 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey on Large Language Models in Multimodal Recommender Systems
May 14, 2025Multimodal recommender systems (MRS) integrate heterogeneous user and item data, such as text, images, and structured information, to enhance recommendation performance. The emergence of large language models (LLMs) introduces new opportunities for MRS by enabling semantic reasoning, in-context learning, and dynamic input handling. Compared to earlier pre-trained language models (PLMs), LLMs offer greater flexibility and generalisation capabilities but also introduce challenges related to scalability and model accessibility. This survey presents a comprehensive review of recent work at the intersection of LLMs and MRS, focusing on prompting strategies, fine-tuning methods, and data adaptation techniques. We propose a novel taxonomy to characterise integration patterns, identify transferable techniques from related recommendation domains, provide an overview of evaluation metrics and datasets, and point to possible future directions. We aim to clarify the emerging role of LLMs in multimodal recommendation and support future research in this rapidly evolving field.
Combining Denoising Autoencoders with Contrastive Learning to fine-tune Transformer Models
May 23, 2024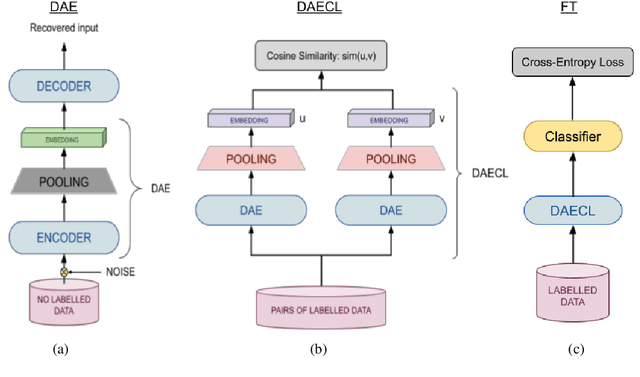
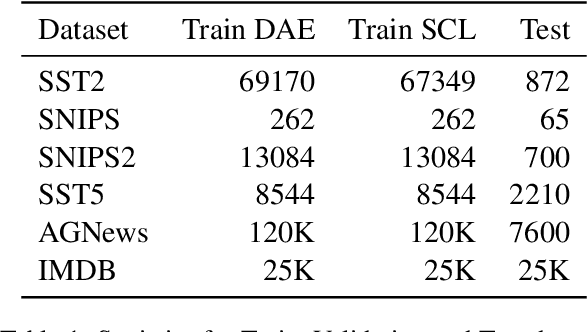
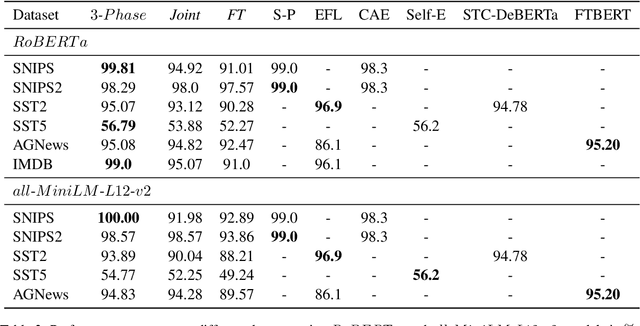
Recently, using large pretrained Transformer models for transfer learning tasks has evolved to the point where they have become one of the flagship trends in the Natural Language Processing (NLP) community, giving rise to various outlooks such as prompt-based, adapters or combinations with unsupervised approaches, among many others. This work proposes a 3 Phase technique to adjust a base model for a classification task. First, we adapt the model's signal to the data distribution by performing further training with a Denoising Autoencoder (DAE). Second, we adjust the representation space of the output to the corresponding classes by clustering through a Contrastive Learning (CL) method. In addition, we introduce a new data augmentation approach for Supervised Contrastive Learning to correct the unbalanced datasets. Third, we apply fine-tuning to delimit the predefined categories. These different phases provide relevant and complementary knowledge to the model to learn the final task. We supply extensive experimental results on several datasets to demonstrate these claims. Moreover, we include an ablation study and compare the proposed method against other ways of combining these techniques.
* 1 figure, 7 tables, 12 pages
Positional encoding is not the same as context: A study on positional encoding for Sequential recommendation
May 16, 2024The expansion of streaming media and e-commerce has led to a boom in recommendation systems, including Sequential recommendation systems, which consider the user's previous interactions with items. In recent years, research has focused on architectural improvements such as transformer blocks and feature extraction that can augment model information. Among these features are context and attributes. Of particular importance is the temporal footprint, which is often considered part of the context and seen in previous publications as interchangeable with positional information. Other publications use positional encodings with little attention to them. In this paper, we analyse positional encodings, showing that they provide relative information between items that are not inferable from the temporal footprint. Furthermore, we evaluate different encodings and how they affect metrics and stability using Amazon datasets. We added some new encodings to help with these problems along the way. We found that we can reach new state-of-the-art results by finding the correct positional encoding, but more importantly, certain encodings stabilise the training.