 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMotion Guided Attention for Video Salient Object Detection
Paper and Code

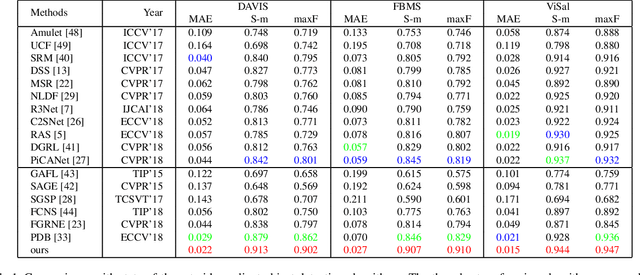
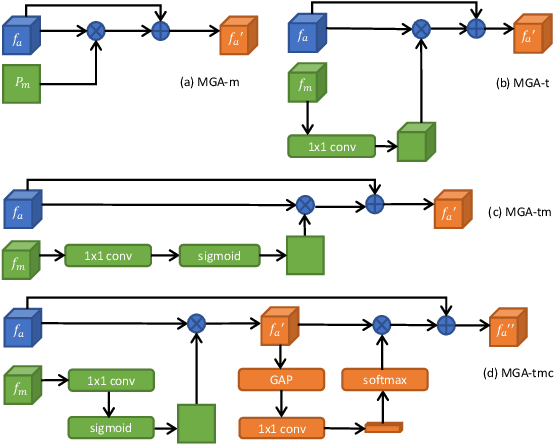
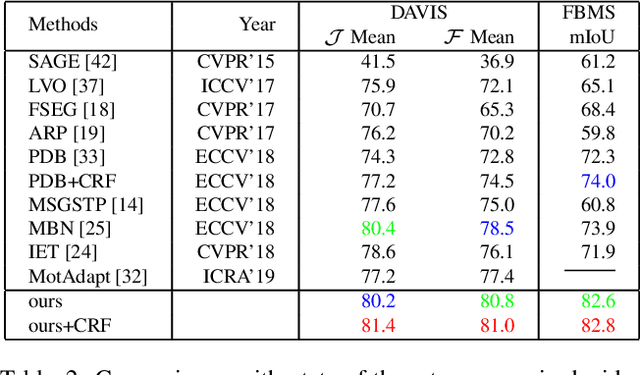
Video salient object detection aims at discovering the most visually distinctive objects in a video. How to effectively take object motion into consideration during video salient object detection is a critical issue. Existing state-of-the-art methods either do not explicitly model and harvest motion cues or ignore spatial contexts within optical flow images. In this paper, we develop a multi-task motion guided video salient object detection network, which learns to accomplish two sub-tasks using two sub-networks, one sub-network for salient object detection in still images and the other for motion saliency detection in optical flow images. We further introduce a series of novel motion guided attention modules, which utilize the motion saliency sub-network to attend and enhance the sub-network for still images. These two sub-networks learn to adapt to each other by end-to-end training. Experimental results demonstrate that the proposed method significantly outperforms existing state-of-the-art algorithms on a wide range of benchmarks. We hope our simple and effective approach will serve as a solid baseline and help ease future research in video salient object detection. Code and models will be made available.