 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVISO-Grasp: Vision-Language Informed Spatial Object-centric 6-DoF Active View Planning and Grasping in Clutter and Invisibility
Mar 16, 2025We propose VISO-Grasp, a novel vision-language-informed system designed to systematically address visibility constraints for grasping in severely occluded environments. By leveraging Foundation Models (FMs) for spatial reasoning and active view planning, our framework constructs and updates an instance-centric representation of spatial relationships, enhancing grasp success under challenging occlusions. Furthermore, this representation facilitates active Next-Best-View (NBV) planning and optimizes sequential grasping strategies when direct grasping is infeasible. Additionally, we introduce a multi-view uncertainty-driven grasp fusion mechanism that refines grasp confidence and directional uncertainty in real-time, ensuring robust and stable grasp execution. Extensive real-world experiments demonstrate that VISO-Grasp achieves a success rate of $87.5\%$ in target-oriented grasping with the fewest grasp attempts outperforming baselines. To the best of our knowledge, VISO-Grasp is the first unified framework integrating FMs into target-aware active view planning and 6-DoF grasping in environments with severe occlusions and entire invisibility constraints.
Understanding Particles From Video: Property Estimation of Granular Materials via Visuo-Haptic Learning
Dec 03, 2024



Granular materials (GMs) are ubiquitous in daily life. Understanding their properties is also important, especially in agriculture and industry. However, existing works require dedicated measurement equipment and also need large human efforts to handle a large number of particles. In this paper, we introduce a method for estimating the relative values of particle size and density from the video of the interaction with GMs. It is trained on a visuo-haptic learning framework inspired by a contact model, which reveals the strong correlation between GM properties and the visual-haptic data during the probe-dragging in the GMs. After training, the network can map the visual modality well to the haptic signal and implicitly characterize the relative distribution of particle properties in its latent embeddings, as interpreted in that contact model. Therefore, we can analyze GM properties using the trained encoder, and only visual information is needed without extra sensory modalities and human efforts for labeling. The presented GM property estimator has been extensively validated via comparison and ablation experiments. The generalization capability has also been evaluated and a real-world application on the beach is also demonstrated. Experiment videos are available at \url{https://sites.google.com/view/gmwork/vhlearning} .
Language-Augmented Symbolic Planner for Open-World Task Planning
Jul 13, 2024



Enabling robotic agents to perform complex long-horizon tasks has been a long-standing goal in robotics and artificial intelligence (AI). Despite the potential shown by large language models (LLMs), their planning capabilities remain limited to short-horizon tasks and they are unable to replace the symbolic planning approach. Symbolic planners, on the other hand, may encounter execution errors due to their common assumption of complete domain knowledge which is hard to manually prepare for an open-world setting. In this paper, we introduce a Language-Augmented Symbolic Planner (LASP) that integrates pre-trained LLMs to enable conventional symbolic planners to operate in an open-world environment where only incomplete knowledge of action preconditions, objects, and properties is initially available. In case of execution errors, LASP can utilize the LLM to diagnose the cause of the error based on the observation and interact with the environment to incrementally build up its knowledge base necessary for accomplishing the given tasks. Experiments demonstrate that LASP is proficient in solving planning problems in the open-world setting, performing well even in situations where there are multiple gaps in the knowledge.
Evaluating Explanation Methods for Vision-and-Language Navigation
Oct 10, 2023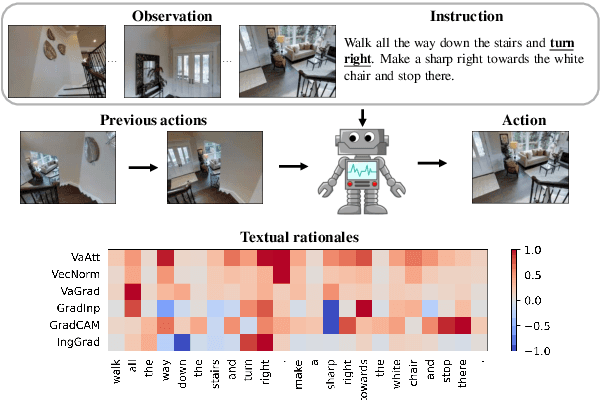
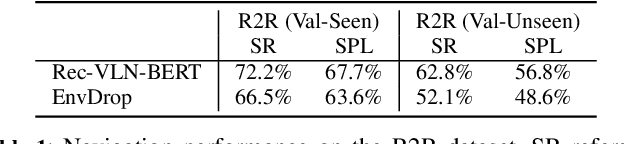
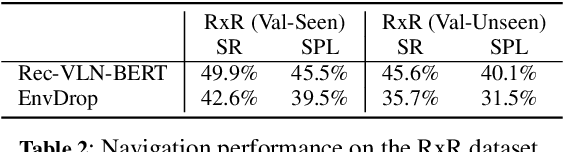
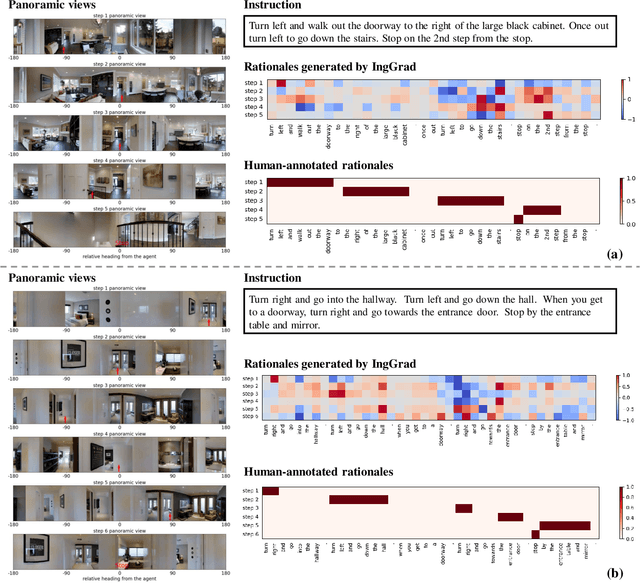
The ability to navigate robots with natural language instructions in an unknown environment is a crucial step for achieving embodied artificial intelligence (AI). With the improving performance of deep neural models proposed in the field of vision-and-language navigation (VLN), it is equally interesting to know what information the models utilize for their decision-making in the navigation tasks. To understand the inner workings of deep neural models, various explanation methods have been developed for promoting explainable AI (XAI). But they are mostly applied to deep neural models for image or text classification tasks and little work has been done in explaining deep neural models for VLN tasks. In this paper, we address these problems by building quantitative benchmarks to evaluate explanation methods for VLN models in terms of faithfulness. We propose a new erasure-based evaluation pipeline to measure the step-wise textual explanation in the sequential decision-making setting. We evaluate several explanation methods for two representative VLN models on two popular VLN datasets and reveal valuable findings through our experiments.
Semantic-aware Temporal Channel-wise Attention for Cardiac Function Assessment
Oct 09, 2023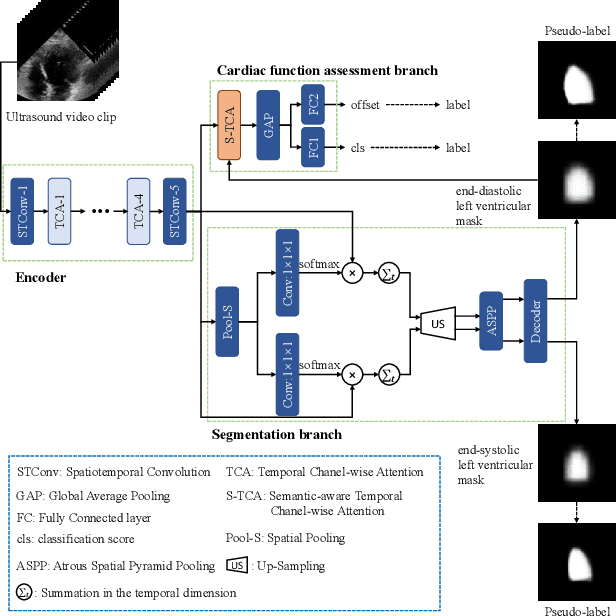
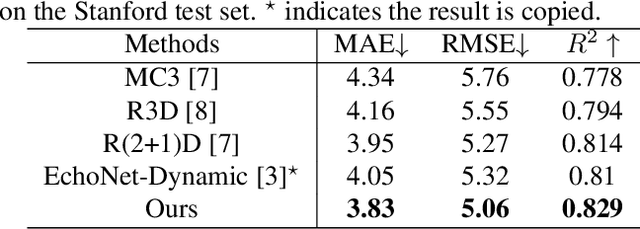
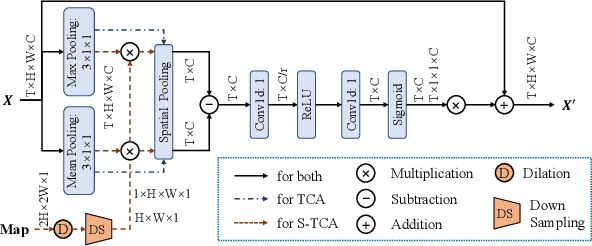
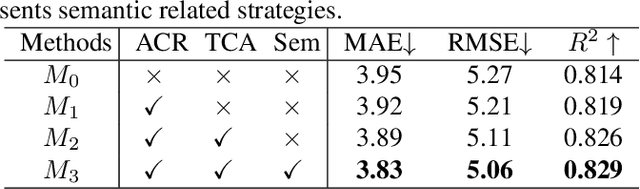
Cardiac function assessment aims at predicting left ventricular ejection fraction (LVEF) given an echocardiogram video, which requests models to focus on the changes in the left ventricle during the cardiac cycle. How to assess cardiac function accurately and automatically from an echocardiogram video is a valuable topic in intelligent assisted healthcare. Existing video-based methods do not pay much attention to the left ventricular region, nor the left ventricular changes caused by motion. In this work, we propose a semi-supervised auxiliary learning paradigm with a left ventricular segmentation task, which contributes to the representation learning for the left ventricular region. To better model the importance of motion information, we introduce a temporal channel-wise attention (TCA) module to excite those channels used to describe motion. Furthermore, we reform the TCA module with semantic perception by taking the segmentation map of the left ventricle as input to focus on the motion patterns of the left ventricle. Finally, to reduce the difficulty of direct LVEF regression, we utilize an anchor-based classification and regression method to predict LVEF. Our approach achieves state-of-the-art performance on the Stanford dataset with an improvement of 0.22 MAE, 0.26 RMSE, and 1.9% $R^2$.
ModLaNets: Learning Generalisable Dynamics via Modularity and Physical Inductive Bias
Jul 04, 2022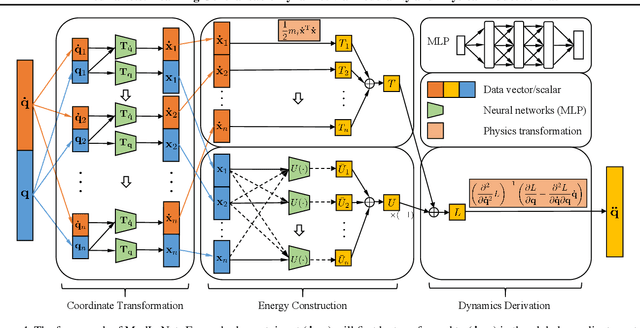
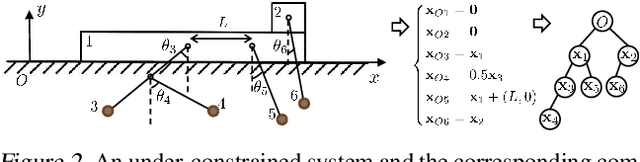
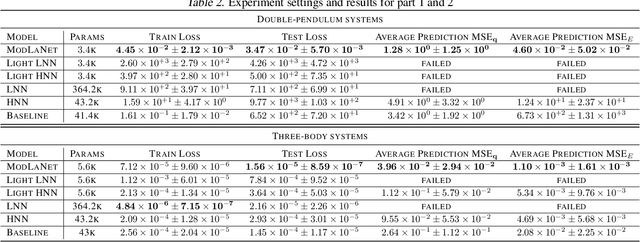
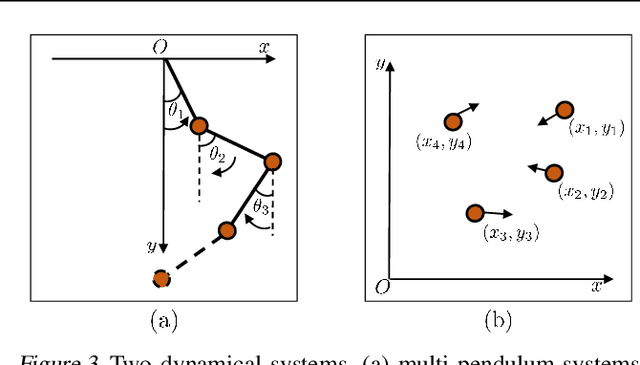
Deep learning models are able to approximate one specific dynamical system but struggle at learning generalisable dynamics, where dynamical systems obey the same laws of physics but contain different numbers of elements (e.g., double- and triple-pendulum systems). To relieve this issue, we proposed the Modular Lagrangian Network (ModLaNet), a structural neural network framework with modularity and physical inductive bias. This framework models the energy of each element using modularity and then construct the target dynamical system via Lagrangian mechanics. Modularity is beneficial for reusing trained networks and reducing the scale of networks and datasets. As a result, our framework can learn from the dynamics of simpler systems and extend to more complex ones, which is not feasible using other relevant physics-informed neural networks. We examine our framework for modelling double-pendulum or three-body systems with small training datasets, where our models achieve the best data efficiency and accuracy performance compared with counterparts. We also reorganise our models as extensions to model multi-pendulum and multi-body systems, demonstrating the intriguing reusable feature of our framework.
Less is More: Adaptive Curriculum Learning for Thyroid Nodule Diagnosis
Jul 02, 2022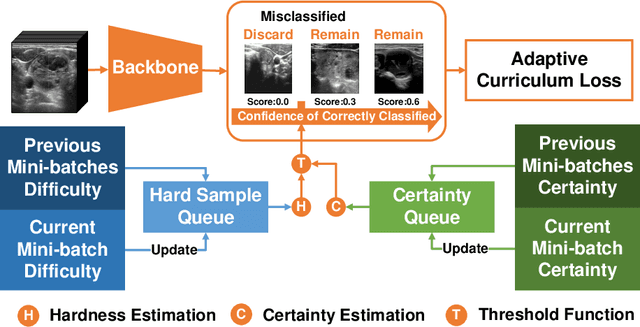
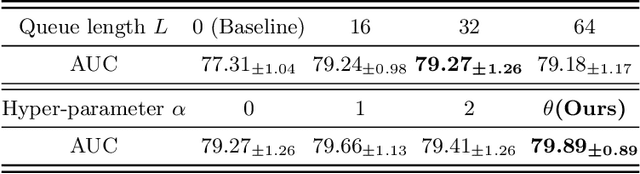
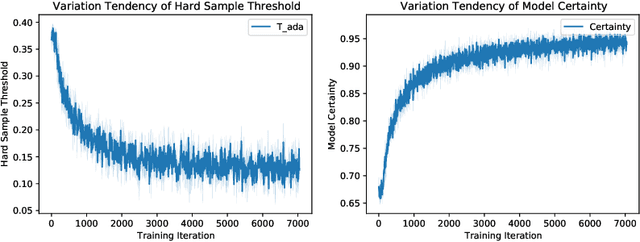
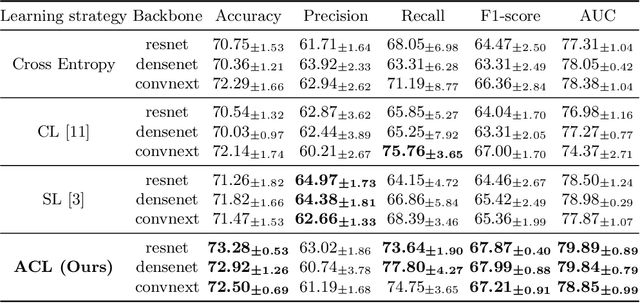
Thyroid nodule classification aims at determining whether the nodule is benign or malignant based on a given ultrasound image. However, the label obtained by the cytological biopsy which is the golden standard in clinical medicine is not always consistent with the ultrasound imaging TI-RADS criteria. The information difference between the two causes the existing deep learning-based classification methods to be indecisive. To solve the Inconsistent Label problem, we propose an Adaptive Curriculum Learning (ACL) framework, which adaptively discovers and discards the samples with inconsistent labels. Specifically, ACL takes both hard sample and model certainty into account, and could accurately determine the threshold to distinguish the samples with Inconsistent Label. Moreover, we contribute TNCD: a Thyroid Nodule Classification Dataset to facilitate future related research on the thyroid nodules. Extensive experimental results on TNCD based on three different backbone networks not only demonstrate the superiority of our method but also prove that the less-is-more principle which strategically discards the samples with Inconsistent Label could yield performance gains. Source code and data are available at https://github.com/chenghui-666/ACL/.
Depthwise Non-local Module for Fast Salient Object Detection Using a Single Thread
Jan 22, 2020
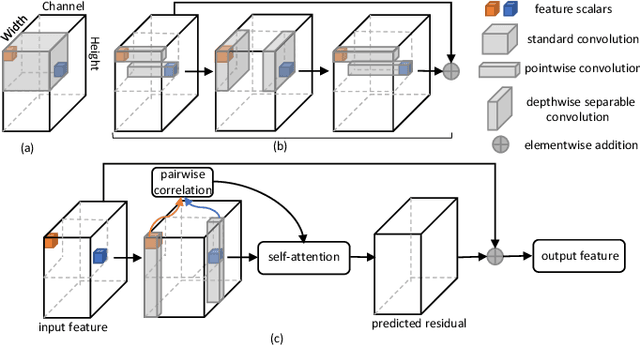
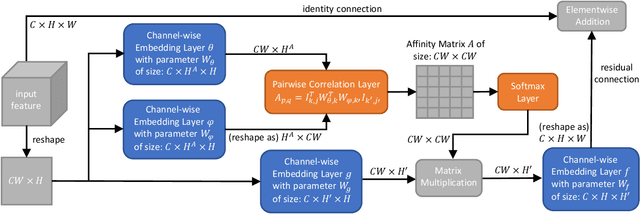
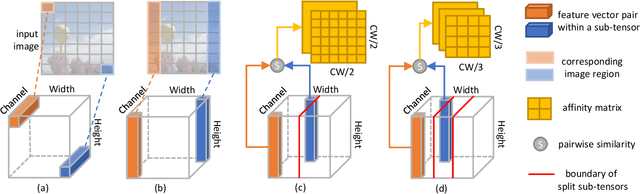
Recently deep convolutional neural networks have achieved significant success in salient object detection. However, existing state-of-the-art methods require high-end GPUs to achieve real-time performance, which makes them hard to adapt to low-cost or portable devices. Although generic network architectures have been proposed to speed up inference on mobile devices, they are tailored to the task of image classification or semantic segmentation, and struggle to capture intra-channel and inter-channel correlations that are essential for contrast modeling in salient object detection. Motivated by the above observations, we design a new deep learning algorithm for fast salient object detection. The proposed algorithm for the first time achieves competitive accuracy and high inference efficiency simultaneously with a single CPU thread. Specifically, we propose a novel depthwise non-local moudule (DNL), which implicitly models contrast via harvesting intra-channel and inter-channel correlations in a self-attention manner. In addition, we introduce a depthwise non-local network architecture that incorporates both depthwise non-local modules and inverted residual blocks. Experimental results show that our proposed network attains very competitive accuracy on a wide range of salient object detection datasets while achieving state-of-the-art efficiency among all existing deep learning based algorithms.
Motion Guided Attention for Video Salient Object Detection
Oct 03, 2019
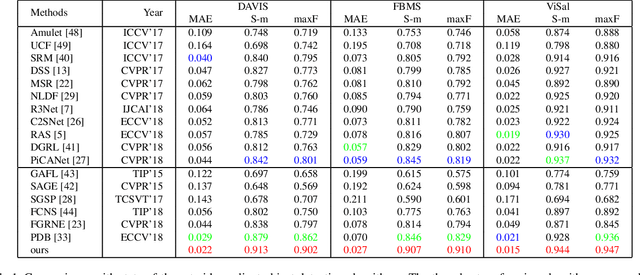
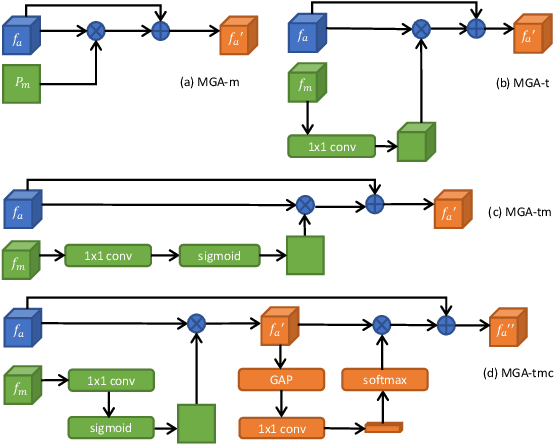
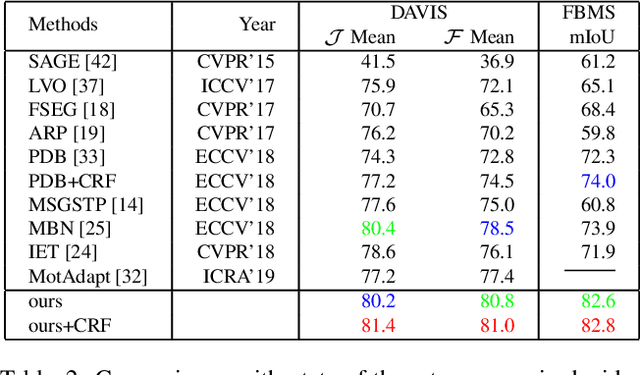
Video salient object detection aims at discovering the most visually distinctive objects in a video. How to effectively take object motion into consideration during video salient object detection is a critical issue. Existing state-of-the-art methods either do not explicitly model and harvest motion cues or ignore spatial contexts within optical flow images. In this paper, we develop a multi-task motion guided video salient object detection network, which learns to accomplish two sub-tasks using two sub-networks, one sub-network for salient object detection in still images and the other for motion saliency detection in optical flow images. We further introduce a series of novel motion guided attention modules, which utilize the motion saliency sub-network to attend and enhance the sub-network for still images. These two sub-networks learn to adapt to each other by end-to-end training. Experimental results demonstrate that the proposed method significantly outperforms existing state-of-the-art algorithms on a wide range of benchmarks. We hope our simple and effective approach will serve as a solid baseline and help ease future research in video salient object detection. Code and models will be made available.