 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePangu Ultra MoE: How to Train Your Big MoE on Ascend NPUs
May 07, 2025



Sparse large language models (LLMs) with Mixture of Experts (MoE) and close to a trillion parameters are dominating the realm of most capable language models. However, the massive model scale poses significant challenges for the underlying software and hardware systems. In this paper, we aim to uncover a recipe to harness such scale on Ascend NPUs. The key goals are better usage of the computing resources under the dynamic sparse model structures and materializing the expected performance gain on the actual hardware. To select model configurations suitable for Ascend NPUs without repeatedly running the expensive experiments, we leverage simulation to compare the trade-off of various model hyperparameters. This study led to Pangu Ultra MoE, a sparse LLM with 718 billion parameters, and we conducted experiments on the model to verify the simulation results. On the system side, we dig into Expert Parallelism to optimize the communication between NPU devices to reduce the synchronization overhead. We also optimize the memory efficiency within the devices to further reduce the parameter and activation management overhead. In the end, we achieve an MFU of 30.0% when training Pangu Ultra MoE, with performance comparable to that of DeepSeek R1, on 6K Ascend NPUs, and demonstrate that the Ascend system is capable of harnessing all the training stages of the state-of-the-art language models. Extensive experiments indicate that our recipe can lead to efficient training of large-scale sparse language models with MoE. We also study the behaviors of such models for future reference.
Encoder-Decoder Framework for Interactive Free Verses with Generation with Controllable High-Quality Rhyming
May 08, 2024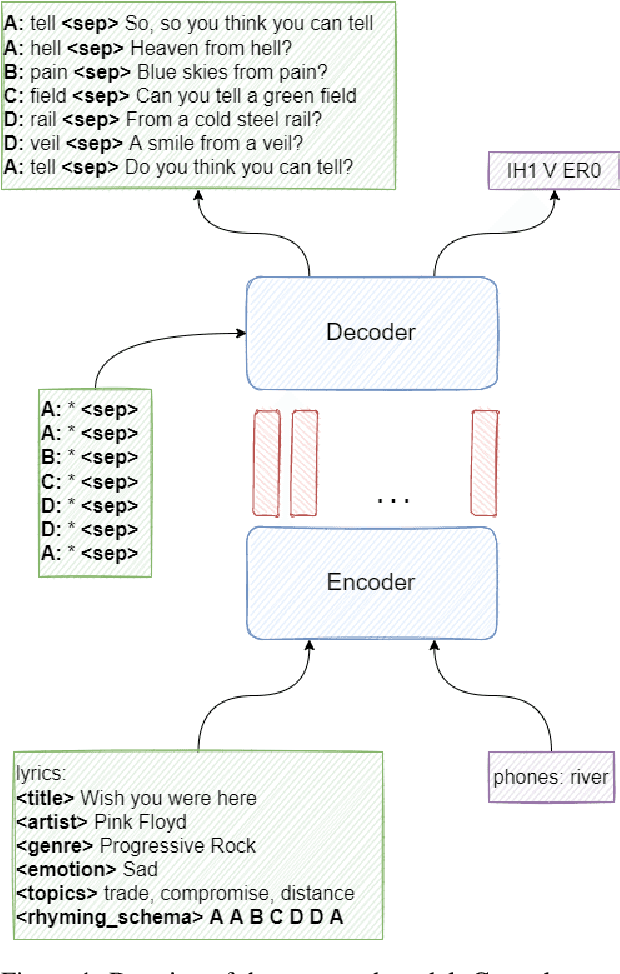
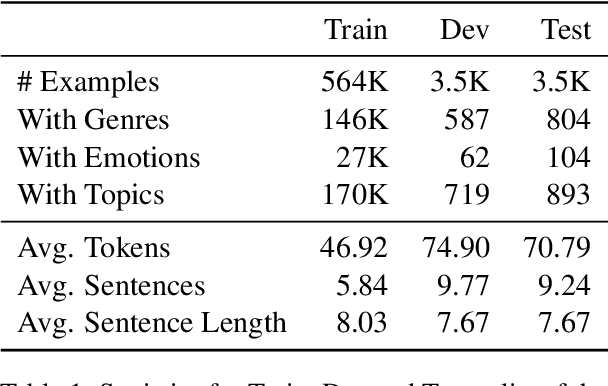
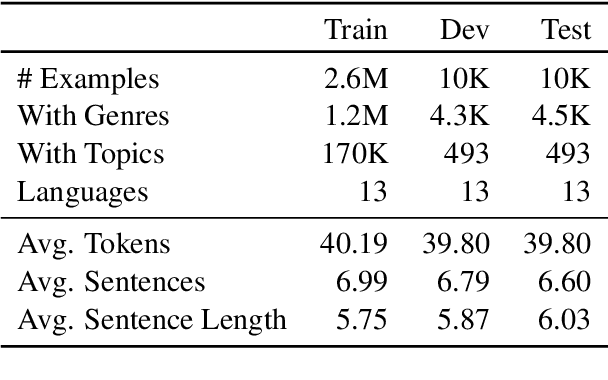
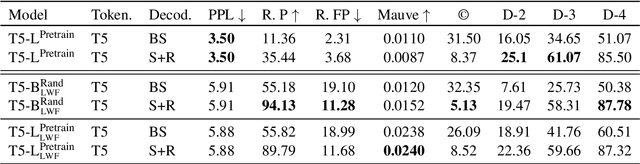
Composing poetry or lyrics involves several creative factors, but a challenging aspect of generation is the adherence to a more or less strict metric and rhyming pattern. To address this challenge specifically, previous work on the task has mainly focused on reverse language modeling, which brings the critical selection of each rhyming word to the forefront of each verse. On the other hand, reversing the word order requires that models be trained from scratch with this task-specific goal and cannot take advantage of transfer learning from a Pretrained Language Model (PLM). We propose a novel fine-tuning approach that prepends the rhyming word at the start of each lyric, which allows the critical rhyming decision to be made before the model commits to the content of the lyric (as during reverse language modeling), but maintains compatibility with the word order of regular PLMs as the lyric itself is still generated in left-to-right order. We conducted extensive experiments to compare this fine-tuning against the current state-of-the-art strategies for rhyming, finding that our approach generates more readable text and better rhyming capabilities. Furthermore, we furnish a high-quality dataset in English and 12 other languages, analyse the approach's feasibility in a multilingual context, provide extensive experimental results shedding light on good and bad practices for lyrics generation, and propose metrics to compare methods in the future.
M4LE: A Multi-Ability Multi-Range Multi-Task Multi-Domain Long-Context Evaluation Benchmark for Large Language Models
Oct 30, 2023Managing long sequences has become an important and necessary feature for large language models (LLMs). However, it is still an open question of how to comprehensively and systematically evaluate the long-sequence capability of LLMs. One of the reasons is that conventional and widely-used benchmarks mainly consist of short sequences. In this paper, we propose M4LE, a Multi-ability, Multi-range, Multi-task, Multi-domain benchmark for Long-context Evaluation. M4LE is based on a diverse NLP task pool comprising 36 NLP datasets, 11 task types and 12 domains. To alleviate the scarcity of tasks with naturally long sequences and incorporate multiple-ability assessment, we propose an automatic approach (but with negligible human annotations) to convert short-sequence tasks into a unified long-sequence scenario where LLMs have to identify single or multiple relevant spans in long contexts based on explicit or semantic hints. Specifically, the scenario includes five different types of abilities: (1) explicit single-span; (2) semantic single-span; (3) explicit multiple-span; (4) semantic multiple-span; and (5) global context understanding. The resulting samples in M4LE are evenly distributed from 1k to 8k input length. We conducted a systematic evaluation on 11 well-established LLMs, especially those optimized for long-sequence inputs. Our results reveal that: 1) Current LLMs struggle to understand long context, particularly when tasks require multiple-span attention. 2) Semantic retrieval task is more difficult for competent LLMs. 3) Models fine-tuned on longer text with position interpolation have comparable performance to those using Neural Tangent Kernel (NTK) aware scaling methods without fine-tuning. We make our benchmark publicly available to encourage future research in this challenging area.
SongRewriter: A Chinese Song Rewriting System with Controllable Content and Rhyme Scheme
Nov 28, 2022



Although lyrics generation has achieved significant progress in recent years, it has limited practical applications because the generated lyrics cannot be performed without composing compatible melodies. In this work, we bridge this practical gap by proposing a song rewriting system which rewrites the lyrics of an existing song such that the generated lyrics are compatible with the rhythm of the existing melody and thus singable. In particular, we propose SongRewriter, a controllable Chinese lyric generation and editing system which assists users without prior knowledge of melody composition. The system is trained by a randomized multi-level masking strategy which produces a unified model for generating entirely new lyrics or editing a few fragments. To improve the controllabiliy of the generation process, we further incorporate a keyword prompt to control the lexical choices of the content and propose novel decoding constraints and a vowel modeling task to enable flexible end and internal rhyme schemes. While prior rhyming metrics are mainly for rap lyrics, we propose three novel rhyming evaluation metrics for song lyrics. Both automatic and human evaluations show that the proposed model performs better than the state-of-the-art models in both contents and rhyming quality. Our code and models implemented in MindSpore Lite tool will be available.