 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGauSS-MI: Gaussian Splatting Shannon Mutual Information for Active 3D Reconstruction
Apr 29, 2025



This research tackles the challenge of real-time active view selection and uncertainty quantification on visual quality for active 3D reconstruction. Visual quality is a critical aspect of 3D reconstruction. Recent advancements such as Neural Radiance Fields (NeRF) and 3D Gaussian Splatting (3DGS) have notably enhanced the image rendering quality of reconstruction models. Nonetheless, the efficient and effective acquisition of input images for reconstruction-specifically, the selection of the most informative viewpoint-remains an open challenge, which is crucial for active reconstruction. Existing studies have primarily focused on evaluating geometric completeness and exploring unobserved or unknown regions, without direct evaluation of the visual uncertainty within the reconstruction model. To address this gap, this paper introduces a probabilistic model that quantifies visual uncertainty for each Gaussian. Leveraging Shannon Mutual Information, we formulate a criterion, Gaussian Splatting Shannon Mutual Information (GauSS-MI), for real-time assessment of visual mutual information from novel viewpoints, facilitating the selection of next best view. GauSS-MI is implemented within an active reconstruction system integrated with a view and motion planner. Extensive experiments across various simulated and real-world scenes showcase the superior visual quality and reconstruction efficiency performance of the proposed system.
Signage-Aware Exploration in Open World using Venue Maps
Oct 14, 2024
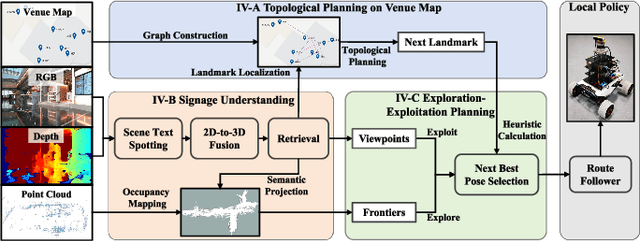
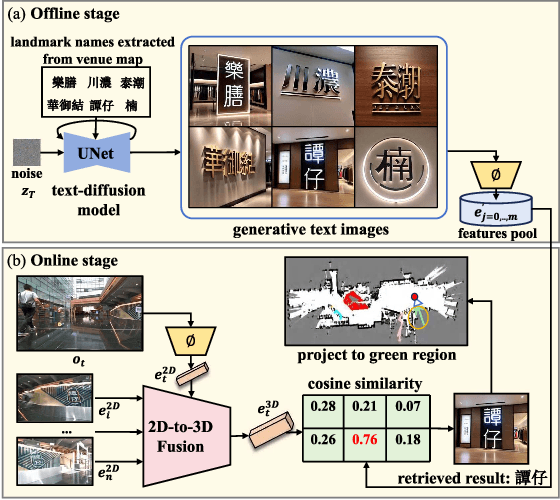
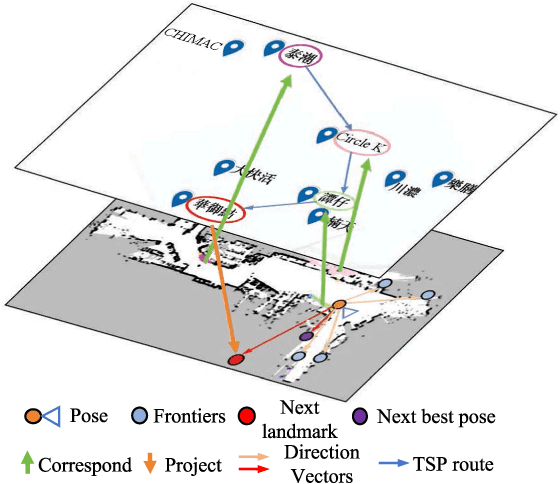
Current exploration methods struggle to search for shops in unknown open-world environments due to a lack of prior knowledge and text recognition capabilities. Venue maps offer valuable information that can aid exploration planning by correlating scene signage with map data. However, the arbitrary shapes and styles of the text on signage, along with multi-view inconsistencies, pose significant challenges for accurate recognition by robots. Additionally, the discrepancies between real-world environments and venue maps hinder the incorporation of text information into planners. This paper introduces a novel signage-aware exploration system to address these challenges, enabling the robot to utilize venue maps effectively. We propose a signage understanding method that accurately detects and recognizes the text on signage using a diffusion-based text instance retrieval method combined with a 2D-to-3D semantic fusion strategy. Furthermore, we design a venue map-guided exploration-exploitation planner that balances exploration in unknown regions using a directional heuristic derived from venue maps with exploitation to get close and adjust orientation for better recognition. Experiments in large-scale shopping malls demonstrate our method's superior signage recognition accuracy and coverage efficiency, outperforming state-of-the-art scene text spotting methods and traditional exploration methods.
SMAT: A Self-Reinforcing Framework for Simultaneous Mapping and Tracking in Unbounded Urban Environments
Apr 27, 2023With the increasing prevalence of robots in daily life, it is crucial to enable robots to construct a reliable map online to navigate in unbounded and changing environments. Although existing methods can individually achieve the goals of spatial mapping and dynamic object detection and tracking, limited research has been conducted on an effective combination of these two important abilities. The proposed framework, SMAT (Simultaneous Mapping and Tracking), integrates the front-end dynamic object detection and tracking module with the back-end static mapping module using a self-reinforcing mechanism, which promotes mutual improvement of mapping and tracking performance. The conducted experiments demonstrate the framework's effectiveness in real-world applications, achieving successful long-range navigation and mapping in multiple urban environments using only one LiDAR, a CPU-only onboard computer, and a consumer-level GPS receiver.
A Generalized Continuous Collision Detection Framework of Polynomial Trajectory for Mobile Robots in Cluttered Environments
Jun 27, 2022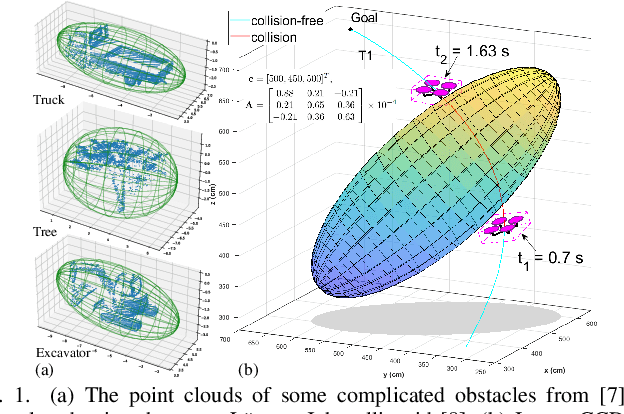
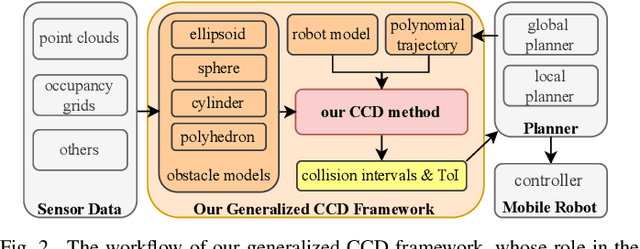
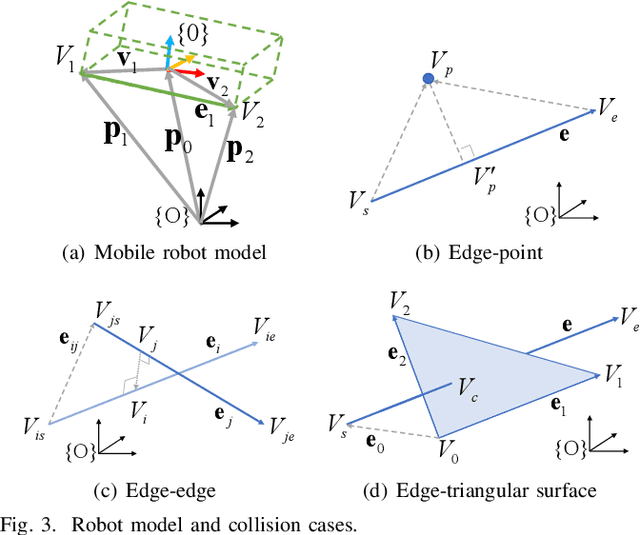
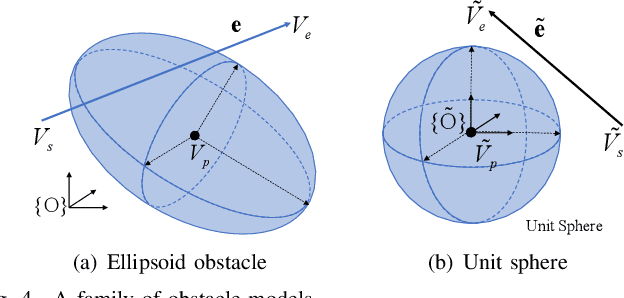
In this paper, we introduce a generalized continuous collision detection (CCD) framework for the mobile robot along the polynomial trajectory in cluttered environments including various static obstacle models. Specifically, we find that the collision conditions between robots and obstacles could be transformed into a set of polynomial inequalities, whose roots can be efficiently solved by the proposed solver. In addition, we test different types of mobile robots with various kinematic and dynamic constraints in our generalized CCD framework and validate that it allows the provable collision checking and can compute the exact time of impact. Furthermore, we combine our architecture with the path planner in the navigation system. Benefiting from our CCD method, the mobile robot is able to work safely in some challenging scenarios.
Autofocus for Event Cameras
Mar 23, 2022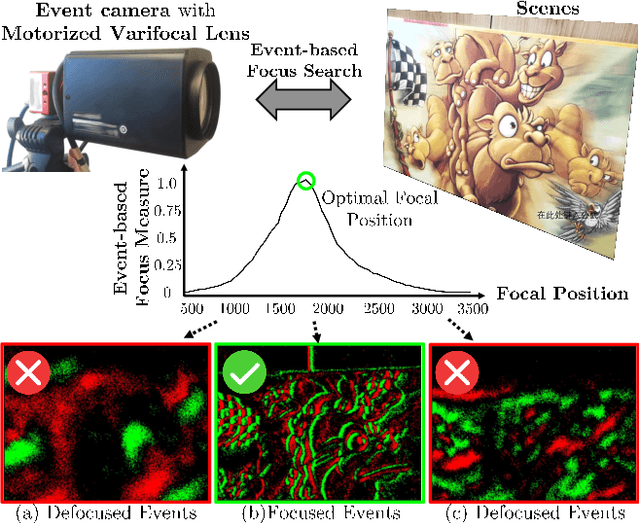
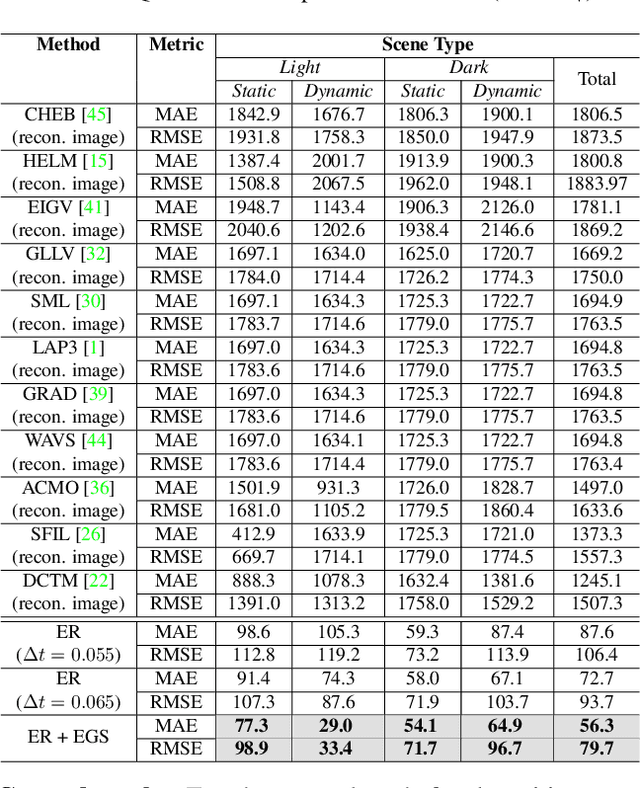

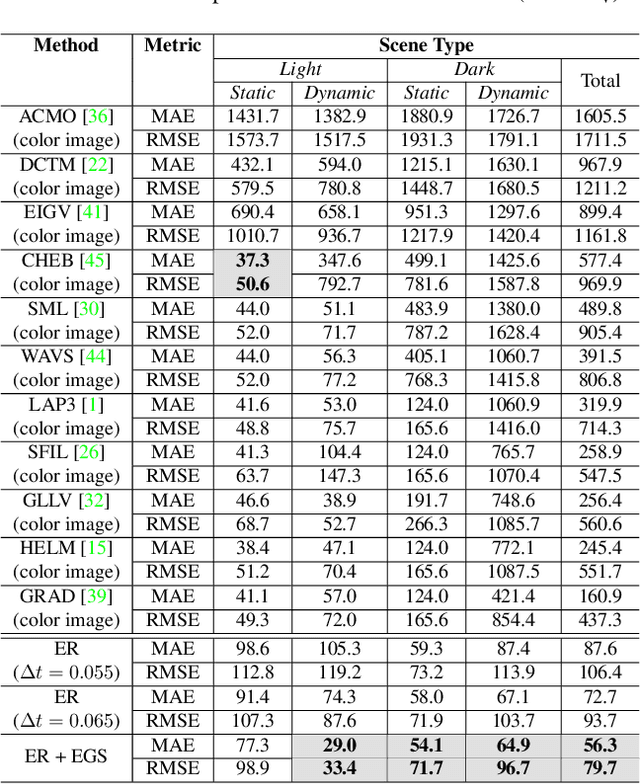
Focus control (FC) is crucial for cameras to capture sharp images in challenging real-world scenarios. The autofocus (AF) facilitates the FC by automatically adjusting the focus settings. However, due to the lack of effective AF methods for the recently introduced event cameras, their FC still relies on naive AF like manual focus adjustments, leading to poor adaptation in challenging real-world conditions. In particular, the inherent differences between event and frame data in terms of sensing modality, noise, temporal resolutions, etc., bring many challenges in designing an effective AF method for event cameras. To address these challenges, we develop a novel event-based autofocus framework consisting of an event-specific focus measure called event rate (ER) and a robust search strategy called event-based golden search (EGS). To verify the performance of our method, we have collected an event-based autofocus dataset (EAD) containing well-synchronized frames, events, and focal positions in a wide variety of challenging scenes with severe lighting and motion conditions. The experiments on this dataset and additional real-world scenarios demonstrated the superiority of our method over state-of-the-art approaches in terms of efficiency and accuracy.
Keyfilter-Aware Real-Time UAV Object Tracking
Mar 11, 2020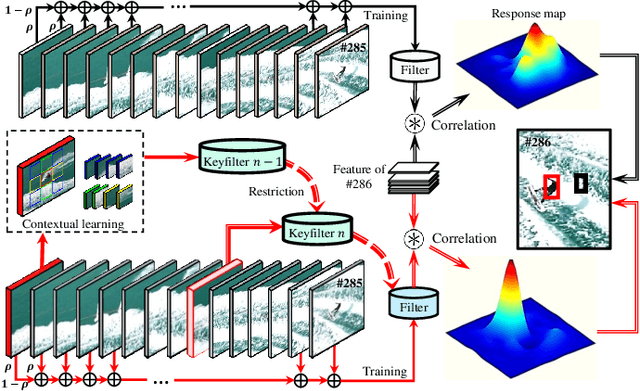
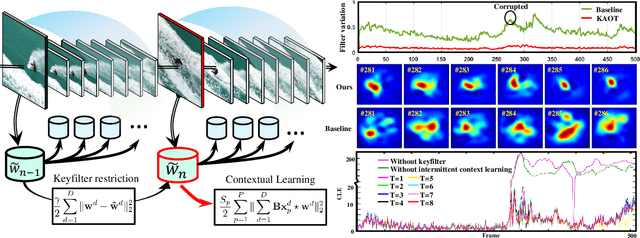
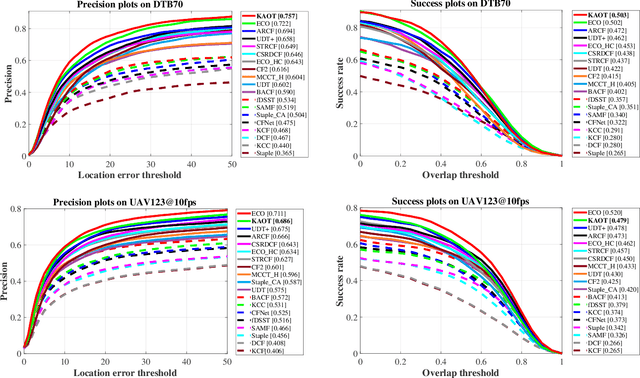
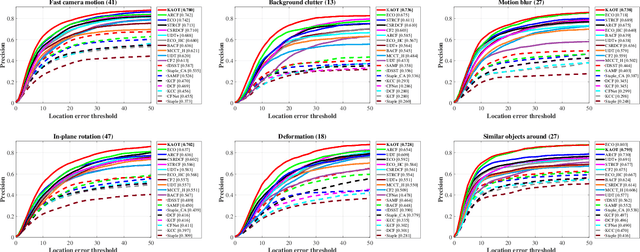
Correlation filter-based tracking has been widely applied in unmanned aerial vehicle (UAV) with high efficiency. However, it has two imperfections, i.e., boundary effect and filter corruption. Several methods enlarging the search area can mitigate boundary effect, yet introducing undesired background distraction. Existing frame-by-frame context learning strategies for repressing background distraction nevertheless lower the tracking speed. Inspired by keyframe-based simultaneous localization and mapping, keyfilter is proposed in visual tracking for the first time, in order to handle the above issues efficiently and effectively. Keyfilters generated by periodically selected keyframes learn the context intermittently and are used to restrain the learning of filters, so that 1) context awareness can be transmitted to all the filters via keyfilter restriction, and 2) filter corruption can be repressed. Compared to the state-of-the-art results, our tracker performs better on two challenging benchmarks, with enough speed for UAV real-time applications.