Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Short Survey on Sense-Annotated Corpora for Diverse Languages and Resources
Paper and Code
Feb 13, 2018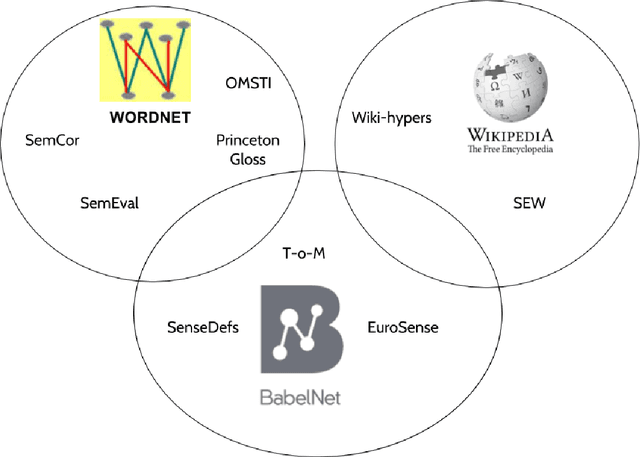
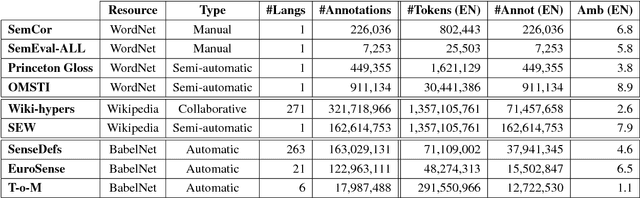
With the advancement of research in word sense disambiguation and deep learning, large sense-annotated datasets are increasingly important for training supervised systems. However, gathering high-quality sense-annotated data for as many instances as possible is an arduous task. This has led to the proliferation of automatic and semi-automatic methods for overcoming the so-called knowledge-acquisition bottleneck. In this paper we present an overview of currently available sense-annotated corpora, both manually and automatically constructed, for various languages and resources (i.e. WordNet, Wikipedia, BabelNet). General statistics and specific features of each sense-annotated dataset are also provided.
* 7 pages, 1 figure, 1 table
View paper on