 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocate before Answering: Answer Guided Question Localization for Video Question Answering
Paper and Code
Oct 05, 2022
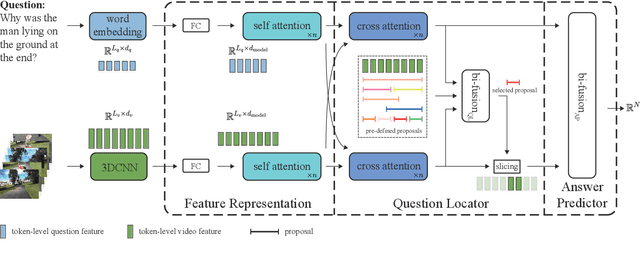
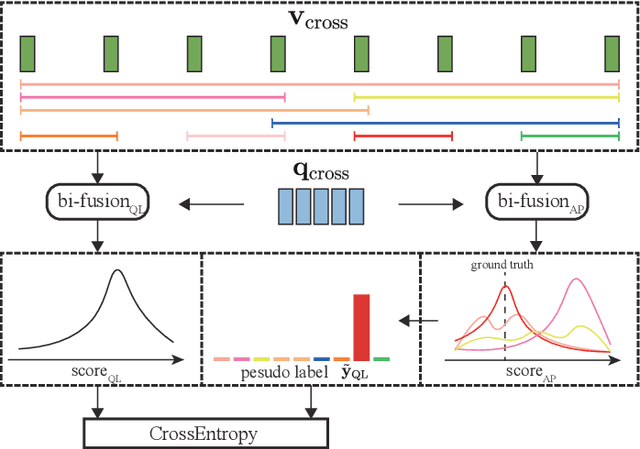
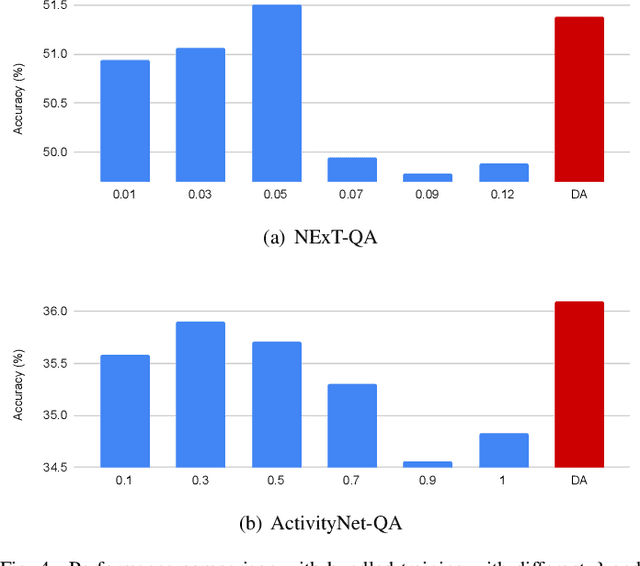
Video question answering (VideoQA) is an essential task in vision-language understanding, which has attracted numerous research attention recently. Nevertheless, existing works mostly achieve promising performances on short videos of duration within 15 seconds. For VideoQA on minute-level long-term videos, those methods are likely to fail because of lacking the ability to deal with noise and redundancy caused by scene changes and multiple actions in the video. Considering the fact that the question often remains concentrated in a short temporal range, we propose to first locate the question to a segment in the video and then infer the answer using the located segment only. Under this scheme, we propose "Locate before Answering" (LocAns), a novel approach that integrates a question locator and an answer predictor into an end-to-end model. During the training phase, the available answer label not only serves as the supervision signal of the answer predictor, but also is used to generate pseudo temporal labels for the question locator. Moreover, we design a decoupled alternative training strategy to update the two modules separately. In the experiments, LocAns achieves state-of-the-art performance on two modern long-term VideoQA datasets NExT-QA and ActivityNet-QA, and its qualitative examples show the reliable performance of the question localization.