 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraphOmni: A Comprehensive and Extendable Benchmark Framework for Large Language Models on Graph-theoretic Tasks
Apr 17, 2025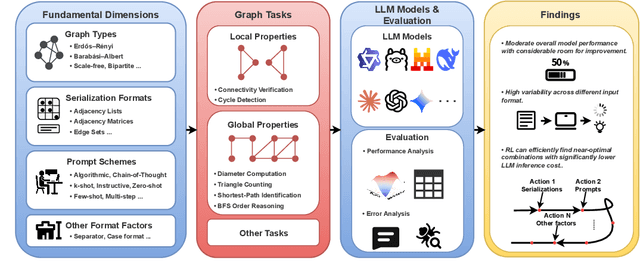

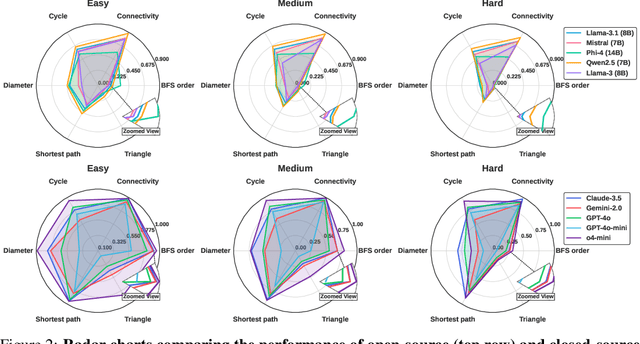
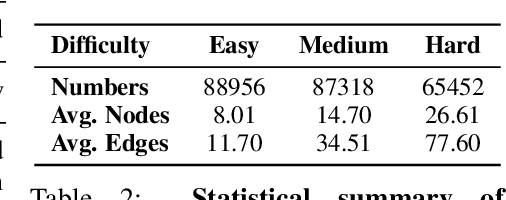
In this paper, we presented GraphOmni, a comprehensive benchmark framework for systematically evaluating the graph reasoning capabilities of LLMs. By analyzing critical dimensions, including graph types, serialization formats, and prompt schemes, we provided extensive insights into the strengths and limitations of current LLMs. Our empirical findings emphasize that no single serialization or prompting strategy consistently outperforms others. Motivated by these insights, we propose a reinforcement learning-based approach that dynamically selects the best serialization-prompt pairings, resulting in significant accuracy improvements. GraphOmni's modular and extensible design establishes a robust foundation for future research, facilitating advancements toward general-purpose graph reasoning models.
Tighnari: Multi-modal Plant Species Prediction Based on Hierarchical Cross-Attention Using Graph-Based and Vision Backbone-Extracted Features
Jan 05, 2025



Predicting plant species composition in specific spatiotemporal contexts plays an important role in biodiversity management and conservation, as well as in improving species identification tools. Our work utilizes 88,987 plant survey records conducted in specific spatiotemporal contexts across Europe. We also use the corresponding satellite images, time series data, climate time series, and other rasterized environmental data such as land cover, human footprint, bioclimatic, and soil variables as training data to train the model to predict the outcomes of 4,716 plant surveys. We propose a feature construction and result correction method based on the graph structure. Through comparative experiments, we select the best-performing backbone networks for feature extraction in both temporal and image modalities. In this process, we built a backbone network based on the Swin-Transformer Block for extracting temporal Cubes features. We then design a hierarchical cross-attention mechanism capable of robustly fusing features from multiple modalities. During training, we adopt a 10-fold cross-fusion method based on fine-tuning and use a Threshold Top-K method for post-processing. Ablation experiments demonstrate the improvements in model performance brought by our proposed solution pipeline.
nnY-Net: Swin-NeXt with Cross-Attention for 3D Medical Images Segmentation
Jan 02, 2025This paper provides a novel 3D medical image segmentation model structure called nnY-Net. This name comes from the fact that our model adds a cross-attention module at the bottom of the U-net structure to form a Y structure. We integrate the advantages of the two latest SOTA models, MedNeXt and SwinUNETR, and use Swin Transformer as the encoder and ConvNeXt as the decoder to innovatively design the Swin-NeXt structure. Our model uses the lowest-level feature map of the encoder as Key and Value and uses patient features such as pathology and treatment information as Query to calculate the attention weights in a Cross Attention module. Moreover, we simplify some pre- and post-processing as well as data enhancement methods in 3D image segmentation based on the dynUnet and nnU-net frameworks. We integrate our proposed Swin-NeXt with Cross-Attention framework into this framework. Last, we construct a DiceFocalCELoss to improve the training efficiency for the uneven data convergence of voxel classification.
Multi-Modal Video Feature Extraction for Popularity Prediction
Jan 02, 2025This work aims to predict the popularity of short videos using the videos themselves and their related features. Popularity is measured by four key engagement metrics: view count, like count, comment count, and share count. This study employs video classification models with different architectures and training methods as backbone networks to extract video modality features. Meanwhile, the cleaned video captions are incorporated into a carefully designed prompt framework, along with the video, as input for video-to-text generation models, which generate detailed text-based video content understanding. These texts are then encoded into vectors using a pre-trained BERT model. Based on the six sets of vectors mentioned above, a neural network is trained for each of the four prediction metrics. Moreover, the study conducts data mining and feature engineering based on the video and tabular data, constructing practical features such as the total frequency of hashtag appearances, the total frequency of mention appearances, video duration, frame count, frame rate, and total time online. Multiple machine learning models are trained, and the most stable model, XGBoost, is selected. Finally, the predictions from the neural network and XGBoost models are averaged to obtain the final result.
Unveiling and Controlling Anomalous Attention Distribution in Transformers
Jun 26, 2024With the advent of large models based on the Transformer architecture, researchers have observed an anomalous phenomenon in the Attention mechanism--there is a very high attention on the first element, which is prevalent across Transformer-based models. It is crucial to understand it for the development of techniques focusing on attention distribution, such as Key-Value (KV) Cache compression and infinite extrapolation; however, the latent cause leaves to be unknown. In this paper, we analyze such a phenomenon from the perspective of waiver phenomenon, which involves reducing the internal values of certain elements in the Softmax function, allowing them to absorb excess attention without affecting their contribution to information. In specific models, due to differences in positional encoding and attention patterns, we have found that the selection of waiver elements by the model can be categorized into two methods: positional-encoding-based and feature-distribution-within-elements-based.
Online Planning of Power Flows for Power Systems Against Bushfires Using Spatial Context
Apr 20, 2024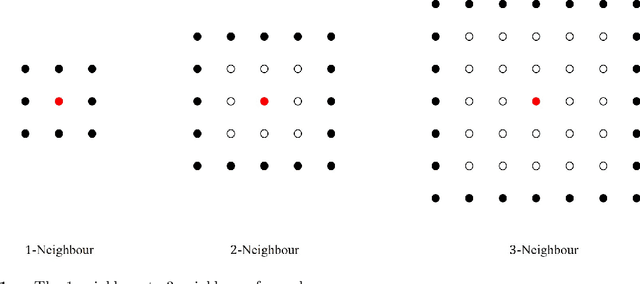

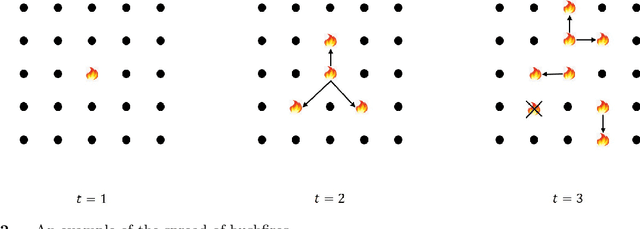
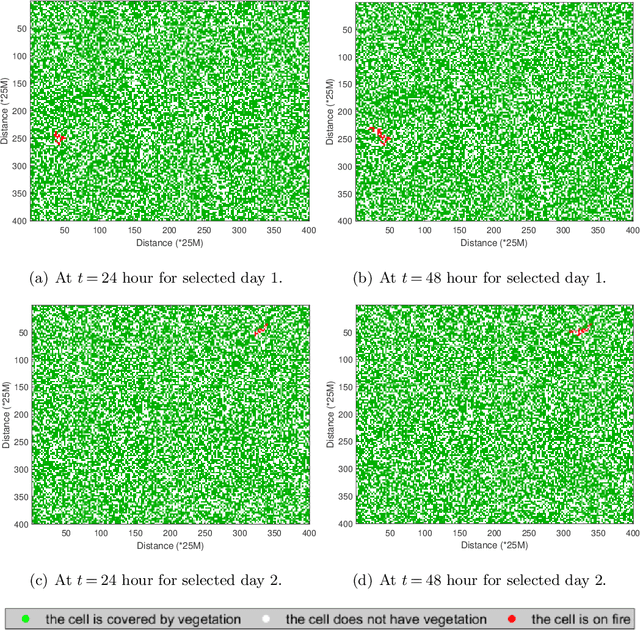
The 2019-20 Australia bushfire incurred numerous economic losses and significantly affected the operations of power systems. A power station or transmission line can be significantly affected due to bushfires, leading to an increase in operational costs. We study a fundamental but challenging problem of planning the optimal power flow (OPF) for power systems subject to bushfires. Considering the stochastic nature of bushfire spread, we develop a model to capture such dynamics based on Moore's neighborhood model. Under a periodic inspection scheme that reveals the in-situ bushfire status, we propose an online optimization modeling framework that sequentially plans the power flows in the electricity network. Our framework assumes that the spread of bushfires is non-stationary over time, and the spread and containment probabilities are unknown. To meet these challenges, we develop a contextual online learning algorithm that treats the in-situ geographical information of the bushfire as a 'spatial context'. The online learning algorithm learns the unknown probabilities sequentially based on the observed data and then makes the OPF decision accordingly. The sequential OPF decisions aim to minimize the regret function, which is defined as the cumulative loss against the clairvoyant strategy that knows the true model parameters. We provide a theoretical guarantee of our algorithm by deriving a bound on the regret function, which outperforms the regret bound achieved by other benchmark algorithms. Our model assumptions are verified by the real bushfire data from NSW, Australia, and we apply our model to two power systems to illustrate its applicability.