 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRulePlanner: All-in-One Reinforcement Learner for Unifying Design Rules in 3D Floorplanning
Jan 30, 2026Floorplanning determines the coordinate and shape of each module in Integrated Circuits. With the scaling of technology nodes, in floorplanning stage especially 3D scenarios with multiple stacked layers, it has become increasingly challenging to adhere to complex hardware design rules. Current methods are only capable of handling specific and limited design rules, while violations of other rules require manual and meticulous adjustment. This leads to labor-intensive and time-consuming post-processing for expert engineers. In this paper, we propose an all-in-one deep reinforcement learning-based approach to tackle these challenges, and design novel representations for real-world IC design rules that have not been addressed by previous approaches. Specifically, the processing of various hardware design rules is unified into a single framework with three key components: 1) novel matrix representations to model the design rules, 2) constraints on the action space to filter out invalid actions that cause rule violations, and 3) quantitative analysis of constraint satisfaction as reward signals. Experiments on public benchmarks demonstrate the effectiveness and validity of our approach. Furthermore, transferability is well demonstrated on unseen circuits. Our framework is extensible to accommodate new design rules, thus providing flexibility to address emerging challenges in future chip design. Code will be available at: https://github.com/Thinklab-SJTU/EDA-AI
MemR$^3$: Memory Retrieval via Reflective Reasoning for LLM Agents
Dec 23, 2025Memory systems have been designed to leverage past experiences in Large Language Model (LLM) agents. However, many deployed memory systems primarily optimize compression and storage, with comparatively less emphasis on explicit, closed-loop control of memory retrieval. From this observation, we build memory retrieval as an autonomous, accurate, and compatible agent system, named MemR$^3$, which has two core mechanisms: 1) a router that selects among retrieve, reflect, and answer actions to optimize answer quality; 2) a global evidence-gap tracker that explicitly renders the answering process transparent and tracks the evidence collection process. This design departs from the standard retrieve-then-answer pipeline by introducing a closed-loop control mechanism that enables autonomous decision-making. Empirical results on the LoCoMo benchmark demonstrate that MemR$^3$ surpasses strong baselines on LLM-as-a-Judge score, and particularly, it improves existing retrievers across four categories with an overall improvement on RAG (+7.29%) and Zep (+1.94%) using GPT-4.1-mini backend, offering a plug-and-play controller for existing memory stores.
Flexible Concept Bottleneck Model
Nov 10, 2025Concept bottleneck models (CBMs) improve neural network interpretability by introducing an intermediate layer that maps human-understandable concepts to predictions. Recent work has explored the use of vision-language models (VLMs) to automate concept selection and annotation. However, existing VLM-based CBMs typically require full model retraining when new concepts are involved, which limits their adaptability and flexibility in real-world scenarios, especially considering the rapid evolution of vision-language foundation models. To address these issues, we propose Flexible Concept Bottleneck Model (FCBM), which supports dynamic concept adaptation, including complete replacement of the original concept set. Specifically, we design a hypernetwork that generates prediction weights based on concept embeddings, allowing seamless integration of new concepts without retraining the entire model. In addition, we introduce a modified sparsemax module with a learnable temperature parameter that dynamically selects the most relevant concepts, enabling the model to focus on the most informative features. Extensive experiments on five public benchmarks demonstrate that our method achieves accuracy comparable to state-of-the-art baselines with a similar number of effective concepts. Moreover, the model generalizes well to unseen concepts with just a single epoch of fine-tuning, demonstrating its strong adaptability and flexibility.
RecurFormer: Not All Transformer Heads Need Self-Attention
Oct 10, 2024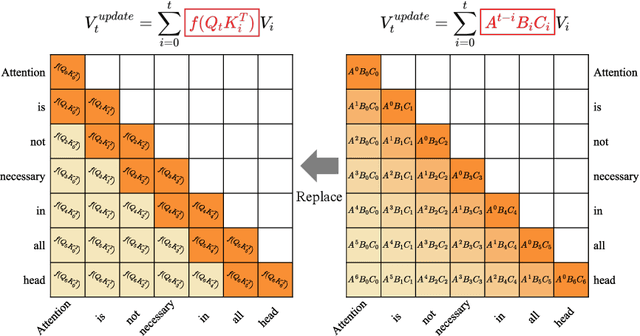
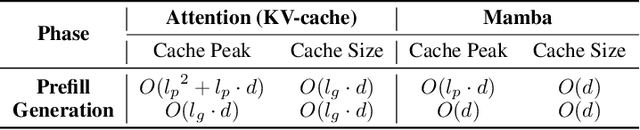
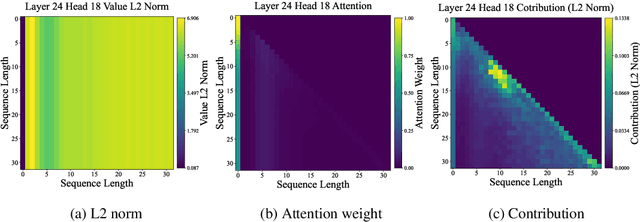
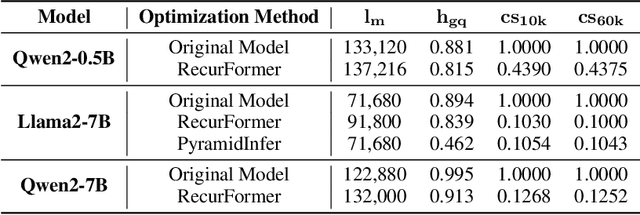
Transformer-based large language models (LLMs) excel in modeling complex language patterns but face significant computational costs during inference, especially with long inputs due to the attention mechanism's memory overhead. We observe that certain attention heads exhibit a distribution where the attention weights concentrate on tokens near the query token, termed as recency aware, which focuses on local and short-range dependencies. Leveraging this insight, we propose RecurFormer, a novel architecture that replaces these attention heads with linear recurrent neural networks (RNNs), specifically the Mamba architecture. This replacement reduces the cache size without evicting tokens, thus maintaining generation quality. RecurFormer retains the ability to model long-range dependencies through the remaining attention heads and allows for reusing pre-trained Transformer-based LLMs weights with continual training. Experiments demonstrate that RecurFormer matches the original model's performance while significantly enhancing inference efficiency. Our approach provides a practical solution to the computational challenges of Transformer-based LLMs inference, making it highly attractive for tasks involving long inputs.
Unveiling and Controlling Anomalous Attention Distribution in Transformers
Jun 26, 2024With the advent of large models based on the Transformer architecture, researchers have observed an anomalous phenomenon in the Attention mechanism--there is a very high attention on the first element, which is prevalent across Transformer-based models. It is crucial to understand it for the development of techniques focusing on attention distribution, such as Key-Value (KV) Cache compression and infinite extrapolation; however, the latent cause leaves to be unknown. In this paper, we analyze such a phenomenon from the perspective of waiver phenomenon, which involves reducing the internal values of certain elements in the Softmax function, allowing them to absorb excess attention without affecting their contribution to information. In specific models, due to differences in positional encoding and attention patterns, we have found that the selection of waiver elements by the model can be categorized into two methods: positional-encoding-based and feature-distribution-within-elements-based.