 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCharacterizing the Predictive Impact of Modalities with Supervised Latent-Variable Modeling
Feb 19, 2026Despite the recent success of Multimodal Large Language Models (MLLMs), existing approaches predominantly assume the availability of multiple modalities during training and inference. In practice, multimodal data is often incomplete because modalities may be missing, collected asynchronously, or available only for a subset of examples. In this work, we propose PRIMO, a supervised latent-variable imputation model that quantifies the predictive impact of any missing modality within the multimodal learning setting. PRIMO enables the use of all available training examples, whether modalities are complete or partial. Specifically, it models the missing modality through a latent variable that captures its relationship with the observed modality in the context of prediction. During inference, we draw many samples from the learned distribution over the missing modality to both obtain the marginal predictive distribution (for the purpose of prediction) and analyze the impact of the missing modalities on the prediction for each instance. We evaluate PRIMO on a synthetic XOR dataset, Audio-Vision MNIST, and MIMIC-III for mortality and ICD-9 prediction. Across all datasets, PRIMO obtains performance comparable to unimodal baselines when a modality is fully missing and to multimodal baselines when all modalities are available. PRIMO quantifies the predictive impact of a modality at the instance level using a variance-based metric computed from predictions across latent completions. We visually demonstrate how varying completions of the missing modality result in a set of plausible labels.
HIST-AID: Leveraging Historical Patient Reports for Enhanced Multi-Modal Automatic Diagnosis
Nov 16, 2024Chest X-ray imaging is a widely accessible and non-invasive diagnostic tool for detecting thoracic abnormalities. While numerous AI models assist radiologists in interpreting these images, most overlook patients' historical data. To bridge this gap, we introduce Temporal MIMIC dataset, which integrates five years of patient history, including radiographic scans and reports from MIMIC-CXR and MIMIC-IV, encompassing 12,221 patients and thirteen pathologies. Building on this, we present HIST-AID, a framework that enhances automatic diagnostic accuracy using historical reports. HIST-AID emulates the radiologist's comprehensive approach, leveraging historical data to improve diagnostic accuracy. Our experiments demonstrate significant improvements, with AUROC increasing by 6.56% and AUPRC by 9.51% compared to models that rely solely on radiographic scans. These gains were consistently observed across diverse demographic groups, including variations in gender, age, and racial categories. We show that while recent data boost performance, older data may reduce accuracy due to changes in patient conditions. Our work paves the potential of incorporating historical data for more reliable automatic diagnosis, providing critical support for clinical decision-making.
A Framework for Multi-modal Learning: Jointly Modeling Inter- & Intra-Modality Dependencies
May 27, 2024



Supervised multi-modal learning involves mapping multiple modalities to a target label. Previous studies in this field have concentrated on capturing in isolation either the inter-modality dependencies (the relationships between different modalities and the label) or the intra-modality dependencies (the relationships within a single modality and the label). We argue that these conventional approaches that rely solely on either inter- or intra-modality dependencies may not be optimal in general. We view the multi-modal learning problem from the lens of generative models where we consider the target as a source of multiple modalities and the interaction between them. Towards that end, we propose inter- & intra-modality modeling (I2M2) framework, which captures and integrates both the inter- and intra-modality dependencies, leading to more accurate predictions. We evaluate our approach using real-world healthcare and vision-and-language datasets with state-of-the-art models, demonstrating superior performance over traditional methods focusing only on one type of modality dependency.
On Sensitivity and Robustness of Normalization Schemes to Input Distribution Shifts in Automatic MR Image Diagnosis
Jun 23, 2023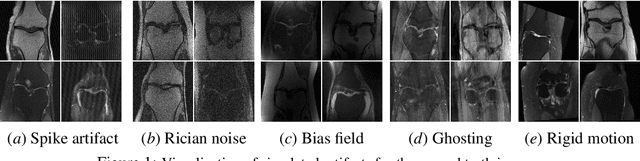
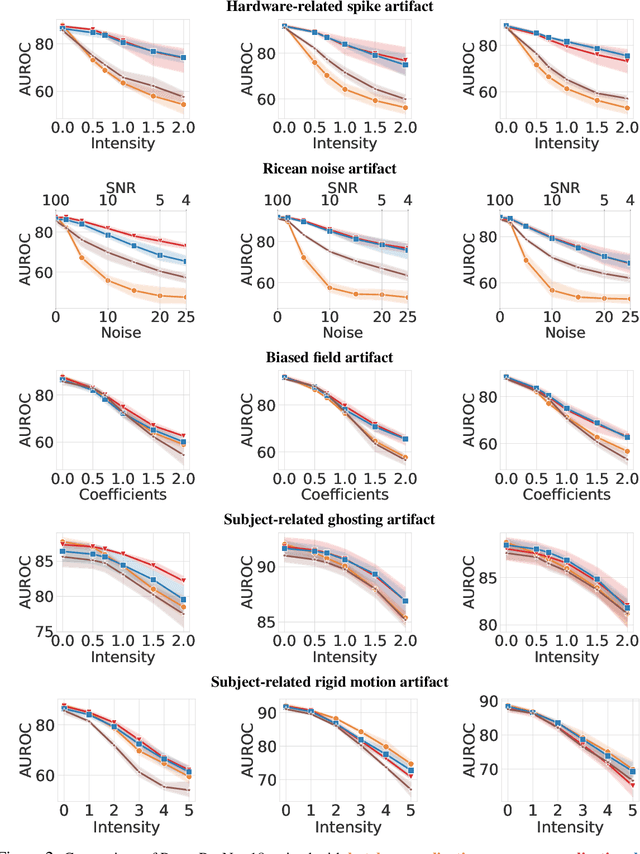
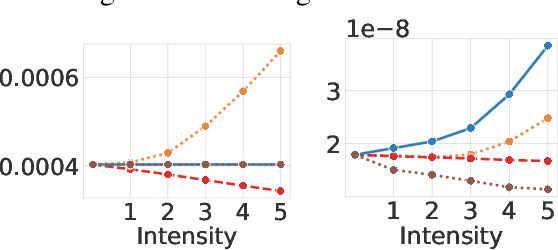
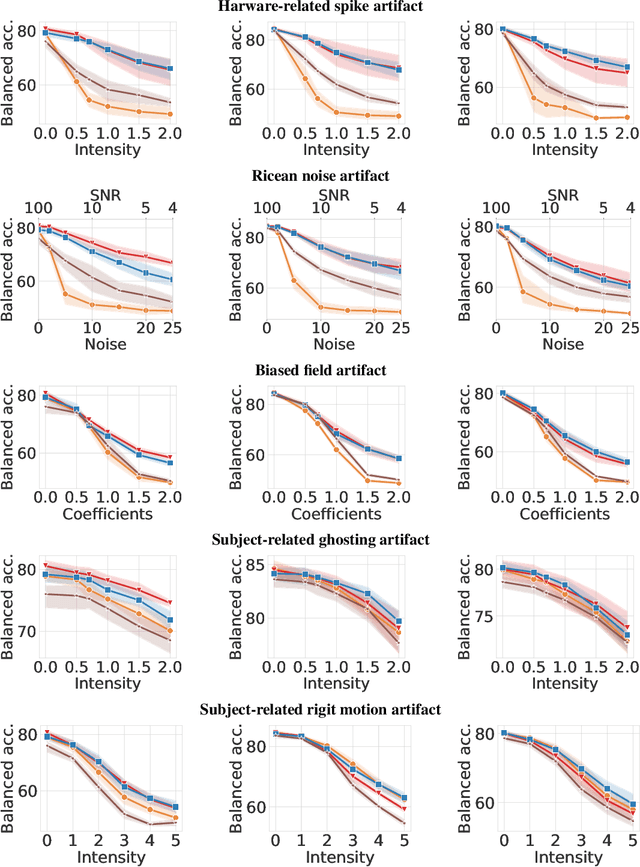
Magnetic Resonance Imaging (MRI) is considered the gold standard of medical imaging because of the excellent soft-tissue contrast exhibited in the images reconstructed by the MRI pipeline, which in-turn enables the human radiologist to discern many pathologies easily. More recently, Deep Learning (DL) models have also achieved state-of-the-art performance in diagnosing multiple diseases using these reconstructed images as input. However, the image reconstruction process within the MRI pipeline, which requires the use of complex hardware and adjustment of a large number of scanner parameters, is highly susceptible to noise of various forms, resulting in arbitrary artifacts within the images. Furthermore, the noise distribution is not stationary and varies within a machine, across machines, and patients, leading to varying artifacts within the images. Unfortunately, DL models are quite sensitive to these varying artifacts as it leads to changes in the input data distribution between the training and testing phases. The lack of robustness of these models against varying artifacts impedes their use in medical applications where safety is critical. In this work, we focus on improving the generalization performance of these models in the presence of multiple varying artifacts that manifest due to the complexity of the MR data acquisition. In our experiments, we observe that Batch Normalization, a widely used technique during the training of DL models for medical image analysis, is a significant cause of performance degradation in these changing environments. As a solution, we propose to use other normalization techniques, such as Group Normalization and Layer Normalization (LN), to inject robustness into model performance against varying image artifacts. Through a systematic set of experiments, we show that GN and LN provide better accuracy for various MR artifacts and distribution shifts.
Heterogeneous Continual Learning
Jun 14, 2023



We propose a novel framework and a solution to tackle the continual learning (CL) problem with changing network architectures. Most CL methods focus on adapting a single architecture to a new task/class by modifying its weights. However, with rapid progress in architecture design, the problem of adapting existing solutions to novel architectures becomes relevant. To address this limitation, we propose Heterogeneous Continual Learning (HCL), where a wide range of evolving network architectures emerge continually together with novel data/tasks. As a solution, we build on top of the distillation family of techniques and modify it to a new setting where a weaker model takes the role of a teacher; meanwhile, a new stronger architecture acts as a student. Furthermore, we consider a setup of limited access to previous data and propose Quick Deep Inversion (QDI) to recover prior task visual features to support knowledge transfer. QDI significantly reduces computational costs compared to previous solutions and improves overall performance. In summary, we propose a new setup for CL with a modified knowledge distillation paradigm and design a quick data inversion method to enhance distillation. Our evaluation of various benchmarks shows a significant improvement on accuracy in comparison to state-of-the-art methods over various networks architectures.
Improving Representational Continuity via Continued Pretraining
Feb 26, 2023



We consider the continual representation learning setting: sequentially pretrain a model $M'$ on tasks $T_1, \ldots, T_T$, and then adapt $M'$ on a small amount of data from each task $T_i$ to check if it has forgotten information from old tasks. Under a kNN adaptation protocol, prior work shows that continual learning methods improve forgetting over naive training (SGD). In reality, practitioners do not use kNN classifiers -- they use the adaptation method that works best (e.g., fine-tuning) -- here, we find that strong continual learning baselines do worse than naive training. Interestingly, we find that a method from the transfer learning community (LP-FT) outperforms naive training and the other continual learning methods. Even with standard kNN evaluation protocols, LP-FT performs comparably with strong continual learning methods (while being simpler and requiring less memory) on three standard benchmarks: sequential CIFAR-10, CIFAR-100, and TinyImageNet. LP-FT also reduces forgetting in a real world satellite remote sensing dataset (FMoW), and a variant of LP-FT gets state-of-the-art accuracies on an NLP continual learning benchmark.
What Do NLP Researchers Believe? Results of the NLP Community Metasurvey
Aug 26, 2022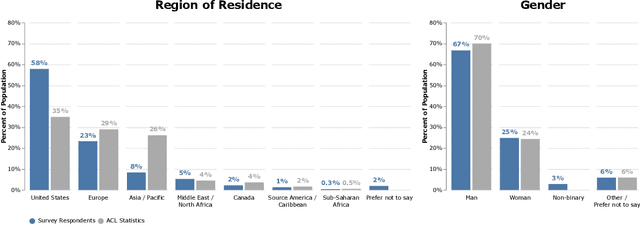

We present the results of the NLP Community Metasurvey. Run from May to June 2022, the survey elicited opinions on controversial issues, including industry influence in the field, concerns about AGI, and ethics. Our results put concrete numbers to several controversies: For example, respondents are split almost exactly in half on questions about the importance of artificial general intelligence, whether language models understand language, and the necessity of linguistic structure and inductive bias for solving NLP problems. In addition, the survey posed meta-questions, asking respondents to predict the distribution of survey responses. This allows us not only to gain insight on the spectrum of beliefs held by NLP researchers, but also to uncover false sociological beliefs where the community's predictions don't match reality. We find such mismatches on a wide range of issues. Among other results, the community greatly overestimates its own belief in the usefulness of benchmarks and the potential for scaling to solve real-world problems, while underestimating its own belief in the importance of linguistic structure, inductive bias, and interdisciplinary science.
Rethinking the Representational Continuity: Towards Unsupervised Continual Learning
Oct 15, 2021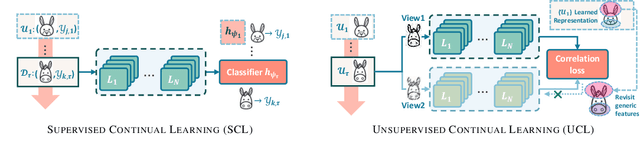
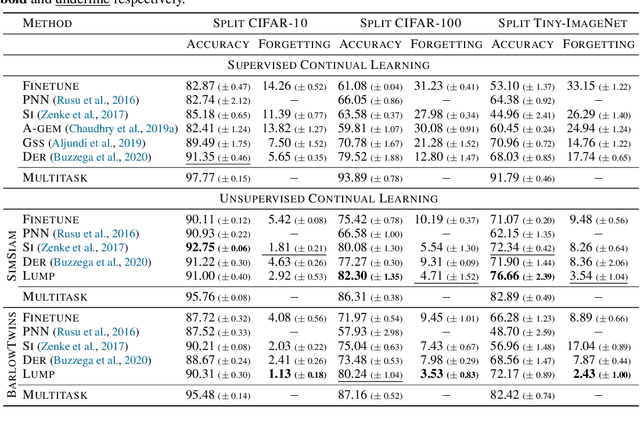
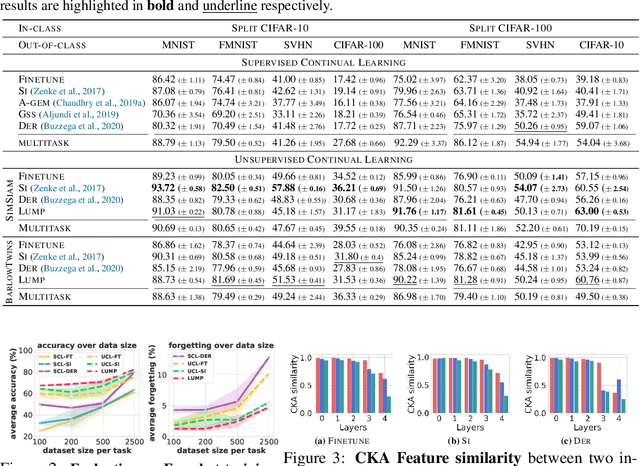
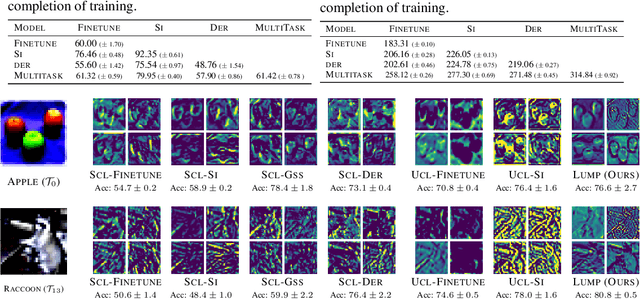
Continual learning (CL) aims to learn a sequence of tasks without forgetting the previously acquired knowledge. However, recent advances in continual learning are restricted to supervised continual learning (SCL) scenarios. Consequently, they are not scalable to real-world applications where the data distribution is often biased and unannotated. In this work, we focus on unsupervised continual learning (UCL), where we learn the feature representations on an unlabelled sequence of tasks and show that reliance on annotated data is not necessary for continual learning. We conduct a systematic study analyzing the learned feature representations and show that unsupervised visual representations are surprisingly more robust to catastrophic forgetting, consistently achieve better performance, and generalize better to out-of-distribution tasks than SCL. Furthermore, we find that UCL achieves a smoother loss landscape through qualitative analysis of the learned representations and learns meaningful feature representations. Additionally, we propose Lifelong Unsupervised Mixup (LUMP), a simple yet effective technique that leverages the interpolation between the current task and previous tasks' instances to alleviate catastrophic forgetting for unsupervised representations.
Online Coreset Selection for Rehearsal-based Continual Learning
Jun 02, 2021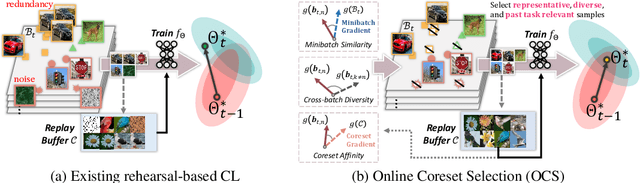
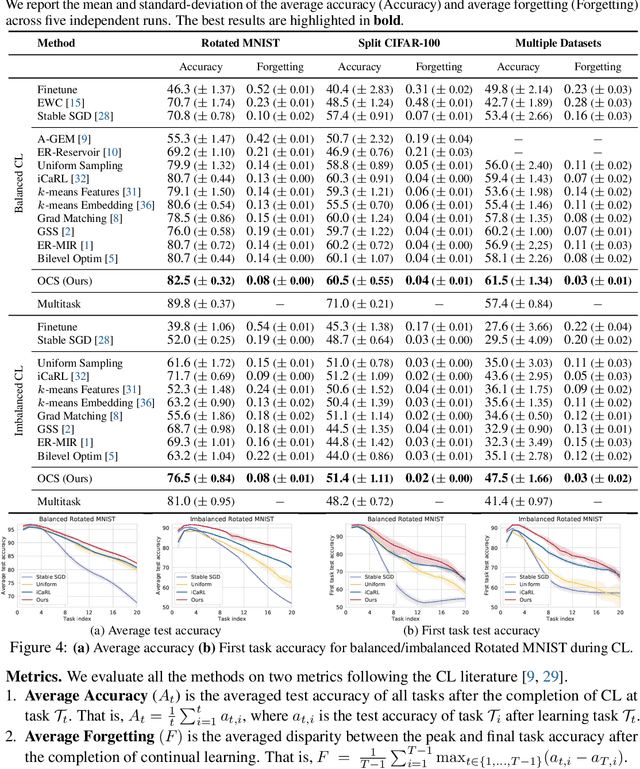

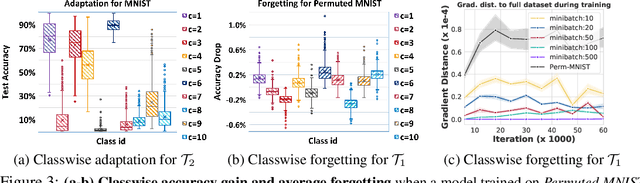
A dataset is a shred of crucial evidence to describe a task. However, each data point in the dataset does not have the same potential, as some of the data points can be more representative or informative than others. This unequal importance among the data points may have a large impact in rehearsal-based continual learning, where we store a subset of the training examples (coreset) to be replayed later to alleviate catastrophic forgetting. In continual learning, the quality of the samples stored in the coreset directly affects the model's effectiveness and efficiency. The coreset selection problem becomes even more important under realistic settings, such as imbalanced continual learning or noisy data scenarios. To tackle this problem, we propose Online Coreset Selection (OCS), a simple yet effective method that selects the most representative and informative coreset at each iteration and trains them in an online manner. Our proposed method maximizes the model's adaptation to a target dataset while selecting high-affinity samples to past tasks, which directly inhibits catastrophic forgetting. We validate the effectiveness of our coreset selection mechanism over various standard, imbalanced, and noisy datasets against strong continual learning baselines, demonstrating that it improves task adaptation and prevents catastrophic forgetting in a sample-efficient manner.
Learning to Generate Noise for Robustness against Multiple Perturbations
Jun 22, 2020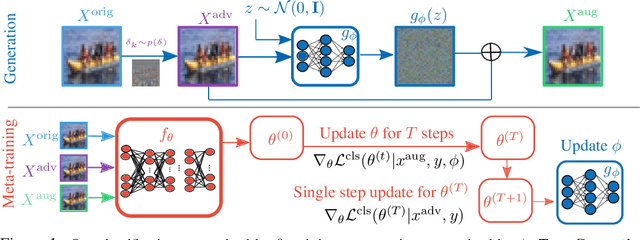
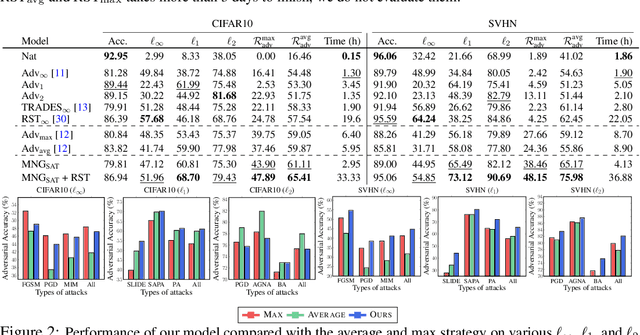
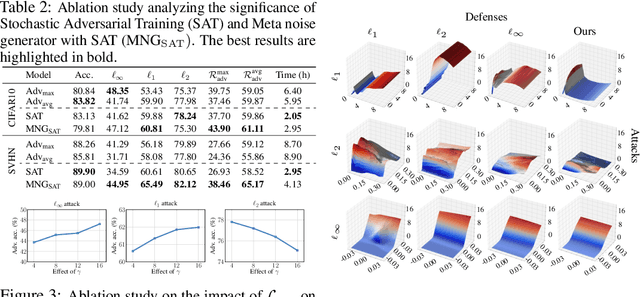

Adversarial learning has emerged as one of the successful techniques to circumvent the susceptibility of existing methods against adversarial perturbations. However, the majority of existing defense methods are tailored to defend against a single category of adversarial perturbation (e.g. $\ell_\infty$-attack). In safety-critical applications, this makes these methods extraneous as the attacker can adopt diverse adversaries to deceive the system. To tackle this challenge of robustness against multiple perturbations, we propose a novel meta-learning framework that explicitly learns to generate noise to improve the model's robustness against multiple types of attacks. Specifically, we propose Meta Noise Generator (MNG) that outputs optimal noise to stochastically perturb a given sample, such that it helps lower the error on diverse adversarial perturbations. However, training on multiple perturbations simultaneously significantly increases the computational overhead during training. To address this issue, we train our MNG while randomly sampling an attack at each epoch, which incurs negligible overhead over standard adversarial training. We validate the robustness of our framework on various datasets and against a wide variety of unseen perturbations, demonstrating that it significantly outperforms the relevant baselines across multiple perturbations with marginal computational cost compared to the multiple perturbations training.