 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinuous Latent Contexts Enable Efficient Online Learning in Transformers
May 11, 2026Large language models (LLMs) exhibit a strong capacity for in-context learning: Given labeled examples, they can generate good predictions without parameter updates. However, many interactive settings go beyond static prediction to online decision-making, in which effective behavior demands adaptation over long multi-turn horizons in response to feedback, and efficient algorithms in these domains must use compact representations of what they have learned. Recently, continuous transformer architectures with latent chain of thought have shown promise for offline iterative tasks such as directed graph-reachability. Motivated by this, we study whether continuous latent context tokens equip transformers to more effectively realize online learning. We give explicit constructions of constant-depth transformers that implement two foundational online decision-making procedures -- the weighted majority algorithm and $Q$-learning -- by storing their algorithmic state as linear combinations of feature embeddings, using a small number of latent context tokens. We further train a small GPT-2-style transformer with latent contexts using a multi-curriculum objective that does not directly supervise the latent states. On long synthetic online prediction sequences, this model outperforms larger and more complex LLMs, including Qwen-3-14B and DeepSeek-V3. Our results suggest that continuous latent contexts provide a simple and effective persistent state for transformers to implement online learning algorithms.
Coin-Flipping In The Brain: Statistical Learning with Neuronal Assemblies
Jun 11, 2024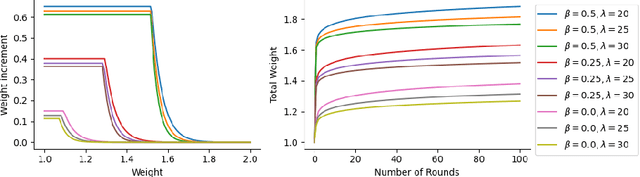


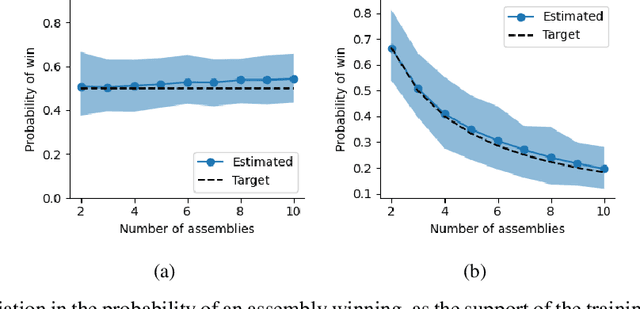
How intelligence arises from the brain is a central problem in science. A crucial aspect of intelligence is dealing with uncertainty -- developing good predictions about one's environment, and converting these predictions into decisions. The brain itself seems to be noisy at many levels, from chemical processes which drive development and neuronal activity to trial variability of responses to stimuli. One hypothesis is that the noise inherent to the brain's mechanisms is used to sample from a model of the world and generate predictions. To test this hypothesis, we study the emergence of statistical learning in NEMO, a biologically plausible computational model of the brain based on stylized neurons and synapses, plasticity, and inhibition, and giving rise to assemblies -- a group of neurons whose coordinated firing is tantamount to recalling a location, concept, memory, or other primitive item of cognition. We show in theory and simulation that connections between assemblies record statistics, and ambient noise can be harnessed to make probabilistic choices between assemblies. This allows NEMO to create internal models such as Markov chains entirely from the presentation of sequences of stimuli. Our results provide a foundation for biologically plausible probabilistic computation, and add theoretical support to the hypothesis that noise is a useful component of the brain's mechanism for cognition.
Computation with Sequences in the Brain
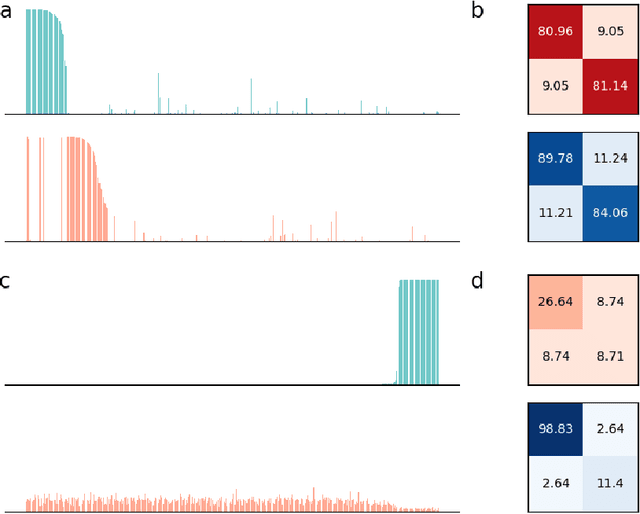
Jun 06, 2023Even as machine learning exceeds human-level performance on many applications, the generality, robustness, and rapidity of the brain's learning capabilities remain unmatched. How cognition arises from neural activity is a central open question in neuroscience, inextricable from the study of intelligence itself. A simple formal model of neural activity was proposed in Papadimitriou [2020] and has been subsequently shown, through both mathematical proofs and simulations, to be capable of implementing certain simple cognitive operations via the creation and manipulation of assemblies of neurons. However, many intelligent behaviors rely on the ability to recognize, store, and manipulate temporal sequences of stimuli (planning, language, navigation, to list a few). Here we show that, in the same model, time can be captured naturally as precedence through synaptic weights and plasticity, and, as a result, a range of computations on sequences of assemblies can be carried out. In particular, repeated presentation of a sequence of stimuli leads to the memorization of the sequence through corresponding neural assemblies: upon future presentation of any stimulus in the sequence, the corresponding assembly and its subsequent ones will be activated, one after the other, until the end of the sequence. Finally, we show that any finite state machine can be learned in a similar way, through the presentation of appropriate patterns of sequences. Through an extension of this mechanism, the model can be shown to be capable of universal computation. We support our analysis with a number of experiments to probe the limits of learning in this model in key ways. Taken together, these results provide a concrete hypothesis for the basis of the brain's remarkable abilities to compute and learn, with sequences playing a vital role.
Seeing the forest and the tree: Building representations of both individual and collective dynamics with transformers
Jun 10, 2022Complex time-varying systems are often studied by abstracting away from the dynamics of individual components to build a model of the population-level dynamics from the start. However, when building a population-level description, it can be easy to lose sight of each individual and how each contributes to the larger picture. In this paper, we present a novel transformer architecture for learning from time-varying data that builds descriptions of both the individual as well as the collective population dynamics. Rather than combining all of our data into our model at the onset, we develop a separable architecture that operates on individual time-series first before passing them forward; this induces a permutation-invariance property and can be used to transfer across systems of different size and order. After demonstrating that our model can be applied to successfully recover complex interactions and dynamics in many-body systems, we apply our approach to populations of neurons in the nervous system. On neural activity datasets, we show that our multi-scale transformer not only yields robust decoding performance, but also provides impressive performance in transfer. Our results show that it is possible to learn from neurons in one animal's brain and transfer the model on neurons in a different animal's brain, with interpretable neuron correspondence across sets and animals. This finding opens up a new path to decode from and represent large collections of neurons.
Drop, Swap, and Generate: A Self-Supervised Approach for Generating Neural Activity
Nov 03, 2021Meaningful and simplified representations of neural activity can yield insights into how and what information is being processed within a neural circuit. However, without labels, finding representations that reveal the link between the brain and behavior can be challenging. Here, we introduce a novel unsupervised approach for learning disentangled representations of neural activity called Swap-VAE. Our approach combines a generative modeling framework with an instance-specific alignment loss that tries to maximize the representational similarity between transformed views of the input (brain state). These transformed (or augmented) views are created by dropping out neurons and jittering samples in time, which intuitively should lead the network to a representation that maintains both temporal consistency and invariance to the specific neurons used to represent the neural state. Through evaluations on both synthetic data and neural recordings from hundreds of neurons in different primate brains, we show that it is possible to build representations that disentangle neural datasets along relevant latent dimensions linked to behavior.
Assemblies of neurons can learn to classify well-separated distributions
Oct 07, 2021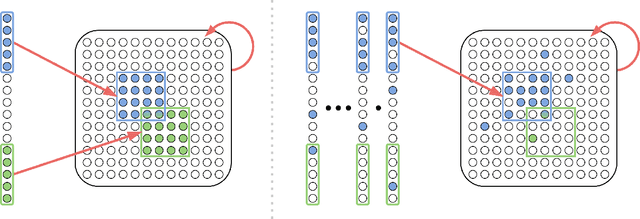

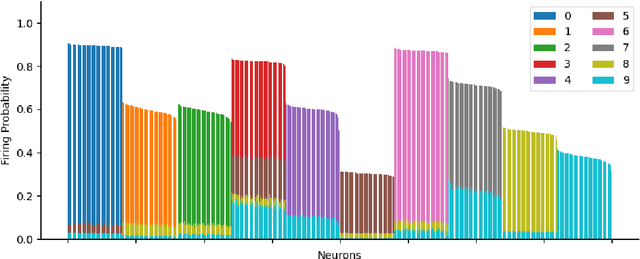
Assemblies are patterns of coordinated firing across large populations of neurons, believed to represent higher-level information in the brain, such as memories, concepts, words, and other cognitive categories. Recently, a computational system called the Assembly Calculus (AC) has been proposed, based on a set of biologically plausible operations on assemblies. This system is capable of simulating arbitrary space-bounded computation, and describes quite naturally complex cognitive phenomena such as language. However, the question of whether assemblies can perform the brain's greatest trick -- its ability to learn -- has been open. We show that the AC provides a mechanism for learning to classify samples from well-separated classes. We prove rigorously that for simple classification problems, a new assembly that represents each class can be reliably formed in response to a few stimuli from it; this assembly is henceforth reliably recalled in response to new stimuli from the same class. Furthermore, such class assemblies will be distinguishable as long as the respective classes are reasonably separated, in particular when they are clusters of similar assemblies, or more generally divided by a halfspace with margin. Experimentally, we demonstrate the successful formation of assemblies which represent concept classes on synthetic data drawn from these distributions, and also on MNIST, which lends itself to classification through one assembly per digit. Seen as a learning algorithm, this mechanism is entirely online, generalizes from very few samples, and requires only mild supervision -- all key attributes of learning in a model of the brain.
Mine Your Own vieW: Self-Supervised Learning Through Across-Sample Prediction
Feb 19, 2021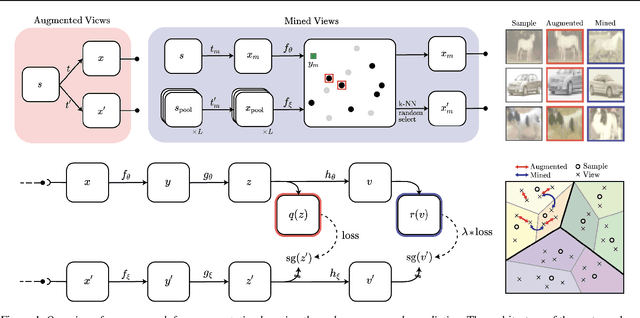
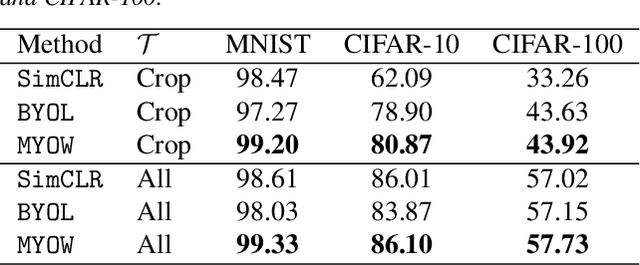
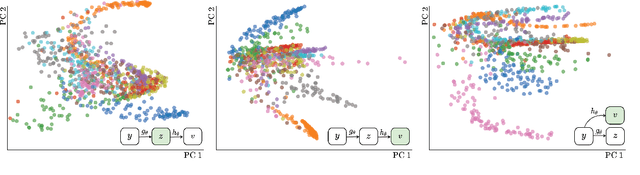
State-of-the-art methods for self-supervised learning (SSL) build representations by maximizing the similarity between different augmented "views" of a sample. Because these approaches try to match views of the same sample, they can be too myopic and fail to produce meaningful results when augmentations are not sufficiently rich. This motivates the use of the dataset itself to find similar, yet distinct, samples to serve as views for one another. In this paper, we introduce Mine Your Own vieW (MYOW), a new approach for building across-sample prediction into SSL. The idea behind our approach is to actively mine views, finding samples that are close in the representation space of the network, and then predict, from one sample's latent representation, the representation of a nearby sample. In addition to showing the promise of MYOW on standard datasets used in computer vision, we highlight the power of this idea in a novel application in neuroscience where rich augmentations are not already established. When applied to neural datasets, MYOW outperforms other self-supervised approaches in all examples (in some cases by more than 10%), and surpasses the supervised baseline for most datasets. By learning to predict the latent representation of similar samples, we show that it is possible to learn good representations in new domains where augmentations are still limited.
Hierarchical Optimal Transport for Multimodal Distribution Alignment
Jun 27, 2019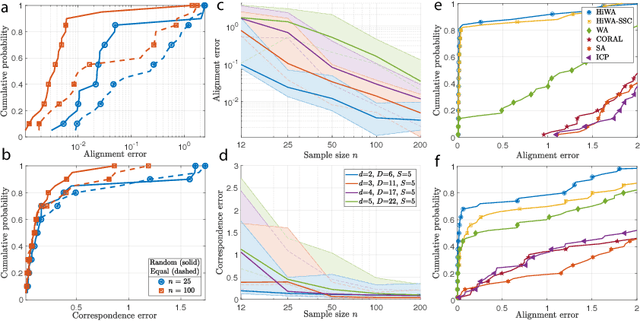
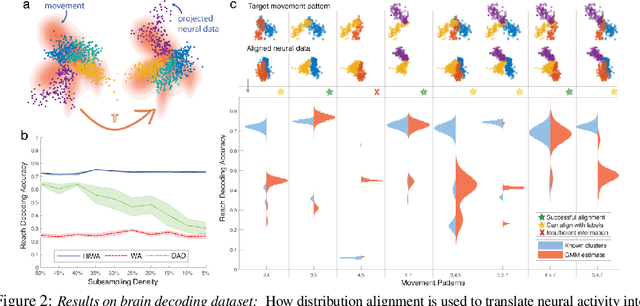
In many machine learning applications, it is necessary to meaningfully aggregate, through alignment, different but related datasets. Optimal transport (OT)-based approaches pose alignment as a divergence minimization problem: the aim is to transform a source dataset to match a target dataset using the Wasserstein distance as a divergence measure. We introduce a hierarchical formulation of OT which leverages clustered structure in data to improve alignment in noisy, ambiguous, or multimodal settings. To solve this numerically, we propose a distributed ADMM algorithm that also exploits the Sinkhorn distance, thus it has an efficient computational complexity that scales quadratically with the size of the largest cluster. When the transformation between two datasets is unitary, we provide performance guarantees that describe when and how well aligned cluster correspondences can be recovered with our formulation, as well as provide worst-case dataset geometry for such a strategy. We apply this method to synthetic datasets that model data as mixtures of low-rank Gaussians and study the impact that different geometric properties of the data have on alignment. Next, we applied our approach to a neural decoding application where the goal is to predict movement directions and instantaneous velocities from populations of neurons in the macaque primary motor cortex. Our results demonstrate that when clustered structure exists in datasets, and is consistent across trials or time points, a hierarchical alignment strategy that leverages such structure can provide significant improvements in cross-domain alignment.