 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePalette of Language Models: A Solver for Controlled Text Generation
Mar 14, 2025



Recent advancements in large language models have revolutionized text generation with their remarkable capabilities. These models can produce controlled texts that closely adhere to specific requirements when prompted appropriately. However, designing an optimal prompt to control multiple attributes simultaneously can be challenging. A common approach is to linearly combine single-attribute models, but this strategy often overlooks attribute overlaps and can lead to conflicts. Therefore, we propose a novel combination strategy inspired by the Law of Total Probability and Conditional Mutual Information Minimization on generative language models. This method has been adapted for single-attribute control scenario and is termed the Palette of Language Models due to its theoretical linkage between attribute strength and generation style, akin to blending colors on an artist's palette. Moreover, positive correlation and attribute enhancement are advanced as theoretical properties to guide a rational combination strategy design. We conduct experiments on both single control and multiple control settings, and achieve surpassing results.
An Auto-tuning Framework for Autonomous Vehicles
Aug 14, 2018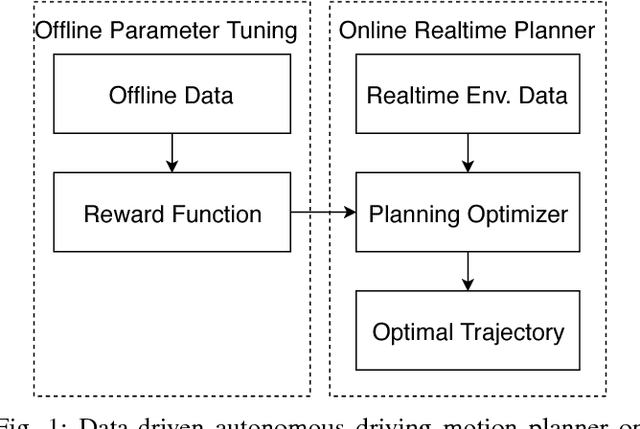
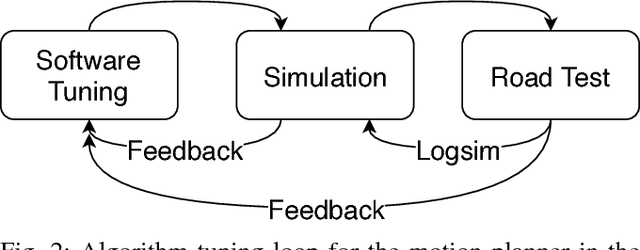
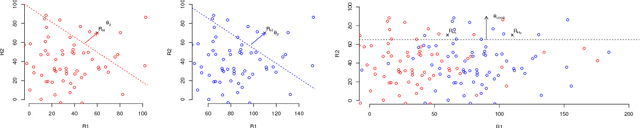
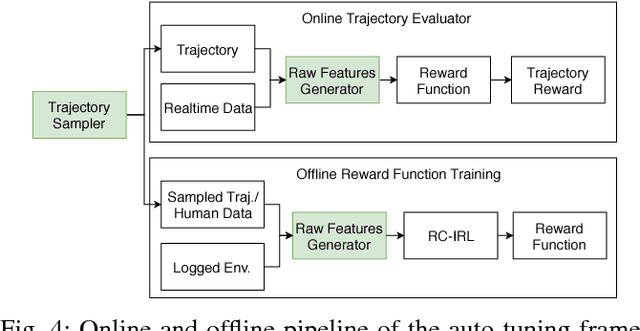
Many autonomous driving motion planners generate trajectories by optimizing a reward/cost functional. Designing and tuning a high-performance reward/cost functional for Level-4 autonomous driving vehicles with exposure to different driving conditions is challenging. Traditionally, reward/cost functional tuning involves substantial human effort and time spent on both simulations and road tests. As the scenario becomes more complicated, tuning to improve the motion planner performance becomes increasingly difficult. To systematically solve this issue, we develop a data-driven auto-tuning framework based on the Apollo autonomous driving framework. The framework includes a novel rank-based conditional inverse reinforcement learning algorithm, an offline training strategy and an automatic method of collecting and labeling data. Our auto-tuning framework has the following advantages that make it suitable for tuning an autonomous driving motion planner. First, compared to that of most inverse reinforcement learning algorithms, our algorithm training is efficient and capable of being applied to different scenarios. Second, the offline training strategy offers a safe way to adjust the parameters before public road testing. Third, the expert driving data and information about the surrounding environment are collected and automatically labeled, which considerably reduces the manual effort. Finally, the motion planner tuned by the framework is examined via both simulation and public road testing and is shown to achieve good performance.