 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEncoder-Decoder Framework for Interactive Free Verses with Generation with Controllable High-Quality Rhyming
May 08, 2024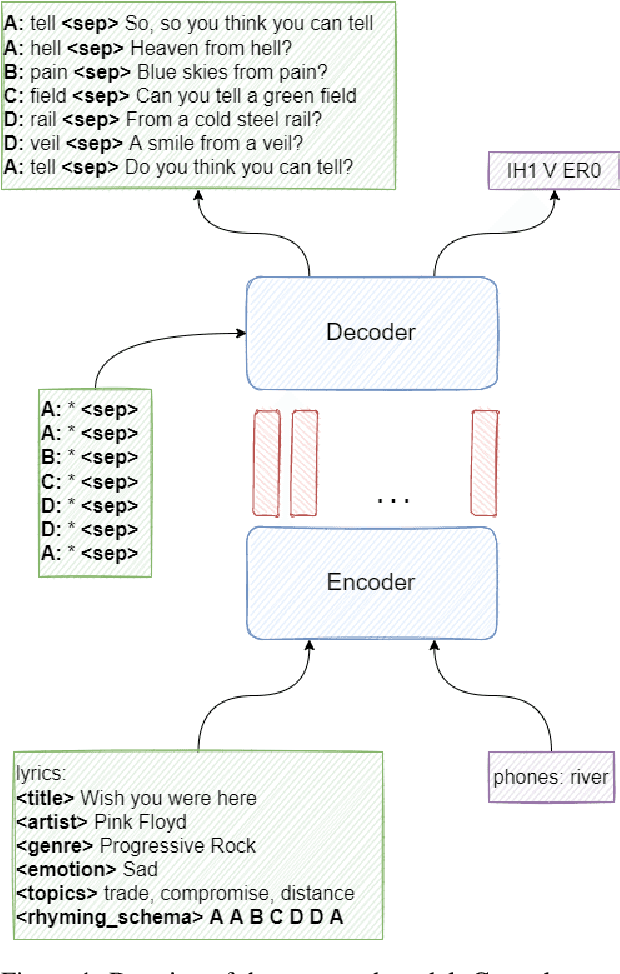
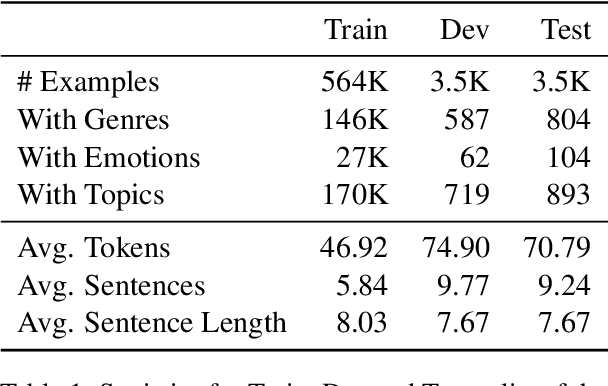
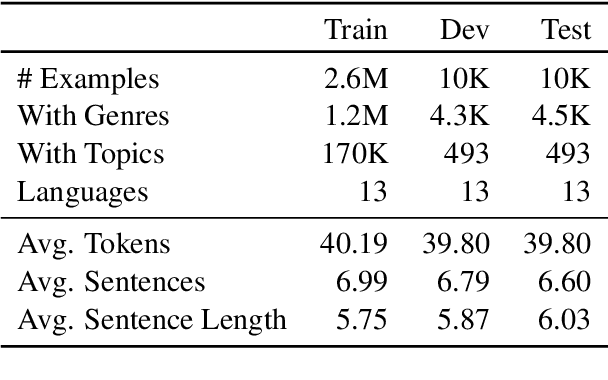
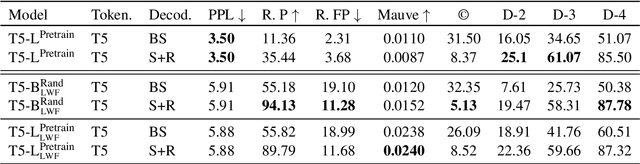
Composing poetry or lyrics involves several creative factors, but a challenging aspect of generation is the adherence to a more or less strict metric and rhyming pattern. To address this challenge specifically, previous work on the task has mainly focused on reverse language modeling, which brings the critical selection of each rhyming word to the forefront of each verse. On the other hand, reversing the word order requires that models be trained from scratch with this task-specific goal and cannot take advantage of transfer learning from a Pretrained Language Model (PLM). We propose a novel fine-tuning approach that prepends the rhyming word at the start of each lyric, which allows the critical rhyming decision to be made before the model commits to the content of the lyric (as during reverse language modeling), but maintains compatibility with the word order of regular PLMs as the lyric itself is still generated in left-to-right order. We conducted extensive experiments to compare this fine-tuning against the current state-of-the-art strategies for rhyming, finding that our approach generates more readable text and better rhyming capabilities. Furthermore, we furnish a high-quality dataset in English and 12 other languages, analyse the approach's feasibility in a multilingual context, provide extensive experimental results shedding light on good and bad practices for lyrics generation, and propose metrics to compare methods in the future.
FairLex: A Multilingual Benchmark for Evaluating Fairness in Legal Text Processing
Mar 14, 2022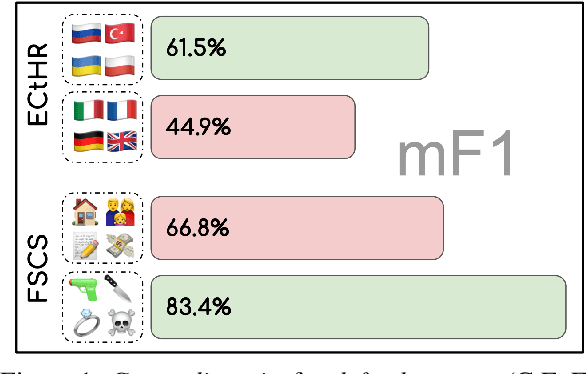

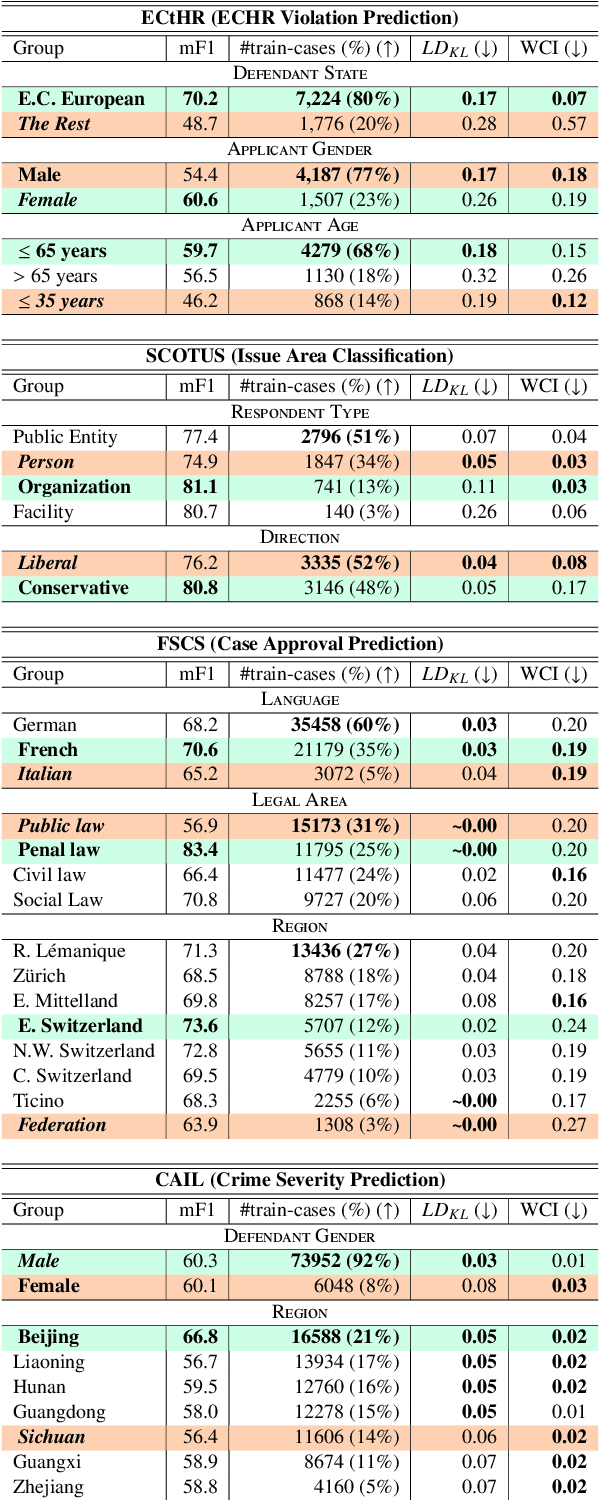

We present a benchmark suite of four datasets for evaluating the fairness of pre-trained language models and the techniques used to fine-tune them for downstream tasks. Our benchmarks cover four jurisdictions (European Council, USA, Switzerland, and China), five languages (English, German, French, Italian and Chinese) and fairness across five attributes (gender, age, region, language, and legal area). In our experiments, we evaluate pre-trained language models using several group-robust fine-tuning techniques and show that performance group disparities are vibrant in many cases, while none of these techniques guarantee fairness, nor consistently mitigate group disparities. Furthermore, we provide a quantitative and qualitative analysis of our results, highlighting open challenges in the development of robustness methods in legal NLP.
XL-WiC: A Multilingual Benchmark for Evaluating Semantic Contextualization
Oct 13, 2020
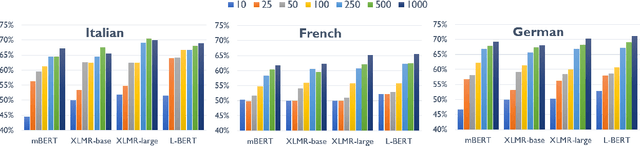

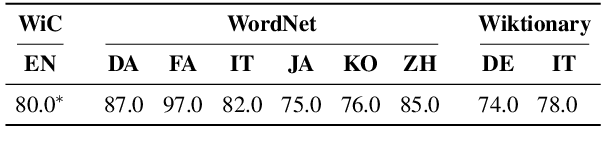
The ability to correctly model distinct meanings of a word is crucial for the effectiveness of semantic representation techniques. However, most existing evaluation benchmarks for assessing this criterion are tied to sense inventories (usually WordNet), restricting their usage to a small subset of knowledge-based representation techniques. The Word-in-Context dataset (WiC) addresses the dependence on sense inventories by reformulating the standard disambiguation task as a binary classification problem; but, it is limited to the English language. We put forward a large multilingual benchmark, XL-WiC, featuring gold standards in 12 new languages from varied language families and with different degrees of resource availability, opening room for evaluation scenarios such as zero-shot cross-lingual transfer. We perform a series of experiments to determine the reliability of the datasets and to set performance baselines for several recent contextualized multilingual models. Experimental results show that even when no tagged instances are available for a target language, models trained solely on the English data can attain competitive performance in the task of distinguishing different meanings of a word, even for distant languages. XL-WiC is available at https://pilehvar.github.io/xlwic/.
Huge Automatically Extracted Training Sets for Multilingual Word Sense Disambiguation
May 12, 2018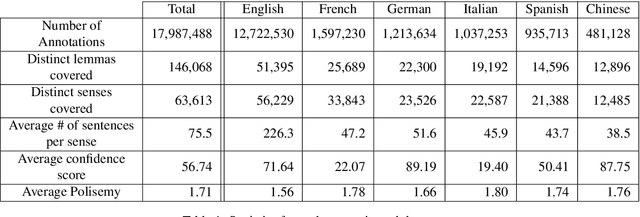
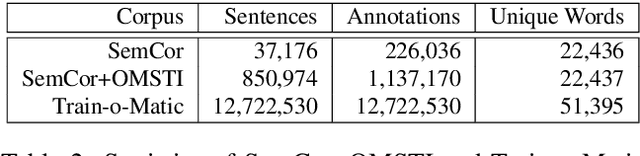
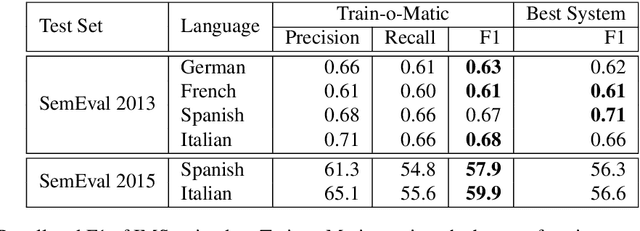
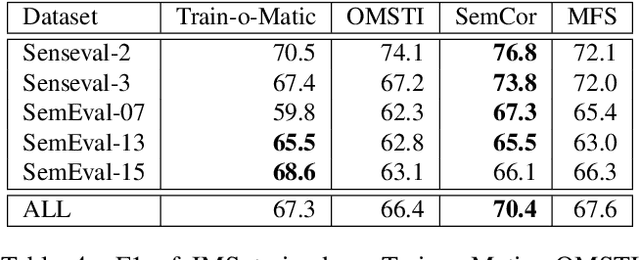
We release to the community six large-scale sense-annotated datasets in multiple language to pave the way for supervised multilingual Word Sense Disambiguation. Our datasets cover all the nouns in the English WordNet and their translations in other languages for a total of millions of sense-tagged sentences. Experiments prove that these corpora can be effectively used as training sets for supervised WSD systems, surpassing the state of the art for low-resourced languages and providing competitive results for English, where manually annotated training sets are accessible. The data is available at trainomatic.org.
A Short Survey on Sense-Annotated Corpora for Diverse Languages and Resources
Feb 13, 2018
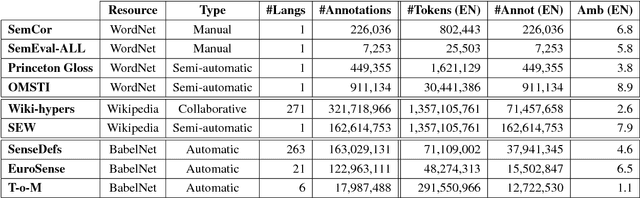
With the advancement of research in word sense disambiguation and deep learning, large sense-annotated datasets are increasingly important for training supervised systems. However, gathering high-quality sense-annotated data for as many instances as possible is an arduous task. This has led to the proliferation of automatic and semi-automatic methods for overcoming the so-called knowledge-acquisition bottleneck. In this paper we present an overview of currently available sense-annotated corpora, both manually and automatically constructed, for various languages and resources (i.e. WordNet, Wikipedia, BabelNet). General statistics and specific features of each sense-annotated dataset are also provided.