 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Modal Video Feature Extraction for Popularity Prediction
Jan 02, 2025This work aims to predict the popularity of short videos using the videos themselves and their related features. Popularity is measured by four key engagement metrics: view count, like count, comment count, and share count. This study employs video classification models with different architectures and training methods as backbone networks to extract video modality features. Meanwhile, the cleaned video captions are incorporated into a carefully designed prompt framework, along with the video, as input for video-to-text generation models, which generate detailed text-based video content understanding. These texts are then encoded into vectors using a pre-trained BERT model. Based on the six sets of vectors mentioned above, a neural network is trained for each of the four prediction metrics. Moreover, the study conducts data mining and feature engineering based on the video and tabular data, constructing practical features such as the total frequency of hashtag appearances, the total frequency of mention appearances, video duration, frame count, frame rate, and total time online. Multiple machine learning models are trained, and the most stable model, XGBoost, is selected. Finally, the predictions from the neural network and XGBoost models are averaged to obtain the final result.
RecurFormer: Not All Transformer Heads Need Self-Attention
Oct 10, 2024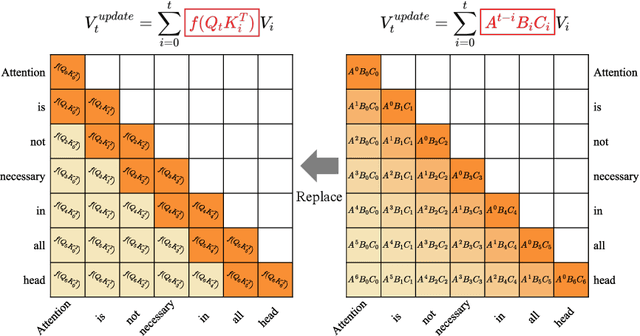
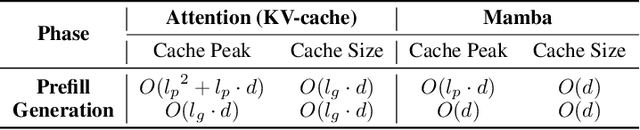
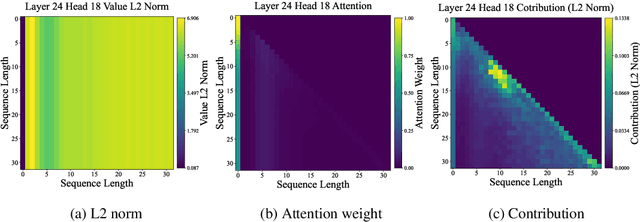
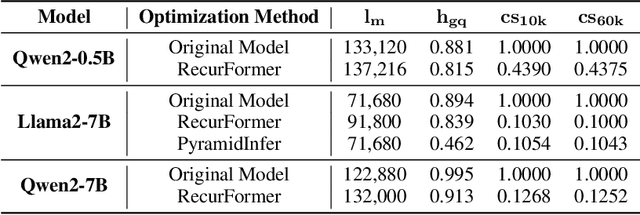
Transformer-based large language models (LLMs) excel in modeling complex language patterns but face significant computational costs during inference, especially with long inputs due to the attention mechanism's memory overhead. We observe that certain attention heads exhibit a distribution where the attention weights concentrate on tokens near the query token, termed as recency aware, which focuses on local and short-range dependencies. Leveraging this insight, we propose RecurFormer, a novel architecture that replaces these attention heads with linear recurrent neural networks (RNNs), specifically the Mamba architecture. This replacement reduces the cache size without evicting tokens, thus maintaining generation quality. RecurFormer retains the ability to model long-range dependencies through the remaining attention heads and allows for reusing pre-trained Transformer-based LLMs weights with continual training. Experiments demonstrate that RecurFormer matches the original model's performance while significantly enhancing inference efficiency. Our approach provides a practical solution to the computational challenges of Transformer-based LLMs inference, making it highly attractive for tasks involving long inputs.
Unveiling and Controlling Anomalous Attention Distribution in Transformers
Jun 26, 2024With the advent of large models based on the Transformer architecture, researchers have observed an anomalous phenomenon in the Attention mechanism--there is a very high attention on the first element, which is prevalent across Transformer-based models. It is crucial to understand it for the development of techniques focusing on attention distribution, such as Key-Value (KV) Cache compression and infinite extrapolation; however, the latent cause leaves to be unknown. In this paper, we analyze such a phenomenon from the perspective of waiver phenomenon, which involves reducing the internal values of certain elements in the Softmax function, allowing them to absorb excess attention without affecting their contribution to information. In specific models, due to differences in positional encoding and attention patterns, we have found that the selection of waiver elements by the model can be categorized into two methods: positional-encoding-based and feature-distribution-within-elements-based.
CAINNFlow: Convolutional block Attention modules and Invertible Neural Networks Flow for anomaly detection and localization tasks
Jun 08, 2022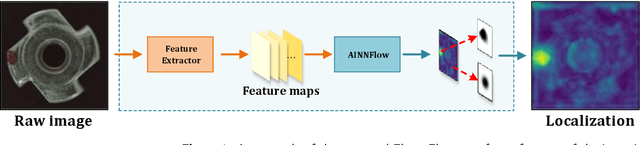
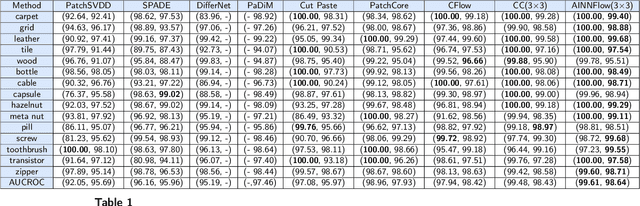
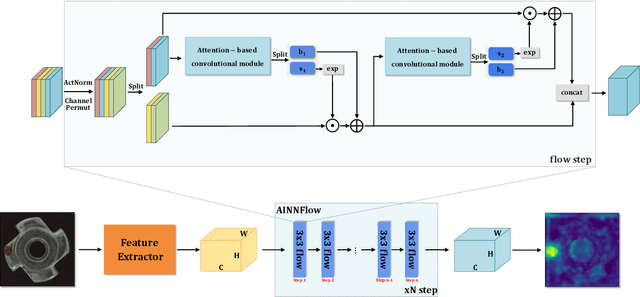
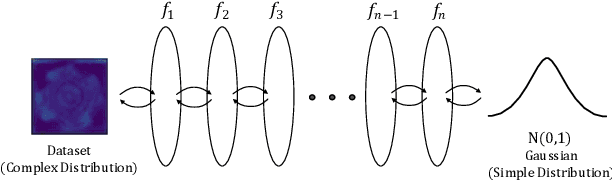
Detection of object anomalies is crucial in industrial processes, but unsupervised anomaly detection and localization is particularly important due to the difficulty of obtaining a large number of defective samples and the unpredictable types of anomalies in real life. Among the existing unsupervised anomaly detection and localization methods, the NF-based scheme has achieved better results. However, the two subnets (complex functions) $s_{i}(u_{i})$ and $t_{i}(u_{i})$ in NF are usually multilayer perceptrons, which need to squeeze the input visual features from 2D flattening to 1D, destroying the spatial location relationship in the feature map and losing the spatial structure information. In order to retain and effectively extract spatial structure information, we design in this study a complex function model with alternating CBAM embedded in a stacked $3\times3$ full convolution, which is able to retain and effectively extract spatial structure information in the normalized flow model. Extensive experimental results on the MVTec AD dataset show that CAINNFlow achieves advanced levels of accuracy and inference efficiency based on CNN and Transformer backbone networks as feature extractors, and CAINNFlow achieves a pixel-level AUC of $98.64\%$ for anomaly detection in MVTec AD.