 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePositional Description Matters for Transformers Arithmetic
Nov 22, 2023Transformers, central to the successes in modern Natural Language Processing, often falter on arithmetic tasks despite their vast capabilities --which paradoxically include remarkable coding abilities. We observe that a crucial challenge is their naive reliance on positional information to solve arithmetic problems with a small number of digits, leading to poor performance on larger numbers. Herein, we delve deeper into the role of positional encoding, and propose several ways to fix the issue, either by modifying the positional encoding directly, or by modifying the representation of the arithmetic task to leverage standard positional encoding differently. We investigate the value of these modifications for three tasks: (i) classical multiplication, (ii) length extrapolation in addition, and (iii) addition in natural language context. For (i) we train a small model on a small dataset (100M parameters and 300k samples) with remarkable aptitude in (direct, no scratchpad) 15 digits multiplication and essentially perfect up to 12 digits, while usual training in this context would give a model failing at 4 digits multiplication. In the experiments on addition, we use a mere 120k samples to demonstrate: for (ii) extrapolation from 10 digits to testing on 12 digits numbers while usual training would have no extrapolation, and for (iii) almost perfect accuracy up to 5 digits while usual training would be correct only up to 3 digits (which is essentially memorization with a training set of 120k samples).
FiLM: Fill-in Language Models for Any-Order Generation
Oct 15, 2023



Language models have become the backbone of today's AI systems. However, their predominant left-to-right generation limits the use of bidirectional context, which is essential for tasks that involve filling text in the middle. We propose the Fill-in Language Model (FiLM), a new language modeling approach that allows for flexible generation at any position without adhering to a specific generation order. Its training extends the masked language modeling objective by adopting varying mask probabilities sampled from the Beta distribution to enhance the generative capabilities of FiLM. During inference, FiLM can seamlessly insert missing phrases, sentences, or paragraphs, ensuring that the outputs are fluent and are coherent with the surrounding context. In both automatic and human evaluations, FiLM outperforms existing infilling methods that rely on left-to-right language models trained on rearranged text segments. FiLM is easy to implement and can be either trained from scratch or fine-tuned from a left-to-right language model. Notably, as the model size grows, FiLM's perplexity approaches that of strong left-to-right language models of similar sizes, indicating FiLM's scalability and potential as a large language model.
Algorithmic Aspects of the Log-Laplace Transform and a Non-Euclidean Proximal Sampler
Feb 22, 2023The development of efficient sampling algorithms catering to non-Euclidean geometries has been a challenging endeavor, as discretization techniques which succeed in the Euclidean setting do not readily carry over to more general settings. We develop a non-Euclidean analog of the recent proximal sampler of [LST21], which naturally induces regularization by an object known as the log-Laplace transform (LLT) of a density. We prove new mathematical properties (with an algorithmic flavor) of the LLT, such as strong convexity-smoothness duality and an isoperimetric inequality, which are used to prove a mixing time on our proximal sampler matching [LST21] under a warm start. As our main application, we show our warm-started sampler improves the value oracle complexity of differentially private convex optimization in $\ell_p$ and Schatten-$p$ norms for $p \in [1, 2]$ to match the Euclidean setting [GLL22], while retaining state-of-the-art excess risk bounds [GLLST23]. We find our investigation of the LLT to be a promising proof-of-concept of its utility as a tool for designing samplers, and outline directions for future exploration.
How to Fine-Tune Vision Models with SGD
Nov 17, 2022SGD (with momentum) and AdamW are the two most used optimizers for fine-tuning large neural networks in computer vision. When the two methods perform the same, SGD is preferable because it uses less memory (12 bytes/parameter) than AdamW (16 bytes/parameter). However, on a suite of downstream tasks, especially those with distribution shifts, we show that fine-tuning with AdamW performs substantially better than SGD on modern Vision Transformer and ConvNeXt models. We find that large gaps in performance between SGD and AdamW occur when the fine-tuning gradients in the first "embedding" layer are much larger than in the rest of the model. Our analysis suggests an easy fix that works consistently across datasets and models: merely freezing the embedding layer (less than 1\% of the parameters) leads to SGD performing competitively with AdamW while using less memory. Our insights result in state-of-the-art accuracies on five popular distribution shift benchmarks: WILDS-FMoW, WILDS-Camelyon, Living-17, Waterbirds, and DomainNet.
Condition-number-independent Convergence Rate of Riemannian Hamiltonian Monte Carlo with Numerical Integrators
Oct 13, 2022
We study the convergence rate of discretized Riemannian Hamiltonian Monte Carlo on sampling from distributions in the form of $e^{-f(x)}$ on a convex set $\mathcal{M}\subset\mathbb{R}^{n}$. We show that for distributions in the form of $e^{-\alpha^{\top}x}$ on a polytope with $m$ constraints, the convergence rate of a family of commonly-used integrators is independent of $\left\Vert \alpha\right\Vert_2$ and the geometry of the polytope. In particular, the Implicit Midpoint Method (IMM) and the generalized Leapfrog integrator (LM) have a mixing time of $\widetilde{O}\left(mn^{3}\right)$ to achieve $\epsilon$ total variation distance to the target distribution. These guarantees are based on a general bound on the convergence rate for densities of the form $e^{-f(x)}$ in terms of parameters of the manifold and the integrator. Our theoretical guarantee complements the empirical results of [KLSV22], which shows that RHMC with IMM can sample ill-conditioned, non-smooth and constrained distributions in very high dimension efficiently in practice.
Private Convex Optimization in General Norms
Jul 18, 2022
We propose a new framework for differentially private optimization of convex functions which are Lipschitz in an arbitrary norm $\normx{\cdot}$. Our algorithms are based on a regularized exponential mechanism which samples from the density $\propto \exp(-k(F+\mu r))$ where $F$ is the empirical loss and $r$ is a regularizer which is strongly convex with respect to $\normx{\cdot}$, generalizing a recent work of \cite{GLL22} to non-Euclidean settings. We show that this mechanism satisfies Gaussian differential privacy and solves both DP-ERM (empirical risk minimization) and DP-SCO (stochastic convex optimization), by using localization tools from convex geometry. Our framework is the first to apply to private convex optimization in general normed spaces, and directly recovers non-private SCO rates achieved by mirror descent, as the privacy parameter $\eps \to \infty$. As applications, for Lipschitz optimization in $\ell_p$ norms for all $p \in (1, 2)$, we obtain the first optimal privacy-utility tradeoffs; for $p = 1$, we improve tradeoffs obtained by the recent works \cite{AsiFKT21, BassilyGN21} by at least a logarithmic factor. Our $\ell_p$ norm and Schatten-$p$ norm optimization frameworks are complemented with polynomial-time samplers whose query complexity we explicitly bound.
Data Augmentation as Feature Manipulation: a story of desert cows and grass cows
Mar 03, 2022
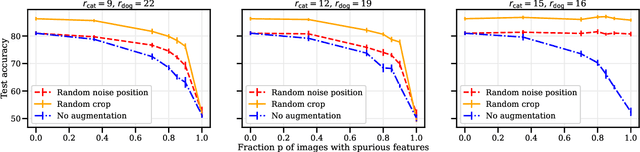
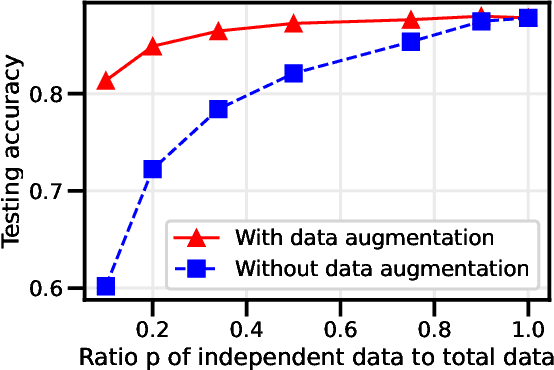
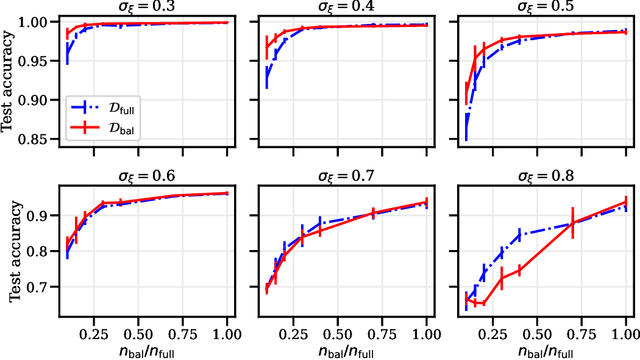
Data augmentation is a cornerstone of the machine learning pipeline, yet its theoretical underpinnings remain unclear. Is it merely a way to artificially augment the data set size? Or is it about encouraging the model to satisfy certain invariance? In this work we consider another angle, and we study the effect of data augmentation on the dynamic of the learning process. We find that data augmentation can alter the relative importance of various features, effectively making certain informative but hard to learn features more likely to be captured in the learning process. Importantly, we show that this effect is more pronounced for non-linear models, such as neural networks. Our main contribution is a detailed analysis of data augmentation on the learning dynamic for a two layer convolutional neural network in the recently proposed multi-view model by Allen-Zhu and Li [2020]. We complement this analysis with further experimental evidence that data augmentation can be viewed as a form of feature manipulation.
On Optimal Early Stopping: Over-informative versus Under-informative Parametrization
Feb 23, 2022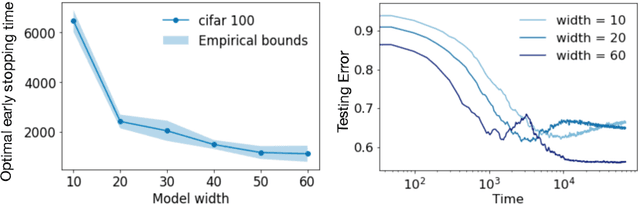
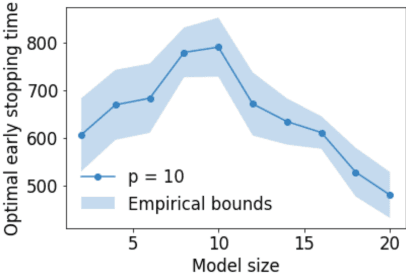
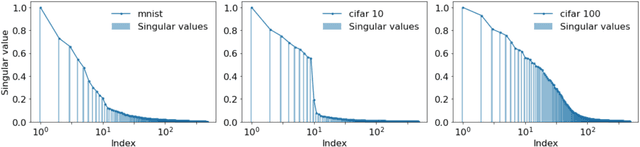
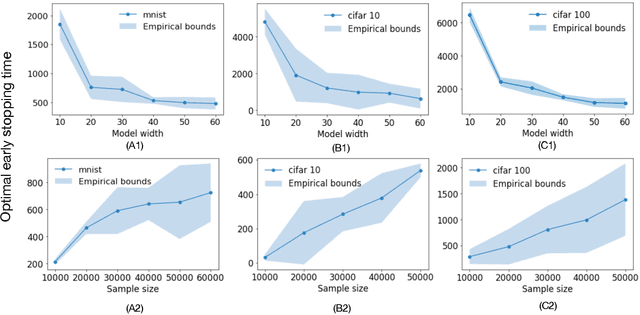
Early stopping is a simple and widely used method to prevent over-training neural networks. We develop theoretical results to reveal the relationship between the optimal early stopping time and model dimension as well as sample size of the dataset for certain linear models. Our results demonstrate two very different behaviors when the model dimension exceeds the number of features versus the opposite scenario. While most previous works on linear models focus on the latter setting, we observe that the dimension of the model often exceeds the number of features arising from data in common deep learning tasks and propose a model to study this setting. We demonstrate experimentally that our theoretical results on optimal early stopping time corresponds to the training process of deep neural networks.
Sampling with Riemannian Hamiltonian Monte Carlo in a Constrained Space
Feb 03, 2022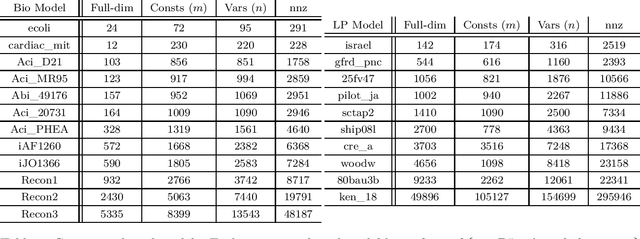
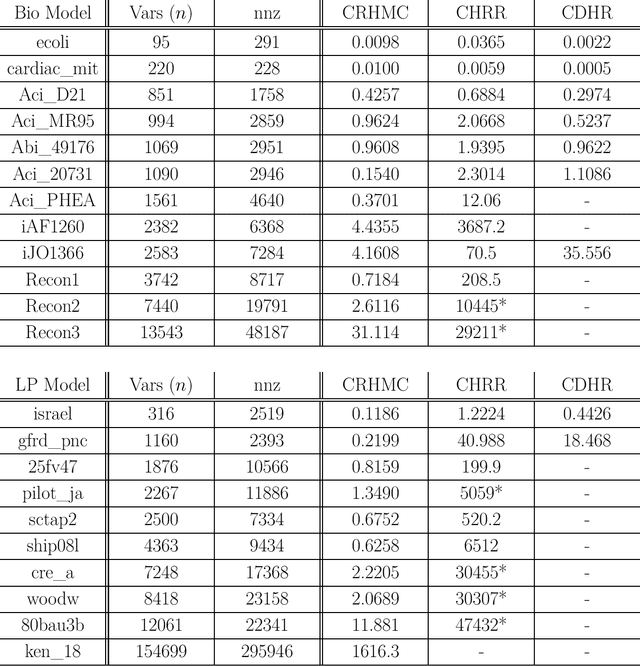
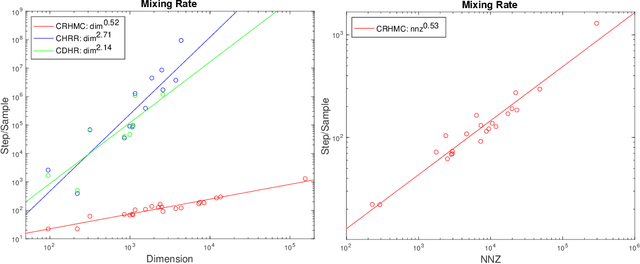

We demonstrate for the first time that ill-conditioned, non-smooth, constrained distributions in very high dimension, upwards of 100,000, can be sampled efficiently $\textit{in practice}$. Our algorithm incorporates constraints into the Riemannian version of Hamiltonian Monte Carlo and maintains sparsity. This allows us to achieve a mixing rate independent of smoothness and condition numbers. On benchmark data sets in systems biology and linear programming, our algorithm outperforms existing packages by orders of magnitude. In particular, we achieve a 1,000-fold speed-up for sampling from the largest published human metabolic network (RECON3D). Our package has been incorporated into the COBRA toolbox.
Analysis of Langevin Monte Carlo from Poincaré to Log-Sobolev
Dec 23, 2021

Classically, the continuous-time Langevin diffusion converges exponentially fast to its stationary distribution $\pi$ under the sole assumption that $\pi$ satisfies a Poincar\'e inequality. Using this fact to provide guarantees for the discrete-time Langevin Monte Carlo (LMC) algorithm, however, is considerably more challenging due to the need for working with chi-squared or R\'enyi divergences, and prior works have largely focused on strongly log-concave targets. In this work, we provide the first convergence guarantees for LMC assuming that $\pi$ satisfies either a Lata{\l}a--Oleszkiewicz or modified log-Sobolev inequality, which interpolates between the Poincar\'e and log-Sobolev settings. Unlike prior works, our results allow for weak smoothness and do not require convexity or dissipativity conditions.