 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised Learning Matters: A Simple Ensemble Solution for Micro-Gesture Recognition
Jun 08, 2026In this paper, we present XInsight Lab's solution to the micro-gesture classification track of the 4th MiGA Challenge at IJCAI 2026, in which our solution ranked first and achieved a new state-of-the-art result. We propose a multimodal ensemble framework that integrates a self-supervised RGB-based model with supervised multi-stream models from previous solutions. The self-supervised RGB model is pretrained on 120K unlabeled clips via masked video modeling and then fine-tuned on iMiGUE. This simple yet effective RGB baseline achieves 69.224% top-1 accuracy on the iMiGUE test set, demonstrating the benefit of learning transferable representations from unlabeled in-domain videos. By incorporating this model as a complementary branch, the final ensemble reaches 74.419% top-1 accuracy, surpassing the previous state of the art by 1.206 percentage points. Experimental results on iMiGUE, including ablation studies on the ensemble strategy, validate the effectiveness of self-supervised RGB representation learning for micro-gesture recognition.
Kaiwu-PyTorch-Plugin: Bridging Deep Learning and Photonic Quantum Computing for Energy-Based Models and Active Sample Selection
Feb 22, 2026This paper introduces the Kaiwu-PyTorch-Plugin (KPP) to bridge Deep Learning and Photonic Quantum Computing across multiple dimensions. KPP integrates the Coherent Ising Machine into the PyTorch ecosystem, addressing classical inefficiencies in Energy-Based Models. The framework facilitates quantum integration in three key aspects: accelerating Boltzmann sampling, optimizing training data via Active Sampling, and constructing hybrid architectures like QBM-VAE and Q-Diffusion. Empirical results on single-cell and OpenWebText datasets demonstrate KPPs ability to achieve SOTA performance, validating a comprehensive quantum-classical paradigm.
Tighnari v2: Mitigating Label Noise and Distribution Shift in Multimodal Plant Distribution Prediction via Mixture of Experts and Weakly Supervised Learning
Feb 09, 2026Large-scale, cross-species plant distribution prediction plays a crucial role in biodiversity conservation, yet modeling efforts in this area still face significant challenges due to the sparsity and bias of observational data. Presence-Absence (PA) data provide accurate and noise-free labels, but are costly to obtain and limited in quantity; Presence-Only (PO) data, by contrast, offer broad spatial coverage and rich spatiotemporal distribution, but suffer from severe label noise in negative samples. To address these real-world constraints, this paper proposes a multimodal fusion framework that fully leverages the strengths of both PA and PO data. We introduce an innovative pseudo-label aggregation strategy for PO data based on the geographic coverage of satellite imagery, enabling geographic alignment between the label space and remote sensing feature space. In terms of model architecture, we adopt Swin Transformer Base as the backbone for satellite imagery, utilize the TabM network for tabular feature extraction, retain the Temporal Swin Transformer for time-series modeling, and employ a stackable serial tri-modal cross-attention mechanism to optimize the fusion of heterogeneous modalities. Furthermore, empirical analysis reveals significant geographic distribution shifts between PA training and test samples, and models trained by directly mixing PO and PA data tend to experience performance degradation due to label noise in PO data. To address this, we draw on the mixture-of-experts paradigm: test samples are partitioned according to their spatial proximity to PA samples, and different models trained on distinct datasets are used for inference and post-processing within each partition. Experiments on the GeoLifeCLEF 2025 dataset demonstrate that our approach achieves superior predictive performance in scenarios with limited PA coverage and pronounced distribution shifts.
Weak to Strong: VLM-Based Pseudo-Labeling as a Weakly Supervised Training Strategy in Multimodal Video-based Hidden Emotion Understanding Tasks
Feb 08, 2026To tackle the automatic recognition of "concealed emotions" in videos, this paper proposes a multimodal weak-supervision framework and achieves state-of-the-art results on the iMiGUE tennis-interview dataset. First, YOLO 11x detects and crops human portraits frame-by-frame, and DINOv2-Base extracts visual features from the cropped regions. Next, by integrating Chain-of-Thought and Reflection prompting (CoT + Reflection), Gemini 2.5 Pro automatically generates pseudo-labels and reasoning texts that serve as weak supervision for downstream models. Subsequently, OpenPose produces 137-dimensional key-point sequences, augmented with inter-frame offset features; the usual graph neural network backbone is simplified to an MLP to efficiently model the spatiotemporal relationships of the three key-point streams. An ultra-long-sequence Transformer independently encodes both the image and key-point sequences, and their representations are concatenated with BERT-encoded interview transcripts. Each modality is first pre-trained in isolation, then fine-tuned jointly, with pseudo-labeled samples merged into the training set for further gains. Experiments demonstrate that, despite severe class imbalance, the proposed approach lifts accuracy from under 0.6 in prior work to over 0.69, establishing a new public benchmark. The study also validates that an "MLP-ified" key-point backbone can match - or even surpass - GCN-based counterparts in this task.
Tighnari: Multi-modal Plant Species Prediction Based on Hierarchical Cross-Attention Using Graph-Based and Vision Backbone-Extracted Features
Jan 05, 2025



Predicting plant species composition in specific spatiotemporal contexts plays an important role in biodiversity management and conservation, as well as in improving species identification tools. Our work utilizes 88,987 plant survey records conducted in specific spatiotemporal contexts across Europe. We also use the corresponding satellite images, time series data, climate time series, and other rasterized environmental data such as land cover, human footprint, bioclimatic, and soil variables as training data to train the model to predict the outcomes of 4,716 plant surveys. We propose a feature construction and result correction method based on the graph structure. Through comparative experiments, we select the best-performing backbone networks for feature extraction in both temporal and image modalities. In this process, we built a backbone network based on the Swin-Transformer Block for extracting temporal Cubes features. We then design a hierarchical cross-attention mechanism capable of robustly fusing features from multiple modalities. During training, we adopt a 10-fold cross-fusion method based on fine-tuning and use a Threshold Top-K method for post-processing. Ablation experiments demonstrate the improvements in model performance brought by our proposed solution pipeline.
Google is all you need: Semi-Supervised Transfer Learning Strategy For Light Multimodal Multi-Task Classification Model
Jan 03, 2025


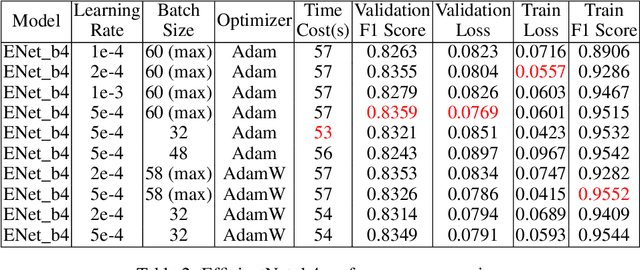
As the volume of digital image data increases, the effectiveness of image classification intensifies. This study introduces a robust multi-label classification system designed to assign multiple labels to a single image, addressing the complexity of images that may be associated with multiple categories (ranging from 1 to 19, excluding 12). We propose a multi-modal classifier that merges advanced image recognition algorithms with Natural Language Processing (NLP) models, incorporating a fusion module to integrate these distinct modalities. The purpose of integrating textual data is to enhance the accuracy of label prediction by providing contextual understanding that visual analysis alone cannot fully capture. Our proposed classification model combines Convolutional Neural Networks (CNN) for image processing with NLP techniques for analyzing textual description (i.e., captions). This approach includes rigorous training and validation phases, with each model component verified and analyzed through ablation experiments. Preliminary results demonstrate the classifier's accuracy and efficiency, highlighting its potential as an automatic image-labeling system.
nnY-Net: Swin-NeXt with Cross-Attention for 3D Medical Images Segmentation
Jan 02, 2025This paper provides a novel 3D medical image segmentation model structure called nnY-Net. This name comes from the fact that our model adds a cross-attention module at the bottom of the U-net structure to form a Y structure. We integrate the advantages of the two latest SOTA models, MedNeXt and SwinUNETR, and use Swin Transformer as the encoder and ConvNeXt as the decoder to innovatively design the Swin-NeXt structure. Our model uses the lowest-level feature map of the encoder as Key and Value and uses patient features such as pathology and treatment information as Query to calculate the attention weights in a Cross Attention module. Moreover, we simplify some pre- and post-processing as well as data enhancement methods in 3D image segmentation based on the dynUnet and nnU-net frameworks. We integrate our proposed Swin-NeXt with Cross-Attention framework into this framework. Last, we construct a DiceFocalCELoss to improve the training efficiency for the uneven data convergence of voxel classification.
Best Transition Matrix Esitimation or Best Label Noise Robustness Classifier? Two Possible Methods to Enhance the Performance of T-revision
Jan 02, 2025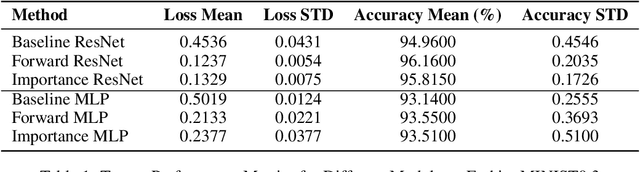
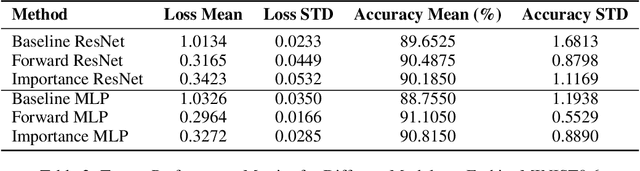
Label noise refers to incorrect labels in a dataset caused by human errors or collection defects, which is common in real-world applications and can significantly reduce the accuracy of models. This report explores how to estimate noise transition matrices and construct deep learning classifiers that are robust against label noise. In cases where the transition matrix is known, we apply forward correction and importance reweighting methods to correct the impact of label noise using the transition matrix. When the transition matrix is unknown or inaccurate, we use the anchor point assumption and T-Revision series methods to estimate or correct the noise matrix. In this study, we further improved the T-Revision method by developing T-Revision-Alpha and T-Revision-Softmax to enhance stability and robustness. Additionally, we designed and implemented two baseline classifiers, a Multi-Layer Perceptron (MLP) and ResNet-18, based on the cross-entropy loss function. We compared the performance of these methods on predicting clean labels and estimating transition matrices using the FashionMINIST dataset with known noise transition matrices. For the CIFAR-10 dataset, where the noise transition matrix is unknown, we estimated the noise matrix and evaluated the ability of the methods to predict clean labels.
Multi-Modal Video Feature Extraction for Popularity Prediction
Jan 02, 2025This work aims to predict the popularity of short videos using the videos themselves and their related features. Popularity is measured by four key engagement metrics: view count, like count, comment count, and share count. This study employs video classification models with different architectures and training methods as backbone networks to extract video modality features. Meanwhile, the cleaned video captions are incorporated into a carefully designed prompt framework, along with the video, as input for video-to-text generation models, which generate detailed text-based video content understanding. These texts are then encoded into vectors using a pre-trained BERT model. Based on the six sets of vectors mentioned above, a neural network is trained for each of the four prediction metrics. Moreover, the study conducts data mining and feature engineering based on the video and tabular data, constructing practical features such as the total frequency of hashtag appearances, the total frequency of mention appearances, video duration, frame count, frame rate, and total time online. Multiple machine learning models are trained, and the most stable model, XGBoost, is selected. Finally, the predictions from the neural network and XGBoost models are averaged to obtain the final result.