 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLightweight Contrastive Distilled Hashing for Online Cross-modal Retrieval
Feb 28, 2025Deep online cross-modal hashing has gained much attention from researchers recently, as its promising applications with low storage requirement, fast retrieval efficiency and cross modality adaptive, etc. However, there still exists some technical hurdles that hinder its applications, e.g., 1) how to extract the coexistent semantic relevance of cross-modal data, 2) how to achieve competitive performance when handling the real time data streams, 3) how to transfer the knowledge learned from offline to online training in a lightweight manner. To address these problems, this paper proposes a lightweight contrastive distilled hashing (LCDH) for cross-modal retrieval, by innovatively bridging the offline and online cross-modal hashing by similarity matrix approximation in a knowledge distillation framework. Specifically, in the teacher network, LCDH first extracts the cross-modal features by the contrastive language-image pre-training (CLIP), which are further fed into an attention module for representation enhancement after feature fusion. Then, the output of the attention module is fed into a FC layer to obtain hash codes for aligning the sizes of similarity matrices for online and offline training. In the student network, LCDH extracts the visual and textual features by lightweight models, and then the features are fed into a FC layer to generate binary codes. Finally, by approximating the similarity matrices, the performance of online hashing in the lightweight student network can be enhanced by the supervision of coexistent semantic relevance that is distilled from the teacher network. Experimental results on three widely used datasets demonstrate that LCDH outperforms some state-of-the-art methods.
MVREC: A General Few-shot Defect Classification Model Using Multi-View Region-Context
Dec 22, 2024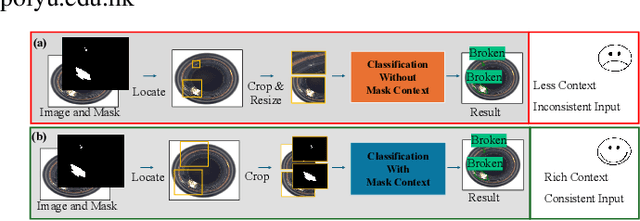
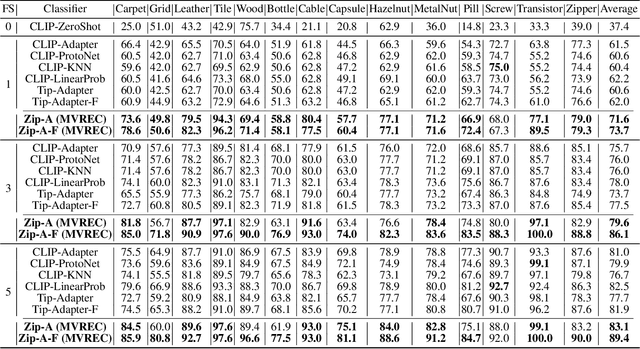
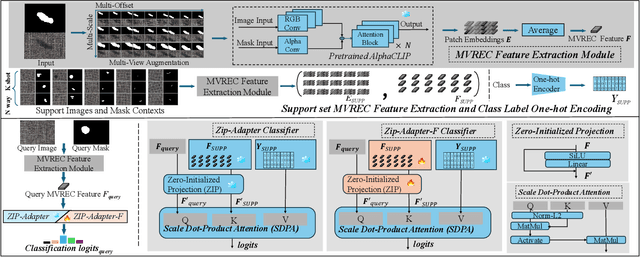
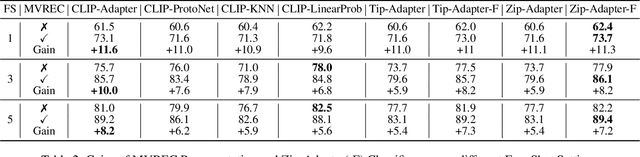
Few-shot defect multi-classification (FSDMC) is an emerging trend in quality control within industrial manufacturing. However, current FSDMC research often lacks generalizability due to its focus on specific datasets. Additionally, defect classification heavily relies on contextual information within images, and existing methods fall short of effectively extracting this information. To address these challenges, we propose a general FSDMC framework called MVREC, which offers two primary advantages: (1) MVREC extracts general features for defect instances by incorporating the pre-trained AlphaCLIP model. (2) It utilizes a region-context framework to enhance defect features by leveraging mask region input and multi-view context augmentation. Furthermore, Few-shot Zip-Adapter(-F) classifiers within the model are introduced to cache the visual features of the support set and perform few-shot classification. We also introduce MVTec-FS, a new FSDMC benchmark based on MVTec AD, which includes 1228 defect images with instance-level mask annotations and 46 defect types. Extensive experiments conducted on MVTec-FS and four additional datasets demonstrate its effectiveness in general defect classification and its ability to incorporate contextual information to improve classification performance. Code: https://github.com/ShuaiLYU/MVREC