 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMore than Segmentation: Benchmarking SAM 3 for Segmentation, 3D Perception, and Reconstruction in Robotic Surgery
Dec 10, 2025The recent SAM 3 and SAM 3D have introduced significant advancements over the predecessor, SAM 2, particularly with the integration of language-based segmentation and enhanced 3D perception capabilities. SAM 3 supports zero-shot segmentation across a wide range of prompts, including point, bounding box, and language-based prompts, allowing for more flexible and intuitive interactions with the model. In this empirical evaluation, we assess the performance of SAM 3 in robot-assisted surgery, benchmarking its zero-shot segmentation with point and bounding box prompts and exploring its effectiveness in dynamic video tracking, alongside its newly introduced language prompt segmentation. While language prompts show potential, their performance in the surgical domain is currently suboptimal, highlighting the need for further domain-specific training. Additionally, we investigate SAM 3D's depth reconstruction abilities, demonstrating its capacity to process surgical scene data and reconstruct 3D anatomical structures from 2D images. Through comprehensive testing on the MICCAI EndoVis 2017 and EndoVis 2018 benchmarks, SAM 3 shows clear improvements over SAM and SAM 2 in both image and video segmentation under spatial prompts, while the zero-shot evaluations of SAM 3D on SCARED, StereoMIS, and EndoNeRF indicate strong monocular depth estimation and realistic 3D instrument reconstruction, yet also reveal remaining limitations in complex, highly dynamic surgical scenes.
Endo3R: Unified Online Reconstruction from Dynamic Monocular Endoscopic Video
Apr 04, 2025



Reconstructing 3D scenes from monocular surgical videos can enhance surgeon's perception and therefore plays a vital role in various computer-assisted surgery tasks. However, achieving scale-consistent reconstruction remains an open challenge due to inherent issues in endoscopic videos, such as dynamic deformations and textureless surfaces. Despite recent advances, current methods either rely on calibration or instrument priors to estimate scale, or employ SfM-like multi-stage pipelines, leading to error accumulation and requiring offline optimization. In this paper, we present Endo3R, a unified 3D foundation model for online scale-consistent reconstruction from monocular surgical video, without any priors or extra optimization. Our model unifies the tasks by predicting globally aligned pointmaps, scale-consistent video depths, and camera parameters without any offline optimization. The core contribution of our method is expanding the capability of the recent pairwise reconstruction model to long-term incremental dynamic reconstruction by an uncertainty-aware dual memory mechanism. The mechanism maintains history tokens of both short-term dynamics and long-term spatial consistency. Notably, to tackle the highly dynamic nature of surgical scenes, we measure the uncertainty of tokens via Sampson distance and filter out tokens with high uncertainty. Regarding the scarcity of endoscopic datasets with ground-truth depth and camera poses, we further devise a self-supervised mechanism with a novel dynamics-aware flow loss. Abundant experiments on SCARED and Hamlyn datasets demonstrate our superior performance in zero-shot surgical video depth prediction and camera pose estimation with online efficiency. Project page: https://wrld.github.io/Endo3R/.
Low-Confidence Gold: Refining Low-Confidence Samples for Efficient Instruction Tuning
Feb 26, 2025



The effectiveness of instruction fine-tuning for Large Language Models is fundamentally constrained by the quality and efficiency of training datasets. This work introduces Low-Confidence Gold (LCG), a novel filtering framework that employs centroid-based clustering and confidence-guided selection for identifying valuable instruction pairs. Through a semi-supervised approach using a lightweight classifier trained on representative samples, LCG curates high-quality subsets while preserving data diversity. Experimental evaluation demonstrates that models fine-tuned on LCG-filtered subsets of 6K samples achieve superior performance compared to existing methods, with substantial improvements on MT-bench and consistent gains across comprehensive evaluation metrics. The framework's efficacy while maintaining model performance establishes a promising direction for efficient instruction tuning.
nnY-Net: Swin-NeXt with Cross-Attention for 3D Medical Images Segmentation
Jan 02, 2025This paper provides a novel 3D medical image segmentation model structure called nnY-Net. This name comes from the fact that our model adds a cross-attention module at the bottom of the U-net structure to form a Y structure. We integrate the advantages of the two latest SOTA models, MedNeXt and SwinUNETR, and use Swin Transformer as the encoder and ConvNeXt as the decoder to innovatively design the Swin-NeXt structure. Our model uses the lowest-level feature map of the encoder as Key and Value and uses patient features such as pathology and treatment information as Query to calculate the attention weights in a Cross Attention module. Moreover, we simplify some pre- and post-processing as well as data enhancement methods in 3D image segmentation based on the dynUnet and nnU-net frameworks. We integrate our proposed Swin-NeXt with Cross-Attention framework into this framework. Last, we construct a DiceFocalCELoss to improve the training efficiency for the uneven data convergence of voxel classification.
RenderWorld: World Model with Self-Supervised 3D Label
Sep 17, 2024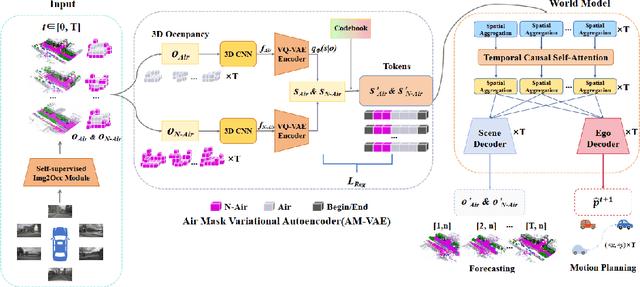
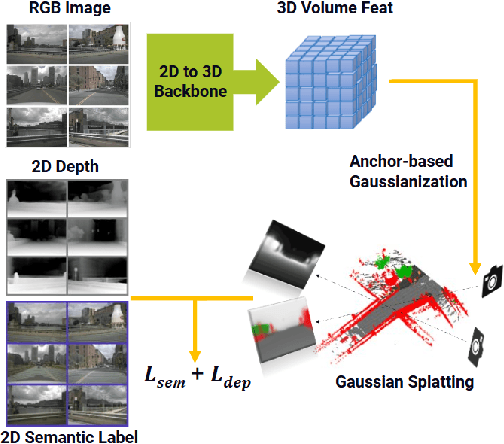
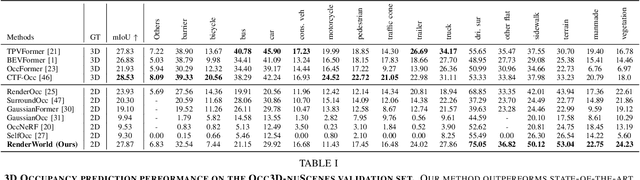

End-to-end autonomous driving with vision-only is not only more cost-effective compared to LiDAR-vision fusion but also more reliable than traditional methods. To achieve a economical and robust purely visual autonomous driving system, we propose RenderWorld, a vision-only end-to-end autonomous driving framework, which generates 3D occupancy labels using a self-supervised gaussian-based Img2Occ Module, then encodes the labels by AM-VAE, and uses world model for forecasting and planning. RenderWorld employs Gaussian Splatting to represent 3D scenes and render 2D images greatly improves segmentation accuracy and reduces GPU memory consumption compared with NeRF-based methods. By applying AM-VAE to encode air and non-air separately, RenderWorld achieves more fine-grained scene element representation, leading to state-of-the-art performance in both 4D occupancy forecasting and motion planning from autoregressive world model.
SAM 2 in Robotic Surgery: An Empirical Evaluation for Robustness and Generalization in Surgical Video Segmentation
Aug 08, 2024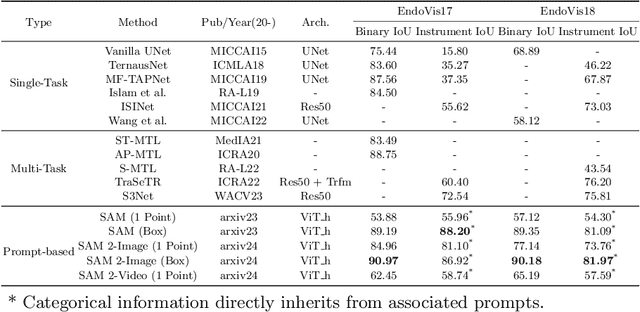



The recent Segment Anything Model (SAM) 2 has demonstrated remarkable foundational competence in semantic segmentation, with its memory mechanism and mask decoder further addressing challenges in video tracking and object occlusion, thereby achieving superior results in interactive segmentation for both images and videos. Building upon our previous empirical studies, we further explore the zero-shot segmentation performance of SAM 2 in robot-assisted surgery based on prompts, alongside its robustness against real-world corruption. For static images, we employ two forms of prompts: 1-point and bounding box, while for video sequences, the 1-point prompt is applied to the initial frame. Through extensive experimentation on the MICCAI EndoVis 2017 and EndoVis 2018 benchmarks, SAM 2, when utilizing bounding box prompts, outperforms state-of-the-art (SOTA) methods in comparative evaluations. The results with point prompts also exhibit a substantial enhancement over SAM's capabilities, nearing or even surpassing existing unprompted SOTA methodologies. Besides, SAM 2 demonstrates improved inference speed and less performance degradation against various image corruption. Although slightly unsatisfactory results remain in specific edges or regions, SAM 2's robust adaptability to 1-point prompts underscores its potential for downstream surgical tasks with limited prompt requirements.
Free-SurGS: SfM-Free 3D Gaussian Splatting for Surgical Scene Reconstruction
Jul 03, 2024



Real-time 3D reconstruction of surgical scenes plays a vital role in computer-assisted surgery, holding a promise to enhance surgeons' visibility. Recent advancements in 3D Gaussian Splatting (3DGS) have shown great potential for real-time novel view synthesis of general scenes, which relies on accurate poses and point clouds generated by Structure-from-Motion (SfM) for initialization. However, 3DGS with SfM fails to recover accurate camera poses and geometry in surgical scenes due to the challenges of minimal textures and photometric inconsistencies. To tackle this problem, in this paper, we propose the first SfM-free 3DGS-based method for surgical scene reconstruction by jointly optimizing the camera poses and scene representation. Based on the video continuity, the key of our method is to exploit the immediate optical flow priors to guide the projection flow derived from 3D Gaussians. Unlike most previous methods relying on photometric loss only, we formulate the pose estimation problem as minimizing the flow loss between the projection flow and optical flow. A consistency check is further introduced to filter the flow outliers by detecting the rigid and reliable points that satisfy the epipolar geometry. During 3D Gaussian optimization, we randomly sample frames to optimize the scene representations to grow the 3D Gaussian progressively. Experiments on the SCARED dataset demonstrate our superior performance over existing methods in novel view synthesis and pose estimation with high efficiency. Code is available at https://github.com/wrld/Free-SurGS.