 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-View Factorizing and Disentangling: A Novel Framework for Incomplete Multi-View Multi-Label Classification
Jan 11, 2025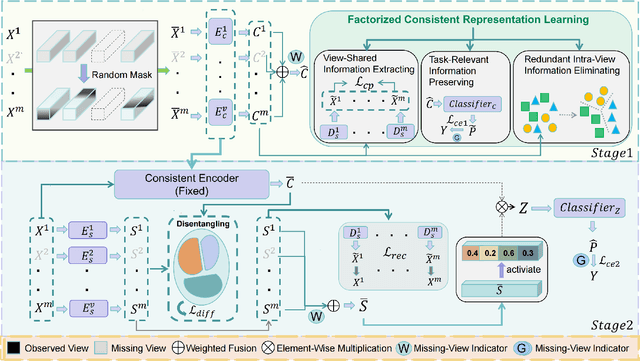
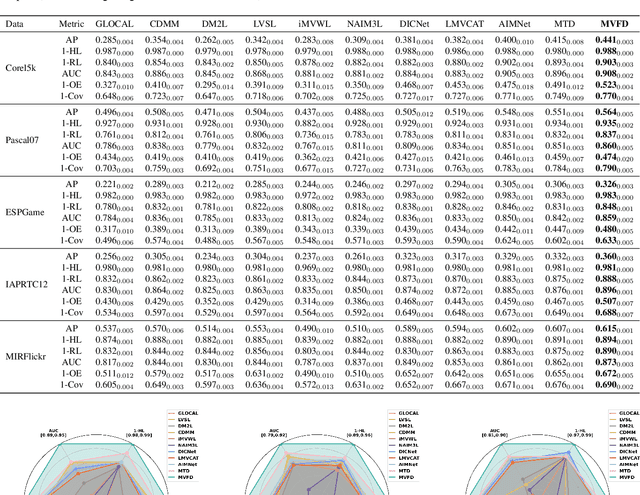
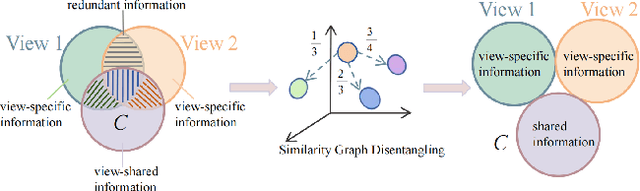
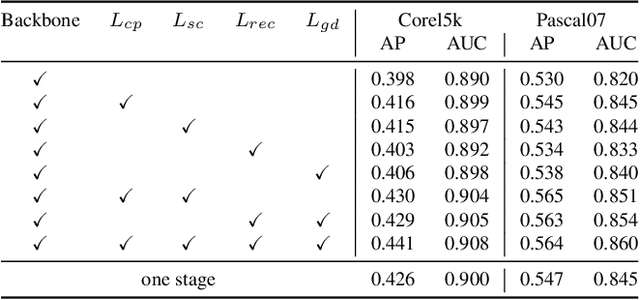
Multi-view multi-label classification (MvMLC) has recently garnered significant research attention due to its wide range of real-world applications. However, incompleteness in views and labels is a common challenge, often resulting from data collection oversights and uncertainties in manual annotation. Furthermore, the task of learning robust multi-view representations that are both view-consistent and view-specific from diverse views still a challenge problem in MvMLC. To address these issues, we propose a novel framework for incomplete multi-view multi-label classification (iMvMLC). Our method factorizes multi-view representations into two independent sets of factors: view-consistent and view-specific, and we correspondingly design a graph disentangling loss to fully reduce redundancy between these representations. Additionally, our framework innovatively decomposes consistent representation learning into three key sub-objectives: (i) how to extract view-shared information across different views, (ii) how to eliminate intra-view redundancy in consistent representations, and (iii) how to preserve task-relevant information. To this end, we design a robust task-relevant consistency learning module that collaboratively learns high-quality consistent representations, leveraging a masked cross-view prediction (MCP) strategy and information theory. Notably, all modules in our framework are developed to function effectively under conditions of incomplete views and labels, making our method adaptable to various multi-view and multi-label datasets. Extensive experiments on five datasets demonstrate that our method outperforms other leading approaches.
ResLearn: Transformer-based Residual Learning for Metaverse Network Traffic Prediction
Nov 07, 2024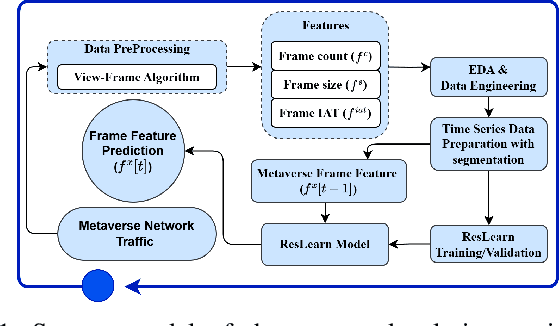
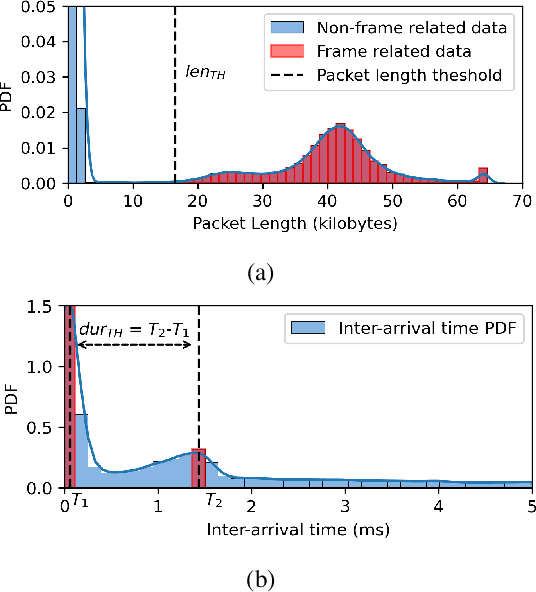
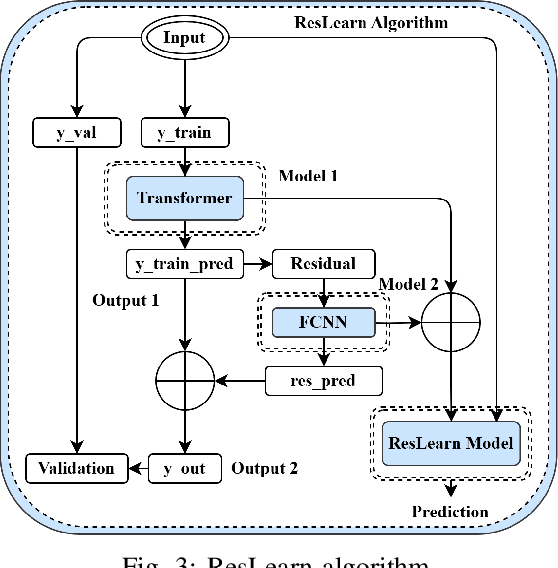
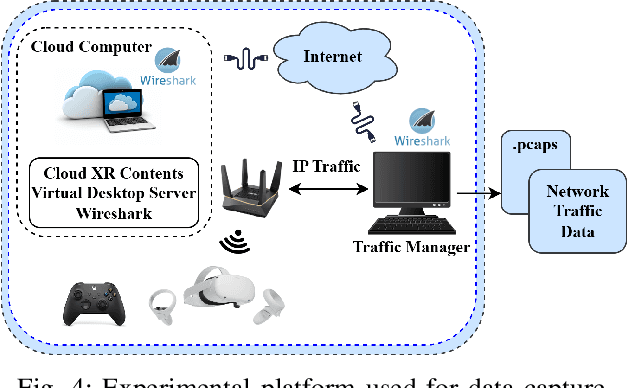
Our work proposes a comprehensive solution for predicting Metaverse network traffic, addressing the growing demand for intelligent resource management in eXtended Reality (XR) services. We first introduce a state-of-the-art testbed capturing a real-world dataset of virtual reality (VR), augmented reality (AR), and mixed reality (MR) traffic, made openly available for further research. To enhance prediction accuracy, we then propose a novel view-frame (VF) algorithm that accurately identifies video frames from traffic while ensuring privacy compliance, and we develop a Transformer-based progressive error-learning algorithm, referred to as ResLearn for Metaverse traffic prediction. ResLearn significantly improves time-series predictions by using fully connected neural networks to reduce errors, particularly during peak traffic, outperforming prior work by 99%. Our contributions offer Internet service providers (ISPs) robust tools for real-time network management to satisfy Quality of Service (QoS) and enhance user experience in the Metaverse.
Discern-XR: An Online Classifier for Metaverse Network Traffic
Nov 07, 2024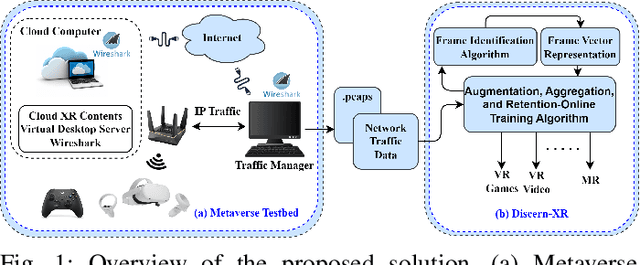
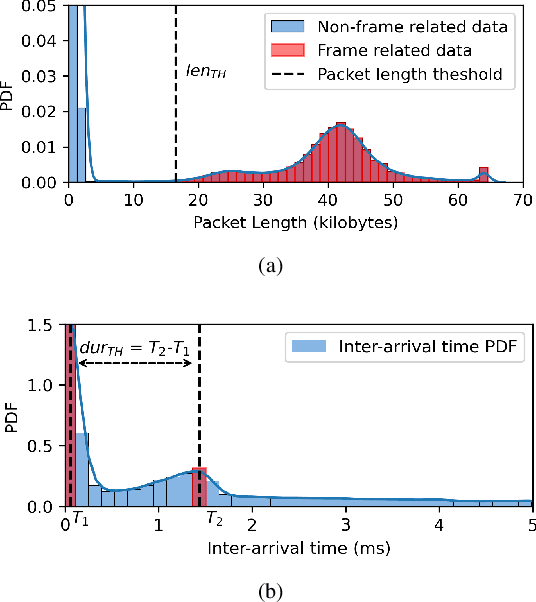
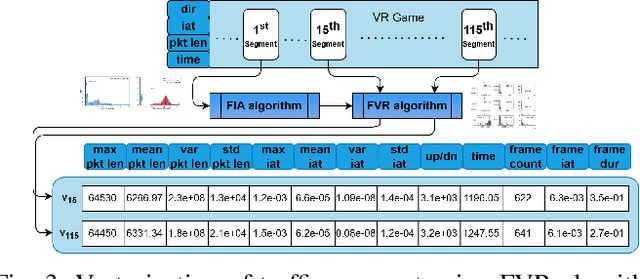
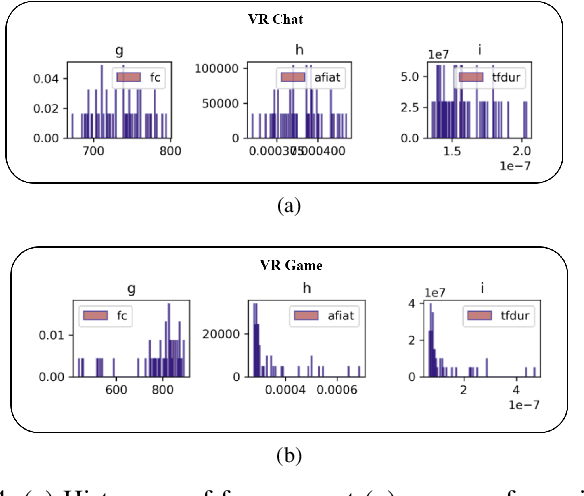
In this paper, we design an exclusive Metaverse network traffic classifier, named Discern-XR, to help Internet service providers (ISP) and router manufacturers enhance the quality of Metaverse services. Leveraging segmented learning, the Frame Vector Representation (FVR) algorithm and Frame Identification Algorithm (FIA) are proposed to extract critical frame-related statistics from raw network data having only four application-level features. A novel Augmentation, Aggregation, and Retention Online Training (A2R-OT) algorithm is proposed to find an accurate classification model through online training methodology. In addition, we contribute to the real-world Metaverse dataset comprising virtual reality (VR) games, VR video, VR chat, augmented reality (AR), and mixed reality (MR) traffic, providing a comprehensive benchmark. Discern-XR outperforms state-of-the-art classifiers by 7% while improving training efficiency and reducing false-negative rates. Our work advances Metaverse network traffic classification by standing as the state-of-the-art solution.
Task-Augmented Cross-View Imputation Network for Partial Multi-View Incomplete Multi-Label Classification
Sep 12, 2024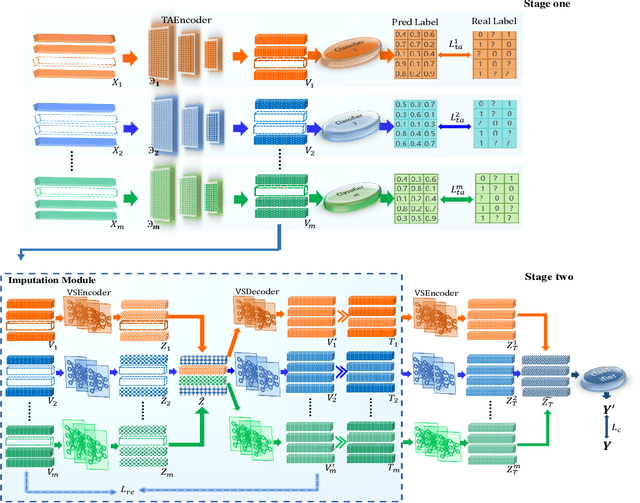
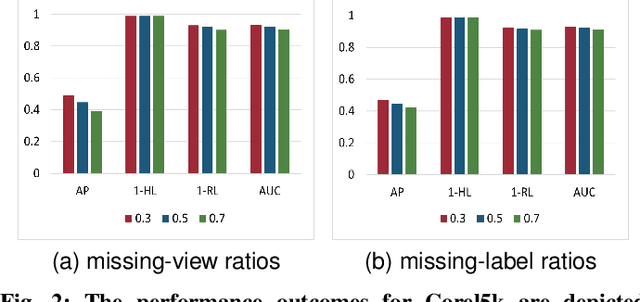
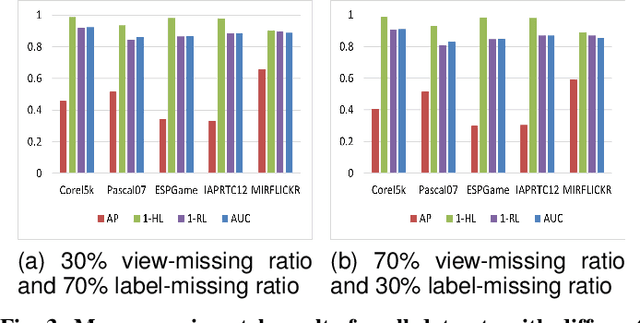
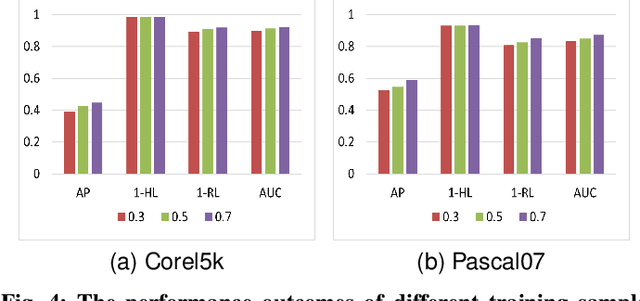
In real-world scenarios, multi-view multi-label learning often encounters the challenge of incomplete training data due to limitations in data collection and unreliable annotation processes. The absence of multi-view features impairs the comprehensive understanding of samples, omitting crucial details essential for classification. To address this issue, we present a task-augmented cross-view imputation network (TACVI-Net) for the purpose of handling partial multi-view incomplete multi-label classification. Specifically, we employ a two-stage network to derive highly task-relevant features to recover the missing views. In the first stage, we leverage the information bottleneck theory to obtain a discriminative representation of each view by extracting task-relevant information through a view-specific encoder-classifier architecture. In the second stage, an autoencoder based multi-view reconstruction network is utilized to extract high-level semantic representation of the augmented features and recover the missing data, thereby aiding the final classification task. Extensive experiments on five datasets demonstrate that our TACVI-Net outperforms other state-of-the-art methods.
Time-Distributed Feature Learning for Internet of Things Network Traffic Classification
Sep 08, 2024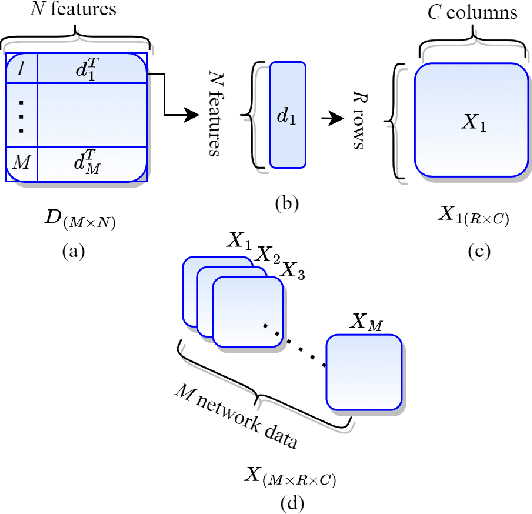
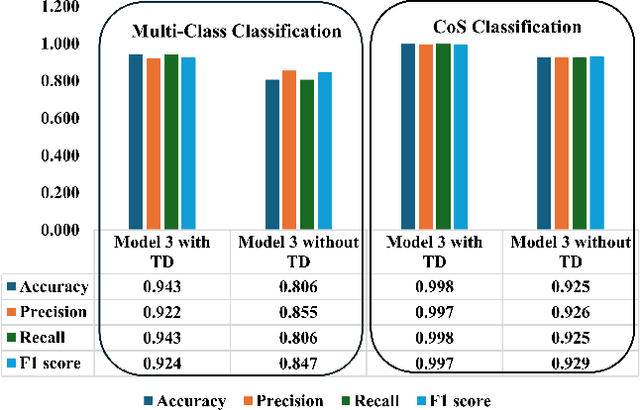
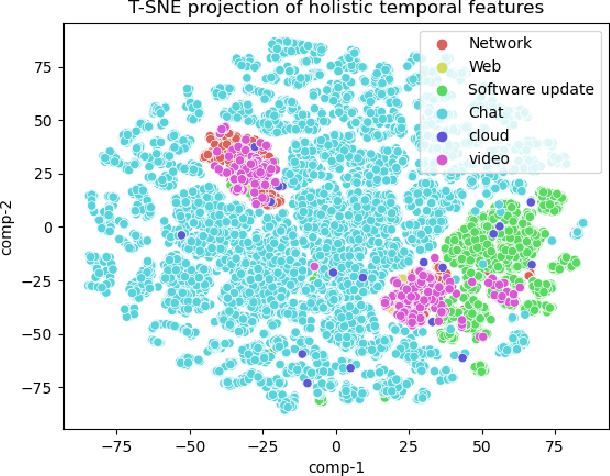
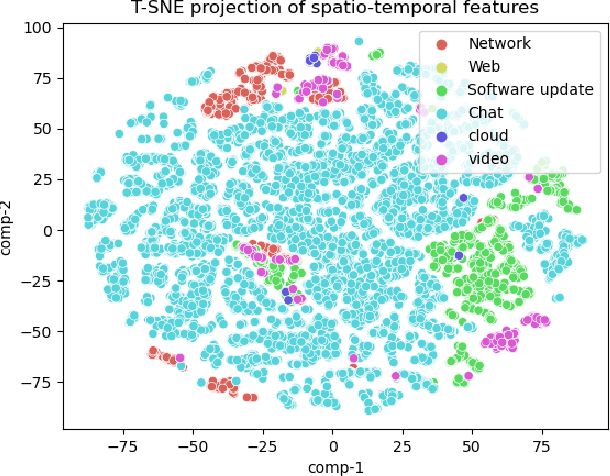
Deep learning-based network traffic classification (NTC) techniques, including conventional and class-of-service (CoS) classifiers, are a popular tool that aids in the quality of service (QoS) and radio resource management for the Internet of Things (IoT) network. Holistic temporal features consist of inter-, intra-, and pseudo-temporal features within packets, between packets, and among flows, providing the maximum information on network services without depending on defined classes in a problem. Conventional spatio-temporal features in the current solutions extract only space and time information between packets and flows, ignoring the information within packets and flow for IoT traffic. Therefore, we propose a new, efficient, holistic feature extraction method for deep-learning-based NTC using time-distributed feature learning to maximize the accuracy of the NTC. We apply a time-distributed wrapper on deep-learning layers to help extract pseudo-temporal features and spatio-temporal features. Pseudo-temporal features are mathematically complex to explain since, in deep learning, a black box extracts them. However, the features are temporal because of the time-distributed wrapper; therefore, we call them pseudo-temporal features. Since our method is efficient in learning holistic-temporal features, we can extend our method to both conventional and CoS NTC. Our solution proves that pseudo-temporal and spatial-temporal features can significantly improve the robustness and performance of any NTC. We analyze the solution theoretically and experimentally on different real-world datasets. The experimental results show that the holistic-temporal time-distributed feature learning method, on average, is 13.5% more accurate than the state-of-the-art conventional and CoS classifiers.
Unveiling and Controlling Anomalous Attention Distribution in Transformers
Jun 26, 2024With the advent of large models based on the Transformer architecture, researchers have observed an anomalous phenomenon in the Attention mechanism--there is a very high attention on the first element, which is prevalent across Transformer-based models. It is crucial to understand it for the development of techniques focusing on attention distribution, such as Key-Value (KV) Cache compression and infinite extrapolation; however, the latent cause leaves to be unknown. In this paper, we analyze such a phenomenon from the perspective of waiver phenomenon, which involves reducing the internal values of certain elements in the Softmax function, allowing them to absorb excess attention without affecting their contribution to information. In specific models, due to differences in positional encoding and attention patterns, we have found that the selection of waiver elements by the model can be categorized into two methods: positional-encoding-based and feature-distribution-within-elements-based.
Unified Joint Matrix-Monotonic Optimization of MIMO Training Sequences and Transceivers
Sep 22, 2022
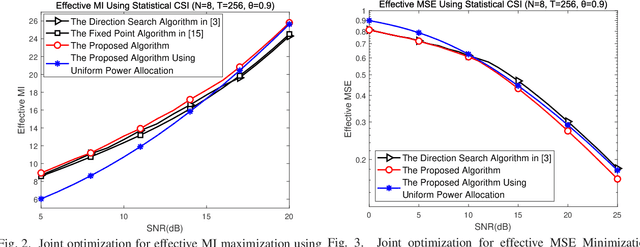
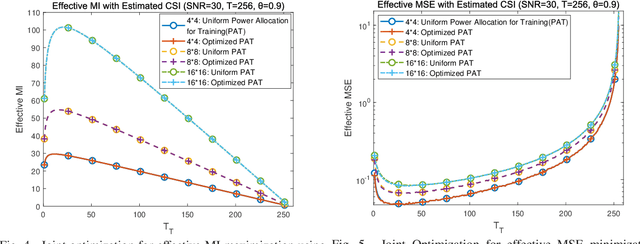
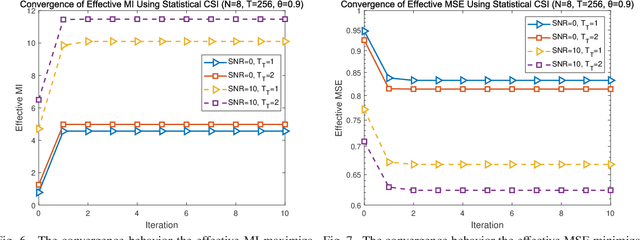
Channel estimation and transmission constitute the most fundamental functional modules of multiple-input multiple-output (MIMO) communication systems. The underlying key tasks corresponding to these modules are training sequence optimization and transceiver optimization. Hence, we jointly optimize the linear transmit precoder and the training sequence of MIMO systems using the metrics of their effective mutual information (MI), effective mean squared error (MSE), effective weighted MI, effective weighted MSE, as well as their effective generic Schur-convex and Schur-concave functions. Both statistical channel state information (CSI) and estimated CSI are considered at the transmitter in the joint optimization. A unified framework termed as joint matrix-monotonic optimization is proposed. Based on this, the optimal precoder matrix and training matrix structures can be derived for both CSI scenarios. Then, based on the optimal matrix structures, our linear transceivers and their training sequences can be jointly optimized. Compared to state-of-the-art benchmark algorithms, the proposed algorithms visualize the bold explicit relationships between the attainable system performance of our linear transceivers conceived and their training sequences, leading to implementation ready recipes. Finally, several numerical results are provided, which corroborate our theoretical results and demonstrate the compelling benefits of our proposed pilot-aided MIMO solutions.
Random Access with Massive MIMO-OTFS in LEO Satellite Communications
Feb 26, 2022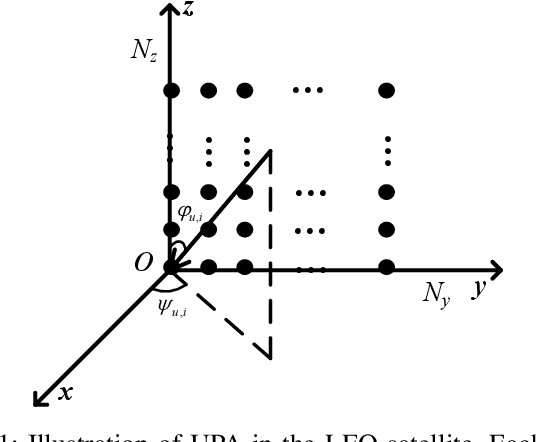
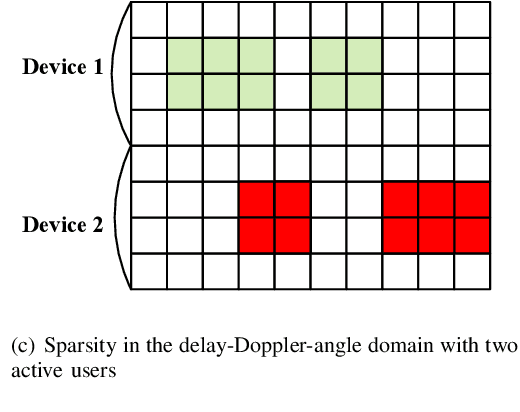
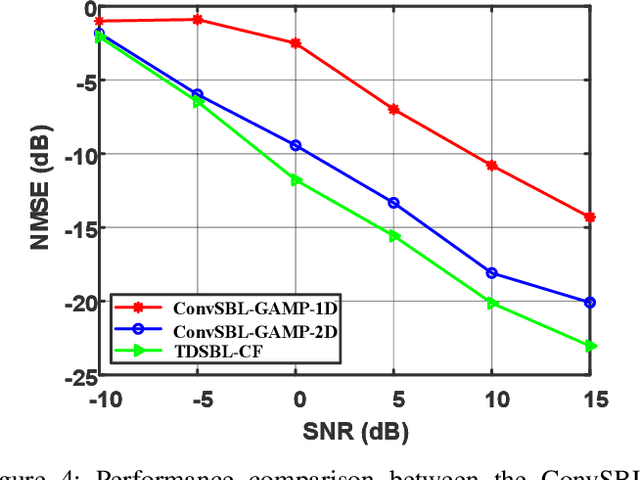
This paper considers the joint channel estimation and device activity detection in the grant-free random access systems, where a large number of Internet-of-Things devices intend to communicate with a low-earth orbit satellite in a sporadic way. In addition, the massive multiple-input multiple-output (MIMO) with orthogonal time-frequency space (OTFS) modulation is adopted to combat the dynamics of the terrestrial-satellite link. We first analyze the input-output relationship of the single-input single-output OTFS when the large delay and Doppler shift both exist, and then extend it to the grant-free random access with massive MIMO-OTFS. Next, by exploring the sparsity of channel in the delay-Doppler-angle domain, a two-dimensional pattern coupled hierarchical prior with the sparse Bayesian learning and covariance-free method (TDSBL-FM) is developed for the channel estimation. Then, the active devices are detected by computing the energy of the estimated channel. Finally, the generalized approximate message passing algorithm combined with the sparse Bayesian learning and two-dimensional convolution (ConvSBL-GAMP) is proposed to decrease the computations of the TDSBL-FM algorithm. Simulation results demonstrate that the proposed algorithms outperform conventional methods.
Deep Reinforcement Learning for Collaborative Edge Computing in Vehicular Networks
Oct 05, 2020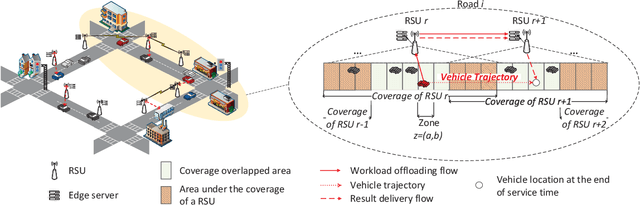
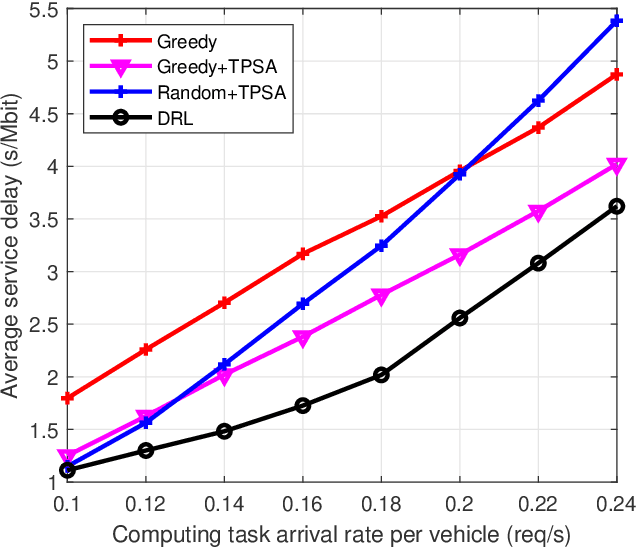
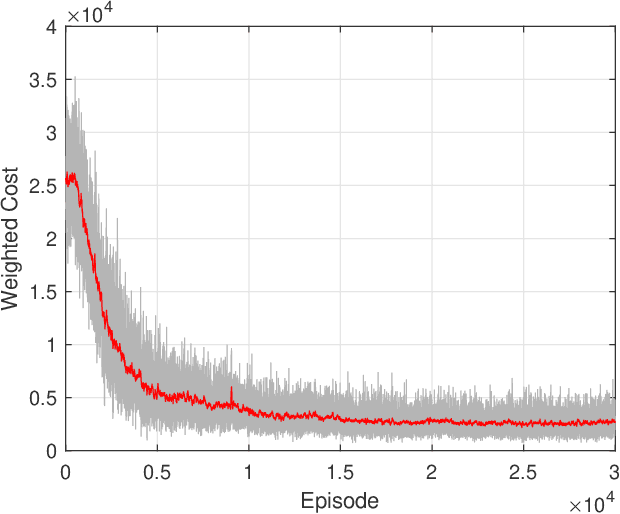
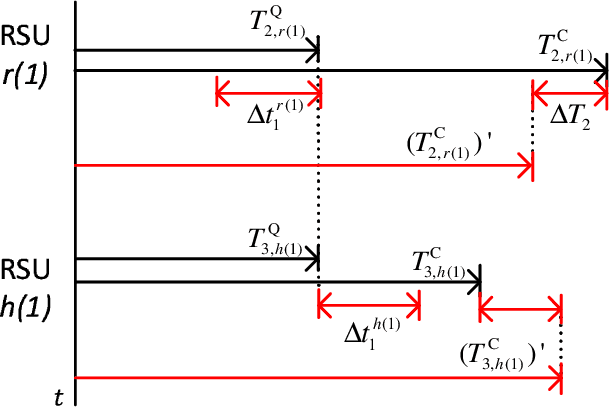
Mobile edge computing (MEC) is a promising technology to support mission-critical vehicular applications, such as intelligent path planning and safety applications. In this paper, a collaborative edge computing framework is developed to reduce the computing service latency and improve service reliability for vehicular networks. First, a task partition and scheduling algorithm (TPSA) is proposed to decide the workload allocation and schedule the execution order of the tasks offloaded to the edge servers given a computation offloading strategy. Second, an artificial intelligence (AI) based collaborative computing approach is developed to determine the task offloading, computing, and result delivery policy for vehicles. Specifically, the offloading and computing problem is formulated as a Markov decision process. A deep reinforcement learning technique, i.e., deep deterministic policy gradient, is adopted to find the optimal solution in a complex urban transportation network. By our approach, the service cost, which includes computing service latency and service failure penalty, can be minimized via the optimal workload assignment and server selection in collaborative computing. Simulation results show that the proposed AI-based collaborative computing approach can adapt to a highly dynamic environment with outstanding performance.