 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePRECISE: Pre-training Sequential Recommenders with Collaborative and Semantic Information
Dec 09, 2024Real-world recommendation systems commonly offer diverse content scenarios for users to interact with. Considering the enormous number of users in industrial platforms, it is infeasible to utilize a single unified recommendation model to meet the requirements of all scenarios. Usually, separate recommendation pipelines are established for each distinct scenario. This practice leads to challenges in comprehensively grasping users' interests. Recent research endeavors have been made to tackle this problem by pre-training models to encapsulate the overall interests of users. Traditional pre-trained recommendation models mainly capture user interests by leveraging collaborative signals. Nevertheless, a prevalent drawback of these systems is their incapacity to handle long-tail items and cold-start scenarios. With the recent advent of large language models, there has been a significant increase in research efforts focused on exploiting LLMs to extract semantic information for users and items. However, text-based recommendations highly rely on elaborate feature engineering and frequently fail to capture collaborative similarities. To overcome these limitations, we propose a novel pre-training framework for sequential recommendation, termed PRECISE. This framework combines collaborative signals with semantic information. Moreover, PRECISE employs a learning framework that initially models users' comprehensive interests across all recommendation scenarios and subsequently concentrates on the specific interests of target-scene behaviors. We demonstrate that PRECISE precisely captures the entire range of user interests and effectively transfers them to the target interests. Empirical findings reveal that the PRECISE framework attains outstanding performance on both public and industrial datasets.
KELLMRec: Knowledge-Enhanced Large Language Models for Recommendation
Mar 11, 2024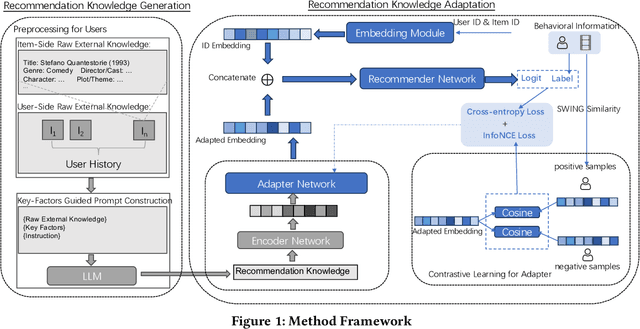


The utilization of semantic information is an important research problem in the field of recommender systems, which aims to complement the missing parts of mainstream ID-based approaches. With the rise of LLM, its ability to act as a knowledge base and its reasoning capability have opened up new possibilities for this research area, making LLM-based recommendation an emerging research direction. However, directly using LLM to process semantic information for recommendation scenarios is unreliable and sub-optimal due to several problems such as hallucination. A promising way to cope with this is to use external knowledge to aid LLM in generating truthful and usable text. Inspired by the above motivation, we propose a Knowledge-Enhanced LLMRec method. In addition to using external knowledge in prompts, the proposed method also includes a knowledge-based contrastive learning scheme for training. Experiments on public datasets and in-enterprise datasets validate the effectiveness of the proposed method.
Addressing Confounding Feature Issue for Causal Recommendation
May 13, 2022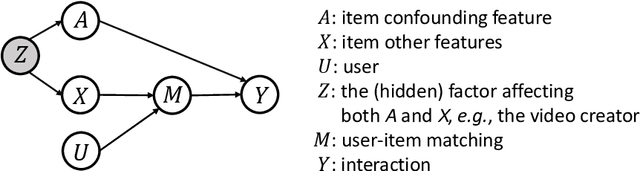

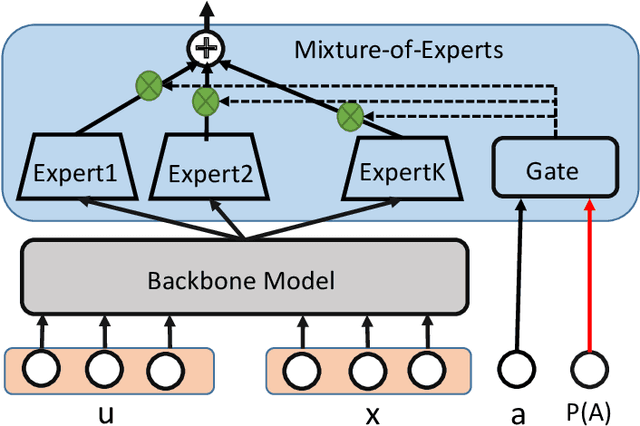
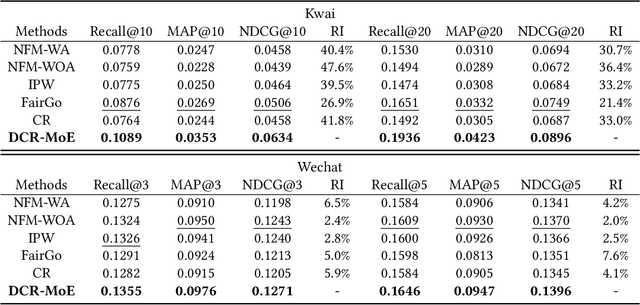
In recommender system, some feature directly affects whether an interaction would happen, making the happened interactions not necessarily indicate user preference. For instance, short videos are objectively easier to be finished even though the user does not like the video. We term such feature as confounding feature, and video length is a confounding feature in video recommendation. If we fit a model on such interaction data, just as done by most data-driven recommender systems, the model will be biased to recommend short videos more, and deviate from user actual requirement. This work formulates and addresses the problem from the causal perspective. Assuming there are some factors affecting both the confounding feature and other item features, e.g., the video creator, we find the confounding feature opens a backdoor path behind user item matching and introduces spurious correlation. To remove the effect of backdoor path, we propose a framework named Deconfounding Causal Recommendation (DCR), which performs intervened inference with do-calculus. Nevertheless, evaluating do calculus requires to sum over the prediction on all possible values of confounding feature, significantly increasing the time cost. To address the efficiency challenge, we further propose a mixture-of experts (MoE) model architecture, modeling each value of confounding feature with a separate expert module. Through this way, we retain the model expressiveness with few additional costs. We demonstrate DCR on the backbone model of neural factorization machine (NFM), showing that DCR leads to more accurate prediction of user preference with small inference time cost.
Causal Intervention for Leveraging Popularity Bias in Recommendation
May 13, 2021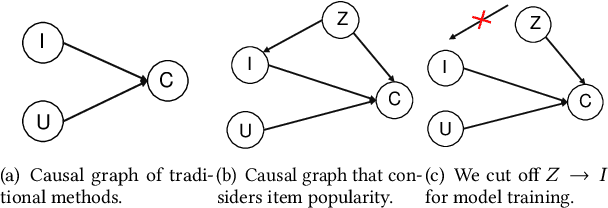

Recommender system usually faces popularity bias issues: from the data perspective, items exhibit uneven (long-tail) distribution on the interaction frequency; from the method perspective, collaborative filtering methods are prone to amplify the bias by over-recommending popular items. It is undoubtedly critical to consider popularity bias in recommender systems, and existing work mainly eliminates the bias effect. However, we argue that not all biases in the data are bad -- some items demonstrate higher popularity because of their better intrinsic quality. Blindly pursuing unbiased learning may remove the beneficial patterns in the data, degrading the recommendation accuracy and user satisfaction. This work studies an unexplored problem in recommendation -- how to leverage popularity bias to improve the recommendation accuracy. The key lies in two aspects: how to remove the bad impact of popularity bias during training, and how to inject the desired popularity bias in the inference stage that generates top-K recommendations. This questions the causal mechanism of the recommendation generation process. Along this line, we find that item popularity plays the role of confounder between the exposed items and the observed interactions, causing the bad effect of bias amplification. To achieve our goal, we propose a new training and inference paradigm for recommendation named Popularity-bias Deconfounding and Adjusting (PDA). It removes the confounding popularity bias in model training and adjusts the recommendation score with desired popularity bias via causal intervention. We demonstrate the new paradigm on latent factor model and perform extensive experiments on three real-world datasets. Empirical studies validate that the deconfounded training is helpful to discover user real interests and the inference adjustment with popularity bias could further improve the recommendation accuracy.
CatGCN: Graph Convolutional Networks with Categorical Node Features
Sep 17, 2020
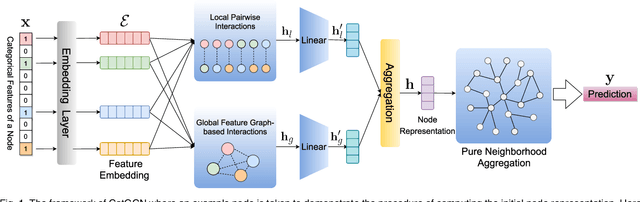
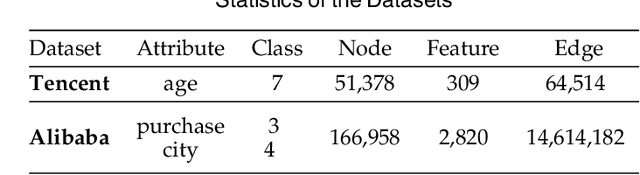
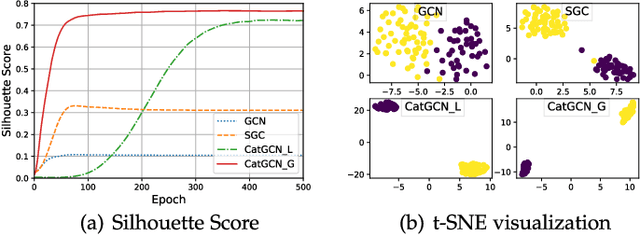
Recent studies on Graph Convolutional Networks (GCNs) reveal that the initial node representations (i.e., the node representations before the first-time graph convolution) largely affect the final model performance. However, when learning the initial representation for a node, most existing work linearly combines the embeddings of node features, without considering the interactions among the features (or feature embeddings). We argue that when the node features are categorical, e.g., in many real-world applications like user profiling and recommender system, feature interactions usually carry important signals for predictive analytics. Ignoring them will result in suboptimal initial node representation and thus weaken the effectiveness of the follow-up graph convolution. In this paper, we propose a new GCN model named CatGCN, which is tailored for graph learning when the node features are categorical. Specifically, we integrate two ways of explicit interaction modeling into the learning of initial node representation, i.e., local interaction modeling on each pair of node features and global interaction modeling on an artificial feature graph. We then refine the enhanced initial node representations with the neighborhood aggregation-based graph convolution. We train CatGCN in an end-to-end fashion and demonstrate it on semi-supervised node classification. Extensive experiments on three tasks of user profiling (the prediction of user age, city, and purchase level) from Tencent and Alibaba datasets validate the effectiveness of CatGCN, especially the positive effect of performing feature interaction modeling before graph convolution.
LoCEC: Local Community-based Edge Classification in Large Online Social Networks
Feb 11, 2020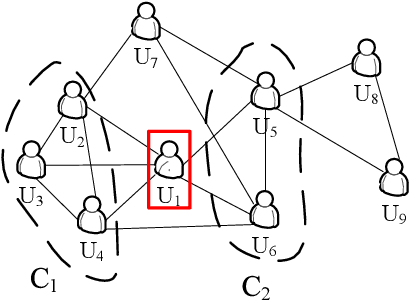
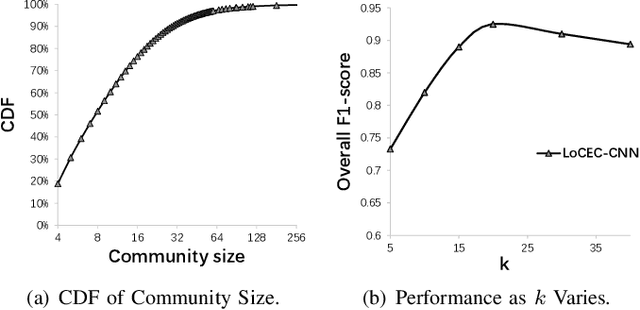
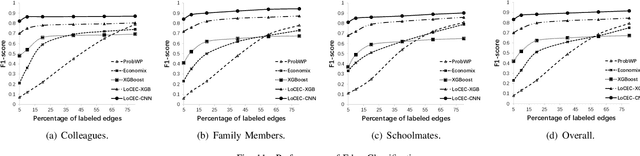
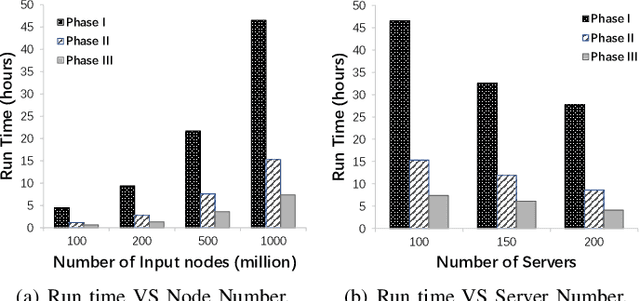
Relationships in online social networks often imply social connections in the real world. An accurate understanding of relationship types benefits many applications, e.g. social advertising and recommendation. Some recent attempts have been proposed to classify user relationships into predefined types with the help of pre-labeled relationships or abundant interaction features on relationships. Unfortunately, both relationship feature data and label data are very sparse in real social platforms like WeChat, rendering existing methods inapplicable. In this paper, we present an in-depth analysis of WeChat relationships to identify the major challenges for the relationship classification task. To tackle the challenges, we propose a Local Community-based Edge Classification (LoCEC) framework that classifies user relationships in a social network into real-world social connection types. LoCEC enforces a three-phase processing, namely local community detection, community classification and relationship classification, to address the sparsity issue of relationship features and relationship labels. Moreover, LoCEC is designed to handle large-scale networks by allowing parallel and distributed processing. We conduct extensive experiments on the real-world WeChat network with hundreds of billions of edges to validate the effectiveness and efficiency of LoCEC.