and datasets, and point to possible future directions. We aim to clarify the emerging role of LLMs in multimodal recommendation and support future research in this rapidly evolving field.
EnigmaToM: Improve LLMs' Theory-of-Mind Reasoning Capabilities with Neural Knowledge Base of Entity States
Mar 05, 2025



Theory-of-Mind (ToM), the ability to infer others' perceptions and mental states, is fundamental to human interaction but remains a challenging task for Large Language Models (LLMs). While existing ToM reasoning methods show promise with reasoning via perceptual perspective-taking, they often rely excessively on LLMs, reducing their efficiency and limiting their applicability to high-order ToM reasoning, which requires multi-hop reasoning about characters' beliefs. To address these issues, we present EnigmaToM, a novel neuro-symbolic framework that enhances ToM reasoning by integrating a Neural Knowledge Base of entity states (Enigma) for (1) a psychology-inspired iterative masking mechanism that facilitates accurate perspective-taking and (2) knowledge injection that elicits key entity information. Enigma generates structured representations of entity states, which construct spatial scene graphs -- leveraging spatial information as an inductive bias -- for belief tracking of various ToM orders and enhancing events with fine-grained entity state details. Experimental results on multiple benchmarks, including ToMi, HiToM, and FANToM, show that EnigmaToM significantly improves ToM reasoning across LLMs of varying sizes, particularly excelling in high-order reasoning scenarios.
Positional encoding is not the same as context: A study on positional encoding for Sequential recommendation
May 16, 2024The expansion of streaming media and e-commerce has led to a boom in recommendation systems, including Sequential recommendation systems, which consider the user's previous interactions with items. In recent years, research has focused on architectural improvements such as transformer blocks and feature extraction that can augment model information. Among these features are context and attributes. Of particular importance is the temporal footprint, which is often considered part of the context and seen in previous publications as interchangeable with positional information. Other publications use positional encodings with little attention to them. In this paper, we analyse positional encodings, showing that they provide relative information between items that are not inferable from the temporal footprint. Furthermore, we evaluate different encodings and how they affect metrics and stability using Amazon datasets. We added some new encodings to help with these problems along the way. We found that we can reach new state-of-the-art results by finding the correct positional encoding, but more importantly, certain encodings stabilise the training.
Encoder-Decoder Framework for Interactive Free Verses with Generation with Controllable High-Quality Rhyming
May 08, 2024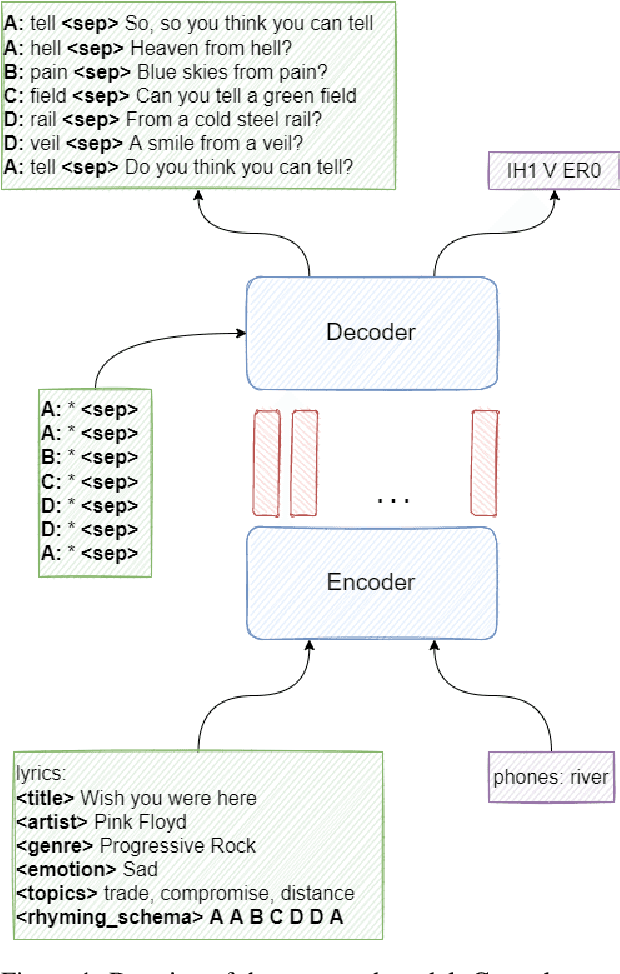
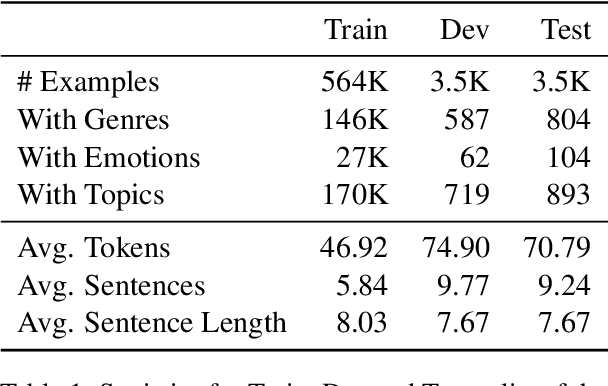
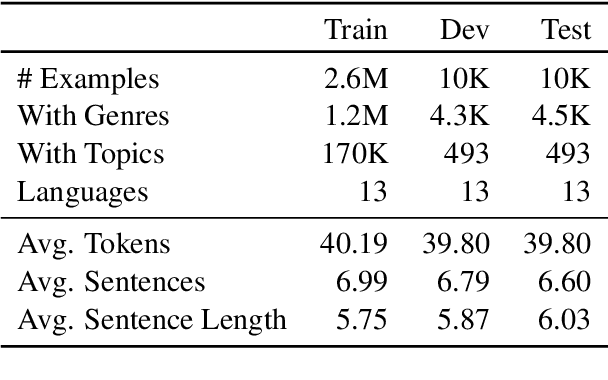
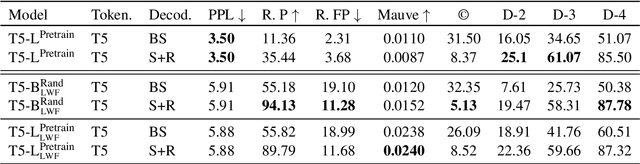
Composing poetry or lyrics involves several creative factors, but a challenging aspect of generation is the adherence to a more or less strict metric and rhyming pattern. To address this challenge specifically, previous work on the task has mainly focused on reverse language modeling, which brings the critical selection of each rhyming word to the forefront of each verse. On the other hand, reversing the word order requires that models be trained from scratch with this task-specific goal and cannot take advantage of transfer learning from a Pretrained Language Model (PLM). We propose a novel fine-tuning approach that prepends the rhyming word at the start of each lyric, which allows the critical rhyming decision to be made before the model commits to the content of the lyric (as during reverse language modeling), but maintains compatibility with the word order of regular PLMs as the lyric itself is still generated in left-to-right order. We conducted extensive experiments to compare this fine-tuning against the current state-of-the-art strategies for rhyming, finding that our approach generates more readable text and better rhyming capabilities. Furthermore, we furnish a high-quality dataset in English and 12 other languages, analyse the approach's feasibility in a multilingual context, provide extensive experimental results shedding light on good and bad practices for lyrics generation, and propose metrics to compare methods in the future.
PLAYER*: Enhancing LLM-based Multi-Agent Communication and Interaction in Murder Mystery Games
Apr 26, 2024Recent advancements in Large Language Models (LLMs) have enhanced the efficacy of agent communication and social interactions. Despite these advancements, building LLM-based agents for reasoning in dynamic environments involving competition and collaboration remains challenging due to the limitations of informed graph-based search methods. We propose PLAYER*, a novel framework based on an anytime sampling-based planner, which utilises sensors and pruners to enable a purely question-driven searching framework for complex reasoning tasks. We also introduce a quantifiable evaluation method using multiple-choice questions and construct the WellPlay dataset with 1,482 QA pairs. Experiments demonstrate PLAYER*'s efficiency and performance enhancements compared to existing methods in complex, dynamic environments with quantifiable results.
OpenToM: A Comprehensive Benchmark for Evaluating Theory-of-Mind Reasoning Capabilities of Large Language Models
Feb 14, 2024



Neural Theory-of-Mind (N-ToM), machine's ability to understand and keep track of the mental states of others, is pivotal in developing socially intelligent agents. However, prevalent N-ToM benchmarks have several shortcomings, including the presence of ambiguous and artificial narratives, absence of personality traits and preferences, a lack of questions addressing characters' psychological mental states, and limited diversity in the questions posed. In response to these issues, we construct OpenToM, a new benchmark for assessing N-ToM with (1) longer and clearer narrative stories, (2) characters with explicit personality traits, (3) actions that are triggered by character intentions, and (4) questions designed to challenge LLMs' capabilities of modeling characters' mental states of both the physical and psychological world. Using OpenToM, we reveal that state-of-the-art LLMs thrive at modeling certain aspects of mental states in the physical world but fall short when tracking characters' mental states in the psychological world.
Path-based Explanation for Knowledge Graph Completion
Jan 04, 2024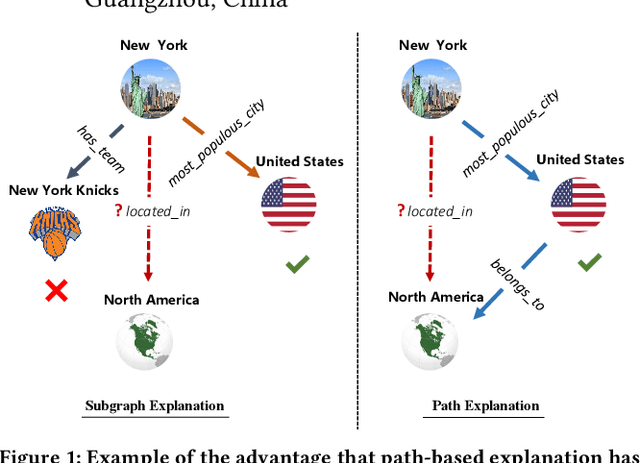

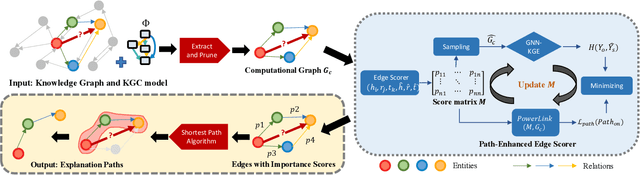

Graph Neural Networks (GNNs) have achieved great success in Knowledge Graph Completion (KGC) by modelling how entities and relations interact in recent years. However, the explanation of the predicted facts has not caught the necessary attention. Proper explanations for the results of GNN-based KGC models increase model transparency and help researchers develop more reliable models. Existing practices for explaining KGC tasks rely on instance/subgraph-based approaches, while in some scenarios, paths can provide more user-friendly and interpretable explanations. Nonetheless, the methods for generating path-based explanations for KGs have not been well-explored. To address this gap, we propose Power-Link, the first path-based KGC explainer that explores GNN-based models. We design a novel simplified graph-powering technique, which enables the generation of path-based explanations with a fully parallelisable and memory-efficient training scheme. We further introduce three new metrics for quantitative evaluation of the explanations, together with a qualitative human evaluation. Extensive experiments demonstrate that Power-Link outperforms the SOTA baselines in interpretability, efficiency, and scalability.
Multi-Level Structured Self-Attentions for Distantly Supervised Relation Extraction
Sep 03, 2018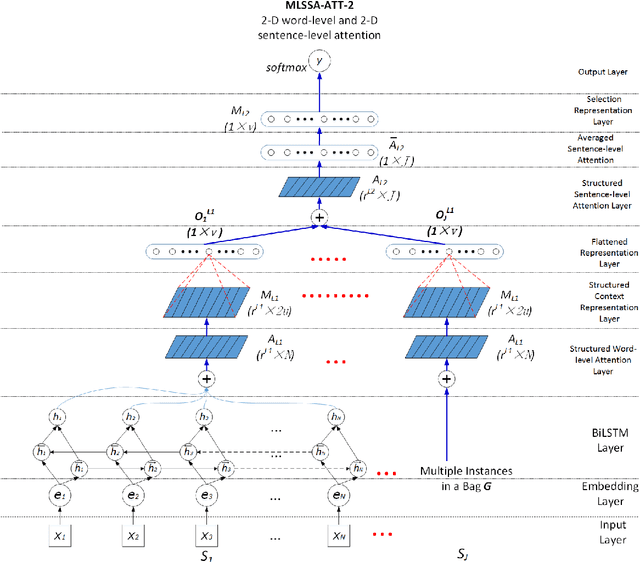

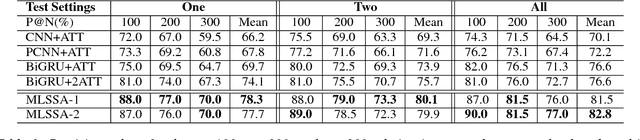
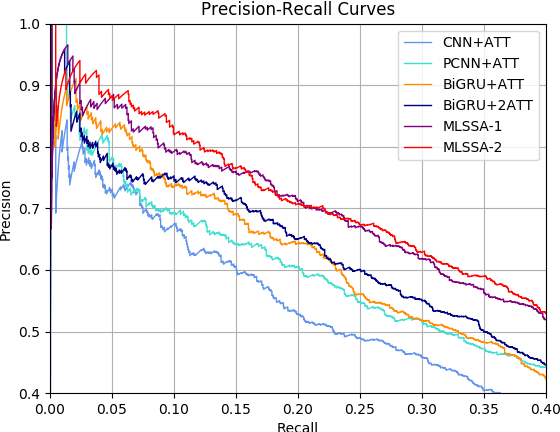
Attention mechanisms are often used in deep neural networks for distantly supervised relation extraction (DS-RE) to distinguish valid from noisy instances. However, traditional 1-D vector attention models are insufficient for the learning of different contexts in the selection of valid instances to predict the relationship for an entity pair. To alleviate this issue, we propose a novel multi-level structured (2-D matrix) self-attention mechanism for DS-RE in a multi-instance learning (MIL) framework using bidirectional recurrent neural networks. In the proposed method, a structured word-level self-attention mechanism learns a 2-D matrix where each row vector represents a weight distribution for different aspects of an instance regarding two entities. Targeting the MIL issue, the structured sentence-level attention learns a 2-D matrix where each row vector represents a weight distribution on selection of different valid in-stances. Experiments conducted on two publicly available DS-RE datasets show that the proposed framework with a multi-level structured self-attention mechanism significantly outperform state-of-the-art baselines in terms of PR curves, P@N and F1 measures.