 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Geometry of Efficient Nonconvex Sampling
Mar 26, 2026We present an efficient algorithm for uniformly sampling from an arbitrary compact body $\mathcal{X} \subset \mathbb{R}^n$ from a warm start under isoperimetry and a natural volume growth condition. Our result provides a substantial common generalization of known results for convex bodies and star-shaped bodies. The complexity of the algorithm is polynomial in the dimension, the Poincaré constant of the uniform distribution on $\mathcal{X}$ and the volume growth constant of the set $\mathcal{X}$.
Provable Long-Range Benefits of Next-Token Prediction
Dec 08, 2025Why do modern language models, trained to do well on next-word prediction, appear to generate coherent documents and capture long-range structure? Here we show that next-token prediction is provably powerful for learning longer-range structure, even with common neural network architectures. Specifically, we prove that optimizing next-token prediction over a Recurrent Neural Network (RNN) yields a model that closely approximates the training distribution: for held-out documents sampled from the training distribution, no algorithm of bounded description length limited to examining the next $k$ tokens, for any $k$, can distinguish between $k$ consecutive tokens of such documents and $k$ tokens generated by the learned language model following the same prefix. We provide polynomial bounds (in $k$, independent of the document length) on the model size needed to achieve such $k$-token indistinguishability, offering a complexity-theoretic explanation for the long-range coherence observed in practice.
Why Language Models Hallucinate
Sep 04, 2025

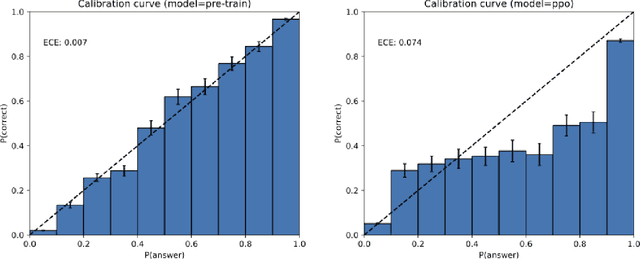
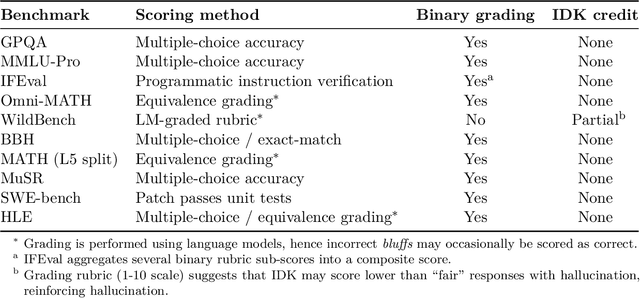
Like students facing hard exam questions, large language models sometimes guess when uncertain, producing plausible yet incorrect statements instead of admitting uncertainty. Such "hallucinations" persist even in state-of-the-art systems and undermine trust. We argue that language models hallucinate because the training and evaluation procedures reward guessing over acknowledging uncertainty, and we analyze the statistical causes of hallucinations in the modern training pipeline. Hallucinations need not be mysterious -- they originate simply as errors in binary classification. If incorrect statements cannot be distinguished from facts, then hallucinations in pretrained language models will arise through natural statistical pressures. We then argue that hallucinations persist due to the way most evaluations are graded -- language models are optimized to be good test-takers, and guessing when uncertain improves test performance. This "epidemic" of penalizing uncertain responses can only be addressed through a socio-technical mitigation: modifying the scoring of existing benchmarks that are misaligned but dominate leaderboards, rather than introducing additional hallucination evaluations. This change may steer the field toward more trustworthy AI systems.
Faster logconcave sampling from a cold start in high dimension
May 03, 2025We present a faster algorithm to generate a warm start for sampling an arbitrary logconcave density specified by an evaluation oracle, leading to the first sub-cubic sampling algorithms for inputs in (near-)isotropic position. A long line of prior work incurred a warm-start penalty of at least linear in the dimension, hitting a cubic barrier, even for the special case of uniform sampling from convex bodies. Our improvement relies on two key ingredients of independent interest. (1) We show how to sample given a warm start in weaker notions of distance, in particular $q$-R\'enyi divergence for $q=\widetilde{\mathcal{O}}(1)$, whereas previous analyses required stringent $\infty$-R\'enyi divergence (with the exception of Hit-and-Run, whose known mixing time is higher). This marks the first improvement in the required warmness since Lov\'asz and Simonovits (1991). (2) We refine and generalize the log-Sobolev inequality of Lee and Vempala (2018), originally established for isotropic logconcave distributions in terms of the diameter of the support, to logconcave distributions in terms of a geometric average of the support diameter and the largest eigenvalue of the covariance matrix.
Sampling and Integration of Logconcave Functions by Algorithmic Diffusion
Nov 20, 2024
We study the complexity of sampling, rounding, and integrating arbitrary logconcave functions. Our new approach provides the first complexity improvements in nearly two decades for general logconcave functions for all three problems, and matches the best-known complexities for the special case of uniform distributions on convex bodies. For the sampling problem, our output guarantees are significantly stronger than previously known, and lead to a streamlined analysis of statistical estimation based on dependent random samples.
Does GPT Really Get It? A Hierarchical Scale to Quantify Human vs AI's Understanding of Algorithms
Jun 20, 2024



As Large Language Models (LLMs) perform (and sometimes excel at) more and more complex cognitive tasks, a natural question is whether AI really understands. The study of understanding in LLMs is in its infancy, and the community has yet to incorporate well-trodden research in philosophy, psychology, and education. We initiate this, specifically focusing on understanding algorithms, and propose a hierarchy of levels of understanding. We use the hierarchy to design and conduct a study with human subjects (undergraduate and graduate students) as well as large language models (generations of GPT), revealing interesting similarities and differences. We expect that our rigorous criteria will be useful to keep track of AI's progress in such cognitive domains.
Coin-Flipping In The Brain: Statistical Learning with Neuronal Assemblies
Jun 11, 2024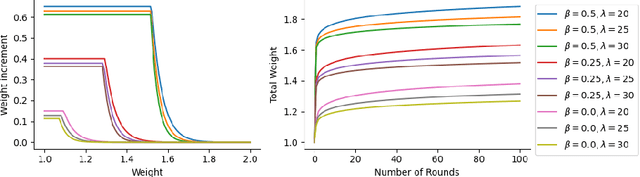


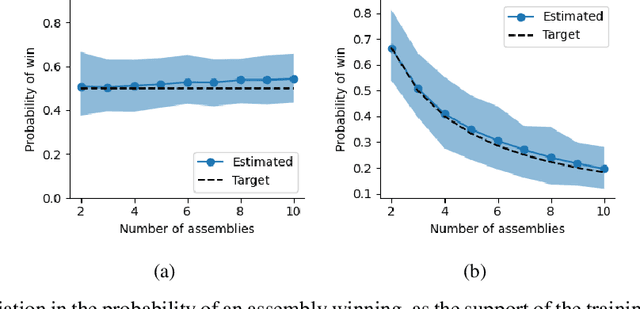
How intelligence arises from the brain is a central problem in science. A crucial aspect of intelligence is dealing with uncertainty -- developing good predictions about one's environment, and converting these predictions into decisions. The brain itself seems to be noisy at many levels, from chemical processes which drive development and neuronal activity to trial variability of responses to stimuli. One hypothesis is that the noise inherent to the brain's mechanisms is used to sample from a model of the world and generate predictions. To test this hypothesis, we study the emergence of statistical learning in NEMO, a biologically plausible computational model of the brain based on stylized neurons and synapses, plasticity, and inhibition, and giving rise to assemblies -- a group of neurons whose coordinated firing is tantamount to recalling a location, concept, memory, or other primitive item of cognition. We show in theory and simulation that connections between assemblies record statistics, and ambient noise can be harnessed to make probabilistic choices between assemblies. This allows NEMO to create internal models such as Markov chains entirely from the presentation of sequences of stimuli. Our results provide a foundation for biologically plausible probabilistic computation, and add theoretical support to the hypothesis that noise is a useful component of the brain's mechanism for cognition.
In-and-Out: Algorithmic Diffusion for Sampling Convex Bodies
May 02, 2024

We present a new random walk for uniformly sampling high-dimensional convex bodies. It achieves state-of-the-art runtime complexity with stronger guarantees on the output than previously known, namely in R\'enyi divergence (which implies TV, $\mathcal{W}_2$, KL, $\chi^2$). The proof departs from known approaches for polytime algorithms for the problem -- we utilize a stochastic diffusion perspective to show contraction to the target distribution with the rate of convergence determined by functional isoperimetric constants of the stationary density.
Calibrated Language Models Must Hallucinate
Dec 03, 2023

Recent language models generate false but plausible-sounding text with surprising frequency. Such "hallucinations" are an obstacle to the usability of language-based AI systems and can harm people who rely upon their outputs. This work shows shows that there is an inherent statistical lower-bound on the rate that pretrained language models hallucinate certain types of facts, having nothing to do with the transformer LM architecture or data quality. For "arbitrary" facts whose veracity cannot be determined from the training data, we show that hallucinations must occur at a certain rate for language models that satisfy a statistical calibration condition appropriate for generative language models. Specifically, if the maximum probability of any fact is bounded, we show that the probability of generating a hallucination is close to the fraction of facts that occur exactly once in the training data (a "Good-Turing" estimate), even assuming ideal training data without errors. One conclusion is that models pretrained to be sufficiently good predictors (i.e., calibrated) may require post-training to mitigate hallucinations on the type of arbitrary facts that tend to appear once in the training set. However, our analysis also suggests that there is no statistical reason that pretraining will lead to hallucination on facts that tend to appear more than once in the training data (like references to publications such as articles and books, whose hallucinations have been particularly notable and problematic) or on systematic facts (like arithmetic calculations). Therefore, different architectures and learning algorithms may mitigate these latter types of hallucinations.
Contrastive Moments: Unsupervised Halfspace Learning in Polynomial Time
Nov 02, 2023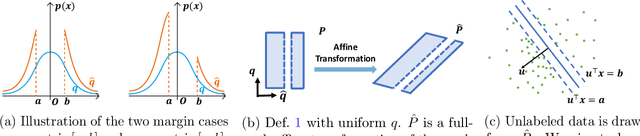
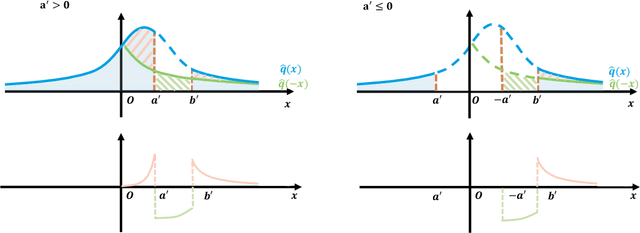
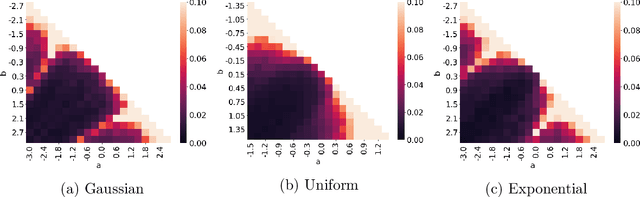
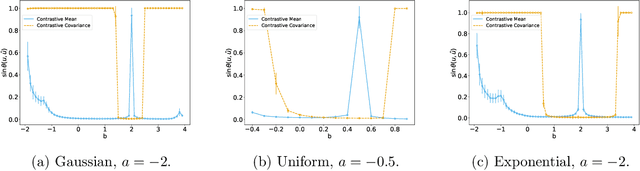
We give a polynomial-time algorithm for learning high-dimensional halfspaces with margins in $d$-dimensional space to within desired TV distance when the ambient distribution is an unknown affine transformation of the $d$-fold product of an (unknown) symmetric one-dimensional logconcave distribution, and the halfspace is introduced by deleting at least an $\epsilon$ fraction of the data in one of the component distributions. Notably, our algorithm does not need labels and establishes the unique (and efficient) identifiability of the hidden halfspace under this distributional assumption. The sample and time complexity of the algorithm are polynomial in the dimension and $1/\epsilon$. The algorithm uses only the first two moments of suitable re-weightings of the empirical distribution, which we call contrastive moments; its analysis uses classical facts about generalized Dirichlet polynomials and relies crucially on a new monotonicity property of the moment ratio of truncations of logconcave distributions. Such algorithms, based only on first and second moments were suggested in earlier work, but hitherto eluded rigorous guarantees. Prior work addressed the special case when the underlying distribution is Gaussian via Non-Gaussian Component Analysis. We improve on this by providing polytime guarantees based on Total Variation (TV) distance, in place of existing moment-bound guarantees that can be super-polynomial. Our work is also the first to go beyond Gaussians in this setting.