 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Decision Deferral under Budget Constraints
Sep 30, 2024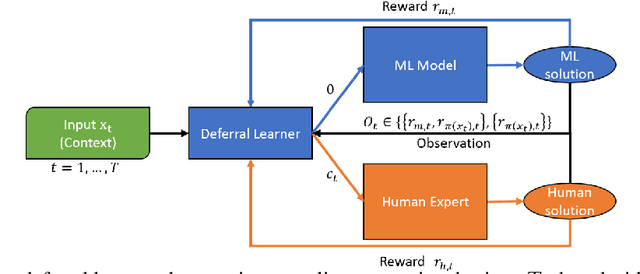
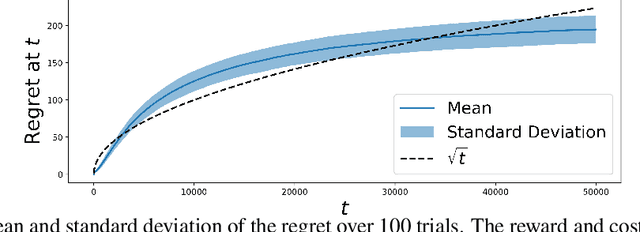
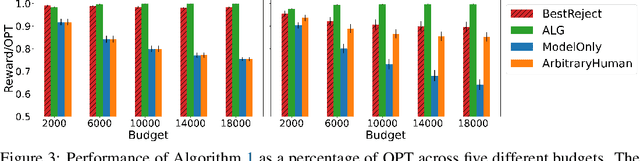
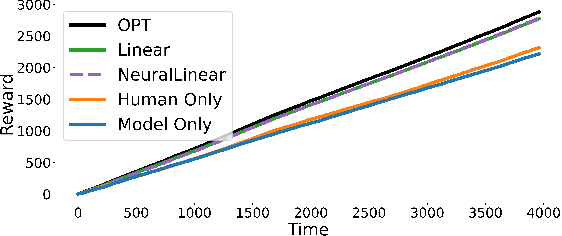
Machine Learning (ML) models are increasingly used to support or substitute decision making. In applications where skilled experts are a limited resource, it is crucial to reduce their burden and automate decisions when the performance of an ML model is at least of equal quality. However, models are often pre-trained and fixed, while tasks arrive sequentially and their distribution may shift. In that case, the respective performance of the decision makers may change, and the deferral algorithm must remain adaptive. We propose a contextual bandit model of this online decision making problem. Our framework includes budget constraints and different types of partial feedback models. Beyond the theoretical guarantees of our algorithm, we propose efficient extensions that achieve remarkable performance on real-world datasets.
Improving Radiography Machine Learning Workflows via Metadata Management for Training Data Selection
Aug 22, 2024Most machine learning models require many iterations of hyper-parameter tuning, feature engineering, and debugging to produce effective results. As machine learning models become more complicated, this pipeline becomes more difficult to manage effectively. In the physical sciences, there is an ever-increasing pool of metadata that is generated by the scientific research cycle. Tracking this metadata can reduce redundant work, improve reproducibility, and aid in the feature and training dataset engineering process. In this case study, we present a tool for machine learning metadata management in dynamic radiography. We evaluate the efficacy of this tool against the initial research workflow and discuss extensions to general machine learning pipelines in the physical sciences.
Does GPT Really Get It? A Hierarchical Scale to Quantify Human vs AI's Understanding of Algorithms
Jun 20, 2024



As Large Language Models (LLMs) perform (and sometimes excel at) more and more complex cognitive tasks, a natural question is whether AI really understands. The study of understanding in LLMs is in its infancy, and the community has yet to incorporate well-trodden research in philosophy, psychology, and education. We initiate this, specifically focusing on understanding algorithms, and propose a hierarchy of levels of understanding. We use the hierarchy to design and conduct a study with human subjects (undergraduate and graduate students) as well as large language models (generations of GPT), revealing interesting similarities and differences. We expect that our rigorous criteria will be useful to keep track of AI's progress in such cognitive domains.