 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Static Cropping: Layer-Adaptive Visual Localization and Decoding Enhancement
Feb 04, 2026Large Vision-Language Models (LVLMs) have advanced rapidly by aligning visual patches with the text embedding space, but a fixed visual-token budget forces images to be resized to a uniform pretraining resolution, often erasing fine-grained details and causing hallucinations via over-reliance on language priors. Recent attention-guided enhancement (e.g., cropping or region-focused attention allocation) alleviates this, yet it commonly hinges on a static "magic layer" empirically chosen on simple recognition benchmarks and thus may not transfer to complex reasoning tasks. In contrast to this static assumption, we propose a dynamic perspective on visual grounding. Through a layer-wise sensitivity analysis, we demonstrate that visual grounding is a dynamic process: while simple object recognition tasks rely on middle layers, complex visual search and reasoning tasks require visual information to be reactivated at deeper layers. Based on this observation, we introduce Visual Activation by Query (VAQ), a metric that identifies the layer whose attention map is most relevant to query-specific visual grounding by measuring attention sensitivity to the input query. Building on VAQ, we further propose LASER (Layer-adaptive Attention-guided Selective visual and decoding Enhancement for Reasoning), a training-free inference procedure that adaptively selects task-appropriate layers for visual localization and question answering. Experiments across diverse VQA benchmarks show that LASER significantly improves VQA accuracy across tasks with varying levels of complexity.
Beyond RAG for Agent Memory: Retrieval by Decoupling and Aggregation
Feb 02, 2026Agent memory systems often adopt the standard Retrieval-Augmented Generation (RAG) pipeline, yet its underlying assumptions differ in this setting. RAG targets large, heterogeneous corpora where retrieved passages are diverse, whereas agent memory is a bounded, coherent dialogue stream with highly correlated spans that are often duplicates. Under this shift, fixed top-$k$ similarity retrieval tends to return redundant context, and post-hoc pruning can delete temporally linked prerequisites needed for correct reasoning. We argue retrieval should move beyond similarity matching and instead operate over latent components, following decoupling to aggregation: disentangle memories into semantic components, organise them into a hierarchy, and use this structure to drive retrieval. We propose xMemory, which builds a hierarchy of intact units and maintains a searchable yet faithful high-level node organisation via a sparsity--semantics objective that guides memory split and merge. At inference, xMemory retrieves top-down, selecting a compact, diverse set of themes and semantics for multi-fact queries, and expanding to episodes and raw messages only when it reduces the reader's uncertainty. Experiments on LoCoMo and PerLTQA across the three latest LLMs show consistent gains in answer quality and token efficiency.
Soft Reasoning: Navigating Solution Spaces in Large Language Models through Controlled Embedding Exploration
May 30, 2025Large Language Models (LLMs) struggle with complex reasoning due to limited diversity and inefficient search. We propose Soft Reasoning, an embedding-based search framework that optimises the embedding of the first token to guide generation. It combines (1) embedding perturbation for controlled exploration and (2) Bayesian optimisation to refine embeddings via a verifier-guided objective, balancing exploration and exploitation. This approach improves reasoning accuracy and coherence while avoiding reliance on heuristic search. Experiments demonstrate superior correctness with minimal computation, making it a scalable, model-agnostic solution.
Sparse Activation Editing for Reliable Instruction Following in Narratives
May 22, 2025

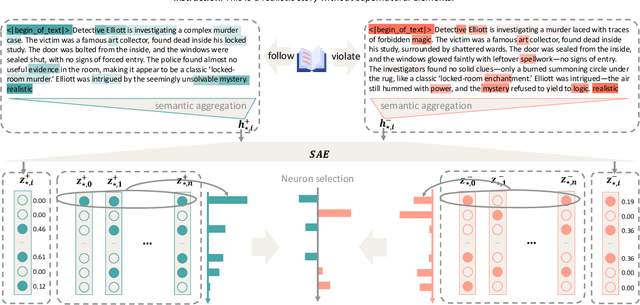

Complex narrative contexts often challenge language models' ability to follow instructions, and existing benchmarks fail to capture these difficulties. To address this, we propose Concise-SAE, a training-free framework that improves instruction following by identifying and editing instruction-relevant neurons using only natural language instructions, without requiring labelled data. To thoroughly evaluate our method, we introduce FreeInstruct, a diverse and realistic benchmark of 1,212 examples that highlights the challenges of instruction following in narrative-rich settings. While initially motivated by complex narratives, Concise-SAE demonstrates state-of-the-art instruction adherence across varied tasks without compromising generation quality.
PLAYER*: Enhancing LLM-based Multi-Agent Communication and Interaction in Murder Mystery Games
Apr 26, 2024Recent advancements in Large Language Models (LLMs) have enhanced the efficacy of agent communication and social interactions. Despite these advancements, building LLM-based agents for reasoning in dynamic environments involving competition and collaboration remains challenging due to the limitations of informed graph-based search methods. We propose PLAYER*, a novel framework based on an anytime sampling-based planner, which utilises sensors and pruners to enable a purely question-driven searching framework for complex reasoning tasks. We also introduce a quantifiable evaluation method using multiple-choice questions and construct the WellPlay dataset with 1,482 QA pairs. Experiments demonstrate PLAYER*'s efficiency and performance enhancements compared to existing methods in complex, dynamic environments with quantifiable results.
Mirror: A Multiple-perspective Self-Reflection Method for Knowledge-rich Reasoning
Feb 22, 2024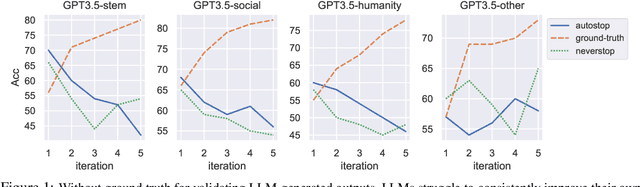
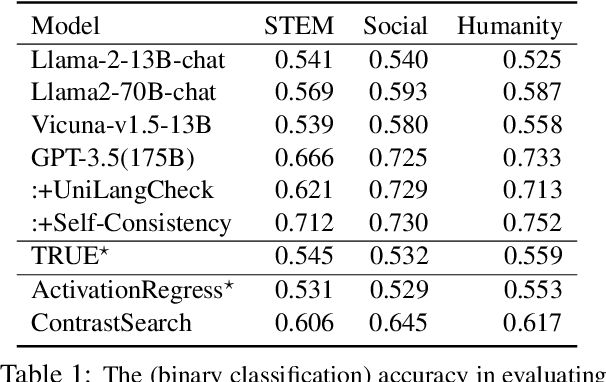
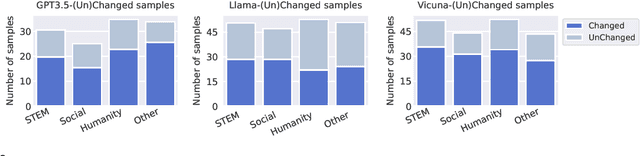
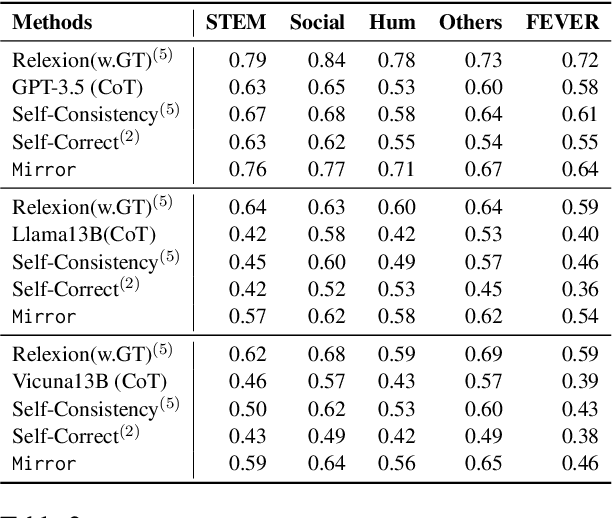
While Large language models (LLMs) have the capability to iteratively reflect on their own outputs, recent studies have observed their struggles with knowledge-rich problems without access to external resources. In addition to the inefficiency of LLMs in self-assessment, we also observe that LLMs struggle to revisit their predictions despite receiving explicit negative feedback. Therefore, We propose Mirror, a Multiple-perspective self-reflection method for knowledge-rich reasoning, to avoid getting stuck at a particular reflection iteration. Mirror enables LLMs to reflect from multiple-perspective clues, achieved through a heuristic interaction between a Navigator and a Reasoner. It guides agents toward diverse yet plausibly reliable reasoning trajectory without access to ground truth by encouraging (1) diversity of directions generated by Navigator and (2) agreement among strategically induced perturbations in responses generated by the Reasoner. The experiments on five reasoning datasets demonstrate that Mirror's superiority over several contemporary self-reflection approaches. Additionally, the ablation study studies clearly indicate that our strategies alleviate the aforementioned challenges.
Large Language Models Fall Short: Understanding Complex Relationships in Detective Narratives
Feb 16, 2024



Existing datasets for narrative understanding often fail to represent the complexity and uncertainty of relationships in real-life social scenarios. To address this gap, we introduce a new benchmark, Conan, designed for extracting and analysing intricate character relation graphs from detective narratives. Specifically, we designed hierarchical relationship categories and manually extracted and annotated role-oriented relationships from the perspectives of various characters, incorporating both public relationships known to most characters and secret ones known to only a few. Our experiments with advanced Large Language Models (LLMs) like GPT-3.5, GPT-4, and Llama2 reveal their limitations in inferencing complex relationships and handling longer narratives. The combination of the Conan dataset and our pipeline strategy is geared towards understanding the ability of LLMs to comprehend nuanced relational dynamics in narrative contexts.