 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHunyuan-TurboS: Advancing Large Language Models through Mamba-Transformer Synergy and Adaptive Chain-of-Thought
May 21, 2025As Large Language Models (LLMs) rapidly advance, we introduce Hunyuan-TurboS, a novel large hybrid Transformer-Mamba Mixture of Experts (MoE) model. It synergistically combines Mamba's long-sequence processing efficiency with Transformer's superior contextual understanding. Hunyuan-TurboS features an adaptive long-short chain-of-thought (CoT) mechanism, dynamically switching between rapid responses for simple queries and deep "thinking" modes for complex problems, optimizing computational resources. Architecturally, this 56B activated (560B total) parameter model employs 128 layers (Mamba2, Attention, FFN) with an innovative AMF/MF block pattern. Faster Mamba2 ensures linear complexity, Grouped-Query Attention minimizes KV cache, and FFNs use an MoE structure. Pre-trained on 16T high-quality tokens, it supports a 256K context length and is the first industry-deployed large-scale Mamba model. Our comprehensive post-training strategy enhances capabilities via Supervised Fine-Tuning (3M instructions), a novel Adaptive Long-short CoT Fusion method, Multi-round Deliberation Learning for iterative improvement, and a two-stage Large-scale Reinforcement Learning process targeting STEM and general instruction-following. Evaluations show strong performance: overall top 7 rank on LMSYS Chatbot Arena with a score of 1356, outperforming leading models like Gemini-2.0-Flash-001 (1352) and o4-mini-2025-04-16 (1345). TurboS also achieves an average of 77.9% across 23 automated benchmarks. Hunyuan-TurboS balances high performance and efficiency, offering substantial capabilities at lower inference costs than many reasoning models, establishing a new paradigm for efficient large-scale pre-trained models.
Hunyuan-Large: An Open-Source MoE Model with 52 Billion Activated Parameters by Tencent
Nov 05, 2024



In this paper, we introduce Hunyuan-Large, which is currently the largest open-source Transformer-based mixture of experts model, with a total of 389 billion parameters and 52 billion activation parameters, capable of handling up to 256K tokens. We conduct a thorough evaluation of Hunyuan-Large's superior performance across various benchmarks including language understanding and generation, logical reasoning, mathematical problem-solving, coding, long-context, and aggregated tasks, where it outperforms LLama3.1-70B and exhibits comparable performance when compared to the significantly larger LLama3.1-405B model. Key practice of Hunyuan-Large include large-scale synthetic data that is orders larger than in previous literature, a mixed expert routing strategy, a key-value cache compression technique, and an expert-specific learning rate strategy. Additionally, we also investigate the scaling laws and learning rate schedule of mixture of experts models, providing valuable insights and guidances for future model development and optimization. The code and checkpoints of Hunyuan-Large are released to facilitate future innovations and applications. Codes: https://github.com/Tencent/Hunyuan-Large Models: https://huggingface.co/tencent/Tencent-Hunyuan-Large
CAINNFlow: Convolutional block Attention modules and Invertible Neural Networks Flow for anomaly detection and localization tasks
Jun 08, 2022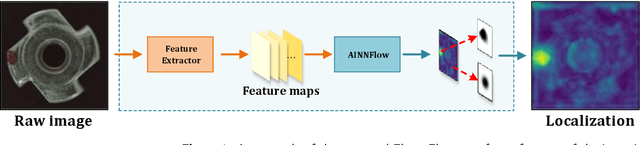
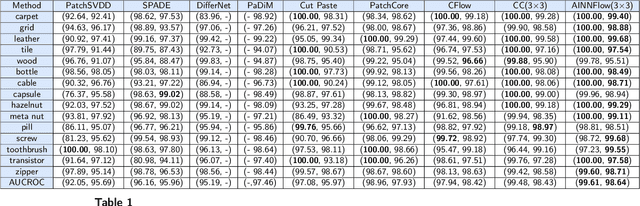
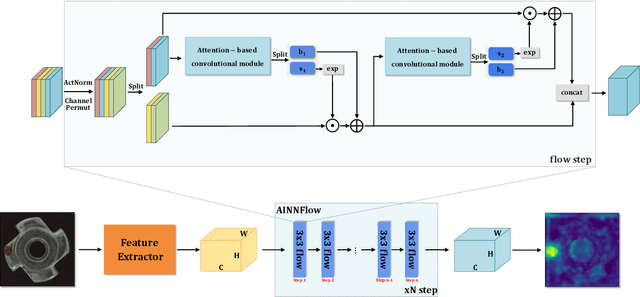
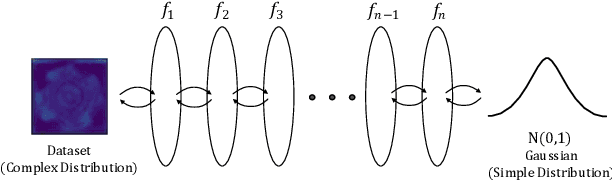
Detection of object anomalies is crucial in industrial processes, but unsupervised anomaly detection and localization is particularly important due to the difficulty of obtaining a large number of defective samples and the unpredictable types of anomalies in real life. Among the existing unsupervised anomaly detection and localization methods, the NF-based scheme has achieved better results. However, the two subnets (complex functions) $s_{i}(u_{i})$ and $t_{i}(u_{i})$ in NF are usually multilayer perceptrons, which need to squeeze the input visual features from 2D flattening to 1D, destroying the spatial location relationship in the feature map and losing the spatial structure information. In order to retain and effectively extract spatial structure information, we design in this study a complex function model with alternating CBAM embedded in a stacked $3\times3$ full convolution, which is able to retain and effectively extract spatial structure information in the normalized flow model. Extensive experimental results on the MVTec AD dataset show that CAINNFlow achieves advanced levels of accuracy and inference efficiency based on CNN and Transformer backbone networks as feature extractors, and CAINNFlow achieves a pixel-level AUC of $98.64\%$ for anomaly detection in MVTec AD.
AI Online Filters to Real World Image Recognition
Feb 11, 2020
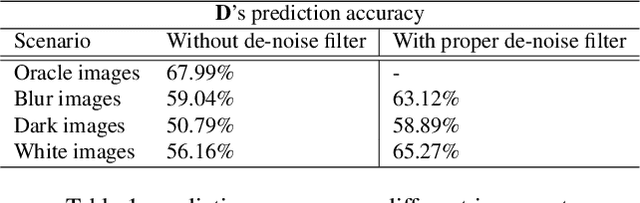

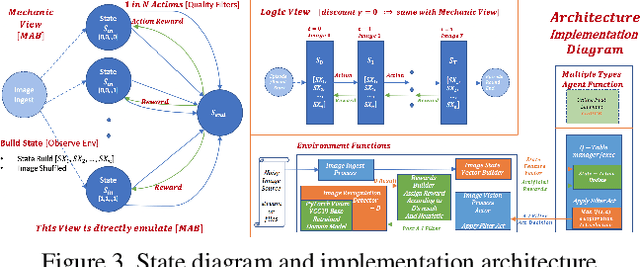
Deep artificial neural networks, trained with labeled data sets are widely used in numerous vision and robotics applications today. In terms of AI, these are called reflex models, referring to the fact that they do not self-evolve or actively adapt to environmental changes. As demand for intelligent robot control expands to many high level tasks, reinforcement learning and state based models play an increasingly important role. Herein, in computer vision and robotics domain, we study a novel approach to add reinforcement controls onto the image recognition reflex models to attain better overall performance, specifically to a wider environment range beyond what is expected of the task reflex models. Follow a common infrastructure with environment sensing and AI based modeling of self-adaptive agents, we implement multiple types of AI control agents. To the end, we provide comparative results of these agents with baseline, and an insightful analysis of their benefit to improve overall image recognition performance in real world.